Ext4
Немного истории: ext2 и ext3
Первые две версии - ext2 и ext3 - имеют одинаковые базовые структуры.
ext3 обратно совместима с ext2, т.е. как ext2 может быть сконвертирована в ext3, так и наоборот, и все это без потери данных.
Обе эти системы поддерживают размер блока в 1, 2 и 4 килобайта. Блоки организуются в блоковые группы, все группы (кроме последней)
имеют одинаковое число блоков и нод. Нода хранит метаданные. Максимальное число файлов ограничено и задается при форматировании.
Суперблок - структура, хранящая метаданные о всей файловой системе: общее число блоков и нод в системе,
число блоков в группе, число свободных блоков в файловой системе.
Групповые дескрипторы хранят метаданные о конкретной блоковой группе: число нод и блоков в группе,
В каждой блоковой группе имеются два специальных битовых блока - один для нод и второй для блоков.
Они ограничивают число нод и блоков для данной группы. Поскольку максимально возможный размер блока - 4 килобайта,
максимально возможное число нод и блоков в группе - 2 в 15-й степени, или 32 килобайта.
В обоих битовых блоках 1 используется для занятого обьекта и 0 для свободного.
Размер ноды по умолчанию и в ext2, и в ext3 одинаков и равен 128 байтам. Ноды хранятся последовательно подряд сразу за битовыми блоками.
Блоки, которые заняты нодами, называются нодовой таблицей. Размер этой таблицы зависит от размера блока.
Для 4-килобайтного блока число нод равно 32 килобайтам. Каждый блок может хранить по 32 ноды, итого получаем 1024 блоков под
нодовую таблицу в данном случае.
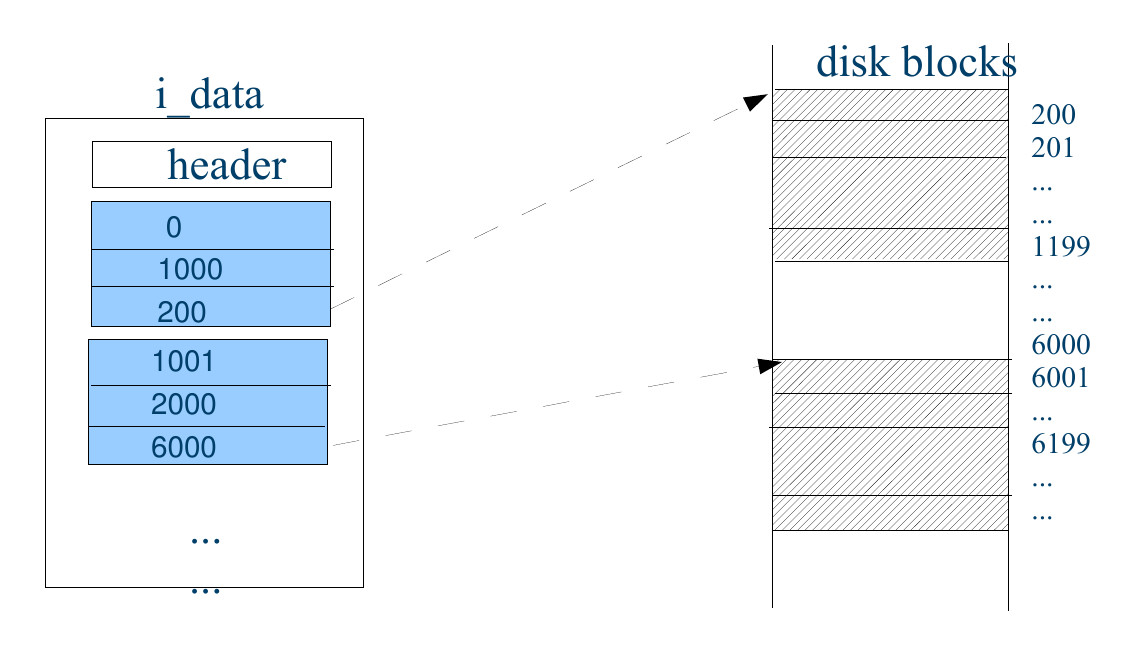
Обе этих файловых системы используют одинаковую систему указателей на блоки данных, которые делятся на прямые,
косвенные, двойные косвенные и тройные косвенные указатели
При удалении файла поведение ext2 и ext3 различается. ext2 при удалении файла маркирует ноду удаленного файла как свободную
с помощью битовых таблиц. Сама нода при этом не модифицируется, что дает возможность позже восстановить удаленны файл, если
он не был перезаписан. ext3 дополнительно модифицирует указатели на блоки данных в самой ноде, что затрудняет
последующее восстановление удаленного файла.
