Основные концепции файловой системы
Концепции файловой системы полезны для прикладного программиста ,
потому что они используются им при написании приложений.
Файлы и файловые имена
Слово файл имеет реальный аналог.
Ранее файл представлял из себя набор одного или нескольких стандартных листов бумаги.
В линуксе файл - это линейный набор бвйт.
Этот набор играет большую роль в жизни пользователя.
Файловая система реализует интерфейс хранения этих данных и манипуляции ими на внешних носителях.
В линуксовом файле есть много атрибутов и характеристик.
Атрибутами являются имя файла , его расширение.
Файлы с расширениями .h или .c используются компиляторами и линкерами как хидеры и исходники.
Типы файлов
Линукс поддерживает множество файловых типов , таких как регулярные файлы , директории ,
линки , файлы устройств ,сокеты,пайпы.
Регулярные файлы включают в себя бинарные и ASCII файлы.
ASCII представляют из себя обычный набор текста.
Некоторые ASCII файлы выполняемы и называются скриптами , выполняемыми с помощью интепретаторов.
Важнейшим интерпретатором является шелл.
Бинарные исполняемые файлы интерпретируются уже ядром и выполняются ядром.
Их формат известен как object file format.
Каталоги в линуксе организованы в иерархическую систему
которая показана на рисунке Figure 6.1.
Линк является указателем и указывает на другой файл.
Файлы устройств представляют I/O устройства.
Для доступа к таким устройствам программы используют такие файлы.
Существуют 2 типа устройств: блочные устройства,
которые переводят данные в блоки,
и символьные устройства, которые переводят данные в символы.
Сокеты и пайпы являются формой Interprocess Communication (IPC).
Такие файлы поддерживают непосредственный обмен данными между процессами.
Дополнительные файловые атрибуты
К дополнительным атрибутам относятся права доступа.
Защита файла имеет большое значение в много-пользовательских системах.
Пользователи делятся на 3 категории :
Для каждого файл ведет себя по-разному.
Права используются применительно к 3 операциям : чтение , запись и выполнение файла.
В соответствии с классификацией мы имеем девять наборов прав.
Другие атрибуты включают размер , время создания и изменения
и могут быть распечатаны с помощью утилиты ls.
Например , некоторые файлы ядра имеют атрибуты , которые невидимы пользователю.
Директории и пути
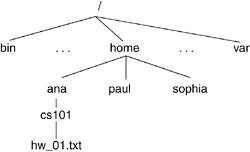
A directory is a file that maintains the hierarchical structure of the filesystem. The directory keeps track of the files it contains, any directories beneath it, and information about itself. In Linux, each user gets his own "home directory," under which he stores his files and creates his own directory tree structure. In Figure 6.1, we see how the directory contributes to the tree structure of the filesystem.
With the arrangement of the filesystem into a tree structure, the filename alone is not sufficient to locate the file; we must know where it is located in the tree to find it. A file's pathname describes the location of the file. A file's location can be described with respect to the root of the tree, which is known as the absolute pathname. The absolute pathname starts with the root directory, which is referred to as /. A directory node's name is the directory name followed by a /, such as bin/. Thus, a file's absolute pathname is expressed as a collection of all the directory nodes one traverses in the tree until one reaches the file. In Figure 6.1, the absolute pathname of the file called hw1.txt is /home/ana/cs101/hw1.txt. Another way of representing a file is with a relative pathname. This depends on the working directory of the process associated with the file. The working directory, or current directory, is a directory associated with the execution of a process. Hence, if /home/ana/ is the working directory for our process, we can refer to the file as cs101/hw1.txt.
In Linux, directories contain files that perform varying tasks during the operation of the operating system. For example, shareable files are stored under /usr and /opt whereas unshareable files are stored under /etc/ and /boot. In the same manner, non-static files, those whose contents are changed by system programs, are stored under the vcertain directories under /var. Refer to http://www.pathname.com/fhs for more information on the filesystem hierarchy standard.
In Linux, each directory has two entries associated with it: . (pronounced "dot") and .. (pronounced "dot dot"). The . entry denotes the current directory and .. denotes the parent directory. For the root directory, . and .. denote the current directory. (In other words, the root directory is its own parent.) This notation plays into relative pathnames in the following manner. In our previous example, the working directory was /home/ana and the relative pathname of our file was csw101/hw1.txt. The relative pathname of a hw1.txt file in paul's directory from within our working directory is ../paul/cs101/hw1.txt because we first have to go up a level.
6.1.5. File Operations
File operations include all operations that the system allows on the files. Generally, files can be created and destroyed, opened and closed, read and written. Additionally, files can also be renamed and its attributes can be changed. The filesystem provides system calls as interfaces to these operations, and these are in turn placed in wrapper functions that are made accessible to user