В ext3 появилось журналирование. Журнал - это лог, в котором сохраняется история изменения файла.
Процессом журналирования в ext3 управляет специальное системное устройство, называемое Journal Block Device.
Сама ext3 управляет транзакциями, которые передаются в это устройство. Транзакция - это набор апдэйтов, или изменений.
Есть специальный дескрипторный блок, в котором хранится список блоков файловой системы, участвующих в транзакции.
Есть также специальный commit блок, который создается файловой системой в момент сброса данных на диск.
Есть также специальный блок отката - revoke блок, который устроен аналогично дескрипторному блоку.
Есть также специальный журнальный суперблок - JSB - Joutnal super block, который служит для управления вышеназванных
специальных журнальных блоков:
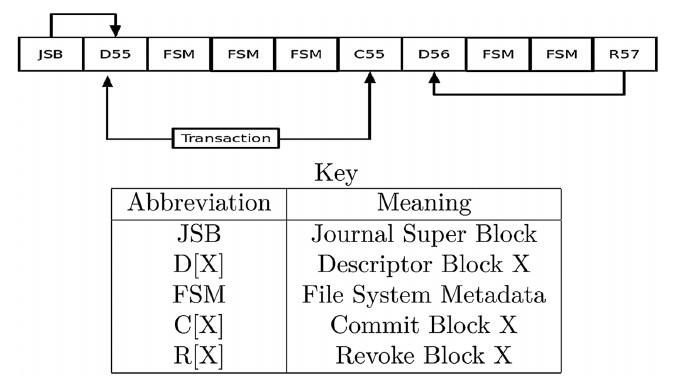
На рисунке представлены три транзакции - 55, 56, 57 - где 56-я незакомичена.
Журналирование в ext3 имеет 3 режима: 1. Journal 2. Ordered 3. Writeback.
Первый режим наиболее затратен. Он пишет и данные, и метаданные в журнал, а потом копирует их на диск.
Т.е. происходит полное дублирование записи данных. Для избежания этого дублирования второй режим в журнал пишет только метаданные.
Он установлен по умолчанию в большинстве дистрибутивов.
Индексация директорий, реализованная еще в 2002 году, стала умолчательной опцией только в ext4. ext2 и ext3 используют связные списки
для хранения директорий. Индексация реализована на основе т.н. htree, см. fs/ext4/namei.c.
Одной из важных структур в этом дереве является структура fake_dirent, и ее два экземпляра входят в другую структуру -
dx_root - для обозначения текущей (.) и корневой (..) директории. Каждая директория начинается со структуры dx_root,
в которой могут быть одна или несколько вложенных - dx_entry. Каждая такая dx_entry состоит из хеша и указателя на другой блок.
Максимальная глубина htree - 2 уровня. Когда число dx_entry возрастает так, что они уже не влезают в один блок,
создается еще одна индексная нода - dx_node. Указатель в dx_entry указывает на такую dx_node.
dx_node начинается с фэйковой директории.
ext4
В суперблоке ext4 появились 64-битные поля для расширения числа блоков. Изменилась организация блоковых групп:
появились т.н. мета-блоковые группы, каждая из которых обьединяет в себе несколько обычных блоковых групп:
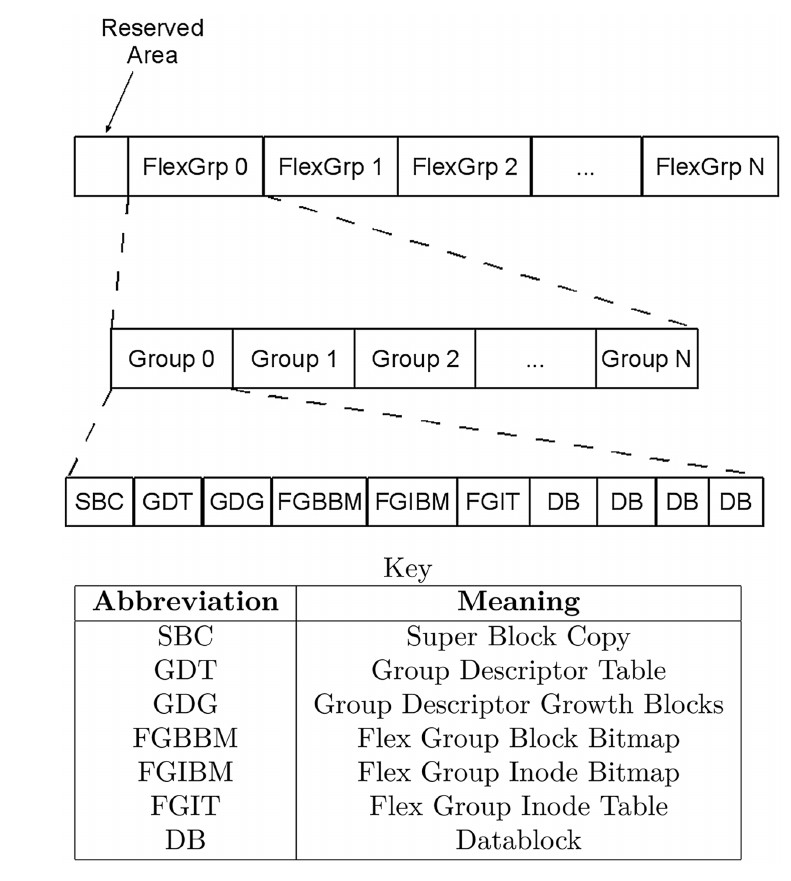
Такая мета-группа имеет единую нодовую и блоковую битмап-таблицу, а также единую таблицу нод.
Число блоковых групп внутри мета-группы должно быть кратно двум. Максимальный размер блоковой группы в 128 метров для ext3
здесь может быть легко преодолен.
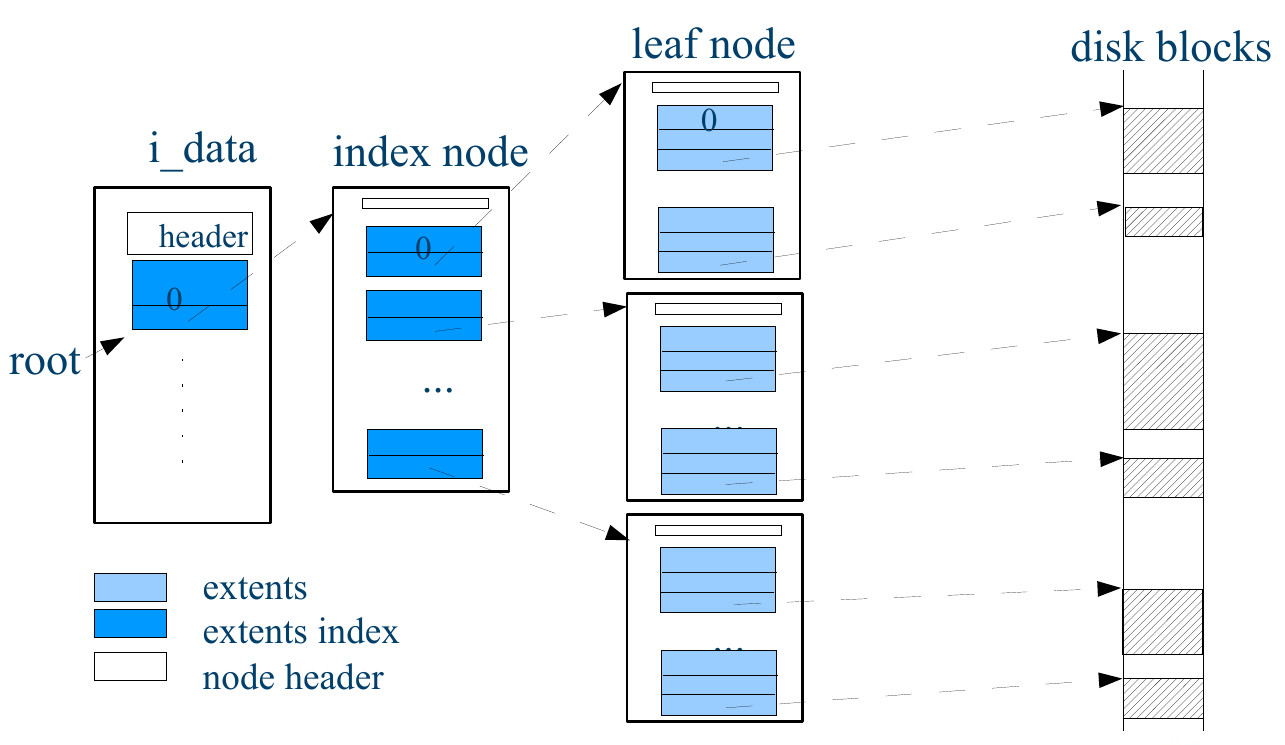
Другая фича ext4 - использование расширений (extent), которые пришли на смену косвенной адресации блоков данных.
Расширения используются, в том числе, и для выделения дискового пространства
под данные для больших файлов, их структура состоит из адреса первого блока данных и длины выделенного количества блоков под данные:
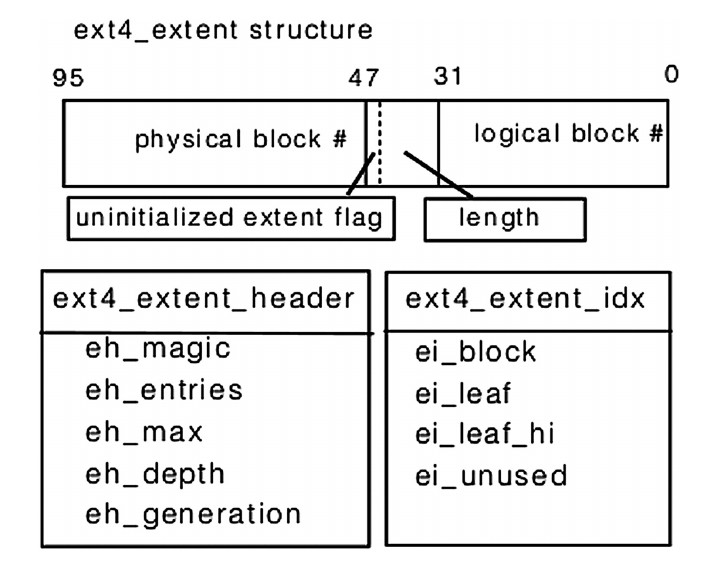
В расширение может входить до 2^15 блоков, что равно 128 метрам для 4-килобайтного блока.
Физический адрес блока имеет размерность в 48 бит, логический - в 32 бита.
Сравнивая структуру ноды в ext3 и ext4, можно заметить, что там, где в ext3 был массив указателей на блоки данных,
в ext4 теперь располагаются расширения. Массив из 60 байт используется в ext4 следующим образом: первые 12 байт занимает
extent header. Если файл большой и при этом фрагментирован, то htree-дерево расширений может выглядеть так:
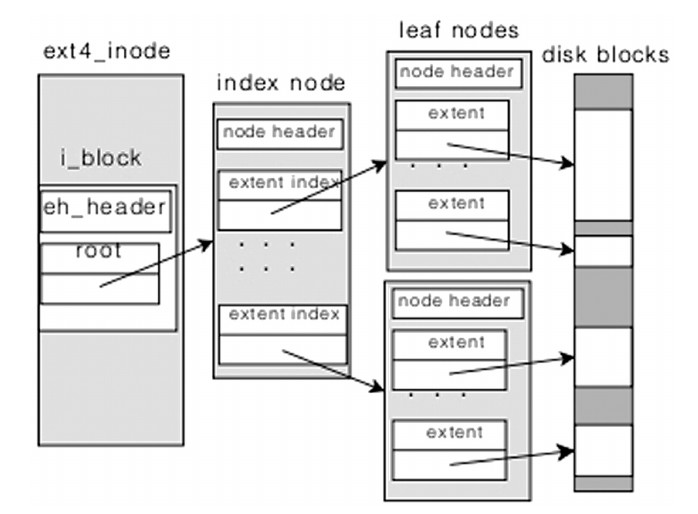
Поле eh_entries хранит число расширений в таком дереве. При размере блока в 4 килобайта в одном блоке может храниться
380 расширений. Extent index структура играет вспомогательную роль для косвенной адресации в дереве расширений.
В дереве расширений все ноды делятся на 3 категории - рутовую, индексные, листовые.
Рутовая нода может указывать на одну или несколько индексных нод. Индексная нода указывает на одну или несколько листовых нод.
В ext4 изменился размер ноды - он вырос со 128 до 256 байт. Это позволяет хранить время в наносекундах, а ткже 64-битные номера нод.
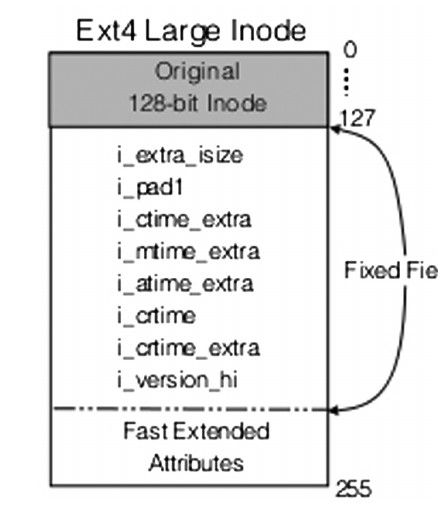
Новые поля добавлены во вторую половину ноды.
Для ext3 максимальный размер файловой системы ограничен в 16 терабайт, потому что адреса блоков данных 32-битные.
В ext4 адрес блока вырос до 48 бит, при этом максимальный размер файловой системы вырос до 1 exabyte.
Для этого групповые дескрипторы стали поддерживать 64 бита. Максимальный размер файла в ext3 ограничен 2 терабайтами.
В ext4 он вырос до 16 терабайт. Для этого введен специальный флаг - HUGE_FILE. Когда он установлен, 48-битное поле i_blocks
интерпретируется по-другому - как число файловых блоков, а не дисковых секторов.
В ext4 ноде поле i_blocks по умолчанию 32-битное, но при выставленном флаге HUGE_FILE это ограничение снимается.
ext4 может динамически изменять свой собственный размер, т.е. расширяться.
При добавлении новой блоковой группы соответственно добавляются новые групповые дескрипторы в уже существующую
таблицу групповых дескрипторов, которые специально зарезервированы под этот случай. Если они кончаются, то в новой группе
создается новая таблица группповых дескрипторов. ext2 и ext3, как известно, по умолчанию имеют общий фиксированный размер
для файловой системы.
Еще одно отличие ext4 - неограниченное количество поддиректорий. В ext3, как известно, оно ограничено и равно 32000.
В ext4 существенно сократилось время поиска файла - квадратичная зависимость поменялась на линейную благодаря использованию htree.
В таком дереве рутовая нода может ссылаться на 508 индексных нод, каждая из которых в свою очередь может ссылаться на 511 листовых нод.
Также ext4 частично совместима с более ранними версиями. ext3 можно сконвертировать в ext4, при этом старые файлы
будут использовать прежнюю косвенную адресацию блоков данных, в то время как новые файлы будут создаваться с помощью расширений.
Обратная конвертация ext4 в ext3 невозможна.
Появился новый механизм выделения блоков - preallocation. Теперь может быть выделено 2^15 блоков за раз, при этом
специальное поле - extent length sield - устанавливается в значение 0x8000. Отложенное выделение блоков - delayed allocation -
позволяет кешировать их в памяти и сбрасывать на диск только в последний момент, тем самым снижая нагрузку на диск.
Журналирование в ext4 немного отличается от ext3. В транзакционный коммит-блок добавляется контрольная сумма для проверки валидности.
Это изменило транзакционный механизм, удалило из него лишнюю фазу, что ускорило его на 20%.
Контрольные суммы появились в групповых дескрипторах, что сделало более надежным использование счетчика числа свободных нод,
а также ускорило работу утилиты e2fsck, которая теперь не проверяет неиспользуемые сектора диска.
Фрагментация является одной из серьезных проблем для любой файловой системы, особенно с увеличением среднего размера файлов.
Онлайн-фрагментация решает эту проблему несколькими путями - она может перемещать мелкие файлы в отдельную область,
может выделять для больших файлов сплошное пространство.
block allocator
Выделение блоков - ключевой аспект в разработке файловых систем.
Оно решает такие задачи, как уменьшение времени поиска и фрагментации.
В ext3 диск разбивается на блоковые группы размером 128 метров. В каждой группе имеется единственный блок битмапов,
который хранит индекс доступных блоков.
ext3 всегда начинает выделять блоки в той группе, где хранится таблица нод. Если блоков не хватает,
поиск продолжается в следующей блоковой группе. При сохранении файла ext3 откусывает последовательно порции по 8 блоков.
Когда происходит одновременная запись нескольких файлов, ext3 резервирует блоки для того, чтобы они не перемешивались на диске.
Есть специальное окно в памяти, которое создается для каждого файла,
которое будет проверяться каждый раз при сохранении очередного файла.
Этими окнами управляет специальное дерево - red-black tree, которое синхронизирует итоговый апдэйт битмапов.
Использование этого окна ограничивает возможности ext3.
Другим недостатком ext3 является то, что она не делает разницы между маленькими и большими файлами.
Каталог /etc хранит большое количество мелких конфигурационных файлов.
Часто мы наблюдаем картину, когда загрузка дистрибутива начинает тормозить, потому что идет долгий поиск этих файлов,
которые разбросаны по диску.
В ext4 механизм выделения блоков состоит из двух основных алгоритмов:
per-inode выделение и per-CPU выделение. Первый алгоритм используется для больших файлов.
По умолчанию, если размер файла меньше 16 блоков, используется второй алгоритм.
Новый блоковый аллокатор называется mballoc. Предыдущие версии выделяли за раз 1 мегабайт памяти,
mballoc же учитывает размер файлов. Он позволяет повысить скорость записи в два раза.
mballoc хорошо показывает себя для RAID, поскольку в алгоритме дисковой синхронизации может быть опущена фаза чтения.
Расширения в ext4 позволяют выделять порцию блоков зв раз. Отложенное выделение позволяет сэкономить на дисковых операциях.
Оно в основном реализовано в VFS-слое операционной системы.
В ext4 добавлены новые варианты для write_begin(), write_end() и writepage().
По умолчанию в ext4 устанавливается режим журналирования writeback.
Размер блоковой группы в ext4 ограничен 128 метрами.
Новый блоковый аллокатор пытается найти блоковую группу с максимально возможным числом свободных блоков.
Также он анализирует блоки на предмет их принадлежности к одной корневой директории и пытается выделять их
в одной блоковой группе.
В ext4 есть ограничения. Например, в файловой системе общим размером в 1 терабайт будет 8192 блоковых групп,
что увеличивает время поиска. Решение может быть найдено в использовании одного битмапа сразу для нескольких групп.
В ext4 появился флаг FLEX_BG, который позволяет на этапе форматирования группировать битмапы и нодовые таблицы
в начале одной виртуальной блоковой группы, что преодолевает ограничения размера блоковых групп,
уменьшает время поиска и улучшает выделение расширений под сами файлы.
Размер такой виртуальной группы кратен размеру обычной блоковой группы, т.е. кратен 128 метрам.
E2fsprogs
Утилита e2fsck была в свое время скопирована с другой утилиты - fsck.minix.
Пакет E2fsprogs появился с целью создания утилиты fsck, которая стала быстрее на порядок.
Она делает несколько проходов по файловой системе и кеширует метаинформацию во время своих проходов.
Директории в третьем проходе читаются в отсортированном порядке.
Ноды для косвенных блоков сортируются во время второго прохода.
В первом проходе сканируется суперблок.
Во втором - таблица нод и расширения. Проверяются блоки, на которые есть сылки более чем из одной ноды.
В третьем проходе сканируются директории.
В четвертом проходе проверяется иерархия дерева каталогов.
Если обнаружена поврежденная директория, перестраивается дерево.
Если передан параметр -D, директории оптимизируются.
В пятом проходе проверяются нодовые счетчики ссылок.
В шестом проходе проверяются битмапы.
12-байтная структура ext4_extent позволяет адресовать пространство размером до 1 экзабайта,
размер самого расширения может быть вплоть до 128 метров,
максимальный размер файла - 16 терабайт:

Как показано на следующем рисунке, в индексной ноде есть поле i_data, которое напрямую может указывать
на 4 блока данных:
При форматировании партиции утилита mke2fs по умолчанию создает мета-группу из 16 блоковых групп для хранения метаданных,
в том числе для двух битовых таблиц и общей нодовой таблицы. Метаданные сохраняются отдельно от самих данных.
Это существенно уменьшает время поиска.
фоновая дефрагментация
Когда файловая система используется длительное время, блоки данных разбиваются на разрозненные фрагменты.
Это может происходить из-за наличия большого числа параллельных процессов или несовершенства самой файловой системы.
Дефрагментация увеличивается после массового удаления файлов.
Это приводит к торможению скорости чтения данных с диска.
Придумано несколько алгоритмов для уменьшения этой фрагментации:
Отложенное выделение - блоки сначала накапливаются в памяти, а затем пачкой сбрасываются на диск.
Резервирование блоков - блоки резервируются после конца уже выделенной области для дальнейшего непрерывного добавления.
Сущестуют три разновидности фрагментации:
1. Для одного файла, фрагменты которого раскиданы по диску
2. Для группы файлов, которые раскиданы по диску
3. Фрагментация свободного пространства - когда файловая система имеет большое количество свободных кусков
относительно малого размеров.
Фрагментация первого типа может быть удалена так: создается временная нода, выделяются блоки данных для временного файла,
копируются данные, затем модифицируется нода.
Аналогично решается задача для второго типа, при этом итерационно используется алгоритм первого типа.
В памяти существует специальный битмап, который называется buddy bitmap. Он управляет выделением непрерывных последовательностей
блоков. Он разделен на области, состоящие из последовательностей: двух, четырех, восьми и т.д. блоков.
Т.е. тут хранятся адреса последовательностей свободных подряд дисковых блоков.
Это позволяет VFS очень быстро находить свободные последовательности нужного размера, идущие подряд.
Например, для выделения области в 14 блоков берутся последовательности в 8, 4 и 2 блока.
space maps
В ext4, наряду со стандартными блоковыми группами по 128 метров, появились т.н. мета-группы размером до 8 гигов,
которые могут обьединять в себе несколько обычных групп.
В этих метагруппах добавлена специальная структура для управления свободным дисковым пространством - т.н. space map.
Она включает в себя красно-черное дерево и лог:
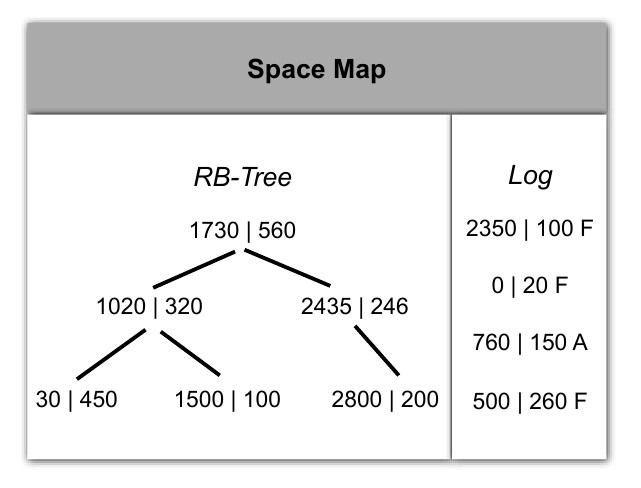
Размер такого дерева, в отличие от битмапа, непостоянен и динамически изменяется. Число нод в таком дереве равно чилу
свободных непрерывных участков в метагруппе. Если например, в метагруппе размером в 8 гигов имеется 2000 свободных фрагментов,
умножаем 2000 на размер ноды в 20 байт для красно-черного дерева, и получаем 40 килобайт на все дерево.
Файловой мета-группе в 8 терабайт потребуется дерево размером в 48 метров, и его спокойно можно разместить в памяти,
в то время как битмап будет занимать уже 256 метров. space map создается при монтировании системы и при каждом монтировании
загружается в память. Структура в дереве выглядит так:
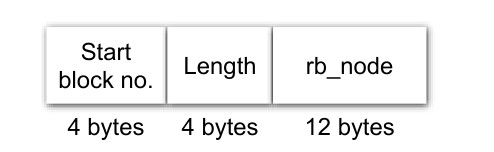
Лог запоминает историю изменений и позволяет уменьшить фрагментацию. Его структура похоже на ноду, только третье поле - флаг -
имеет размер в один байт.
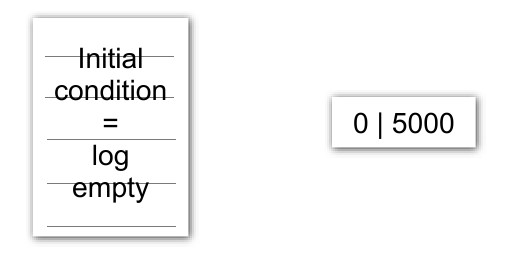
Теперь рассмотрим следующий сценарий: у нас имеется свежая, только что отформатированная метагруппа с 5000 блоков.
Лог пуст, а space maps дерево состоит всего из одной ноды (слева лог, справа дерево):
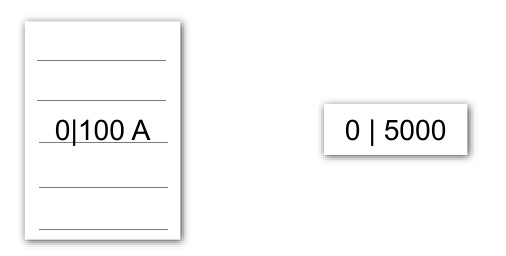
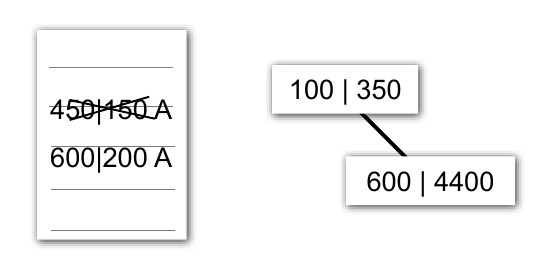
Теперь запросим у файловой системы 100 блоков, начиная с нулевого.
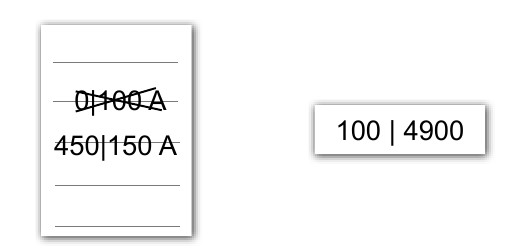
Теперь запросим еще 150 блоков, начиная с 450-го:
Теперь запросим еще 200 блоков:
Размер блока влияет на число битмапов. Чем меньше размер блока, тем больше битмапов.
А для метагруппы размер space map tree никак не завист от этого.
Обратная сторона медали - в том, что при монтировании красно-черное дерево надо прочитать, а при отмонтировании сохранить на диск,
что требует дополнительного времени.
|
| uncleura | "Дефрагментация увеличивается после массового удаления файлов."
2021-08-03 09:52:12 | |
| 
 LINUX
LINUX 
 Kernels
Kernels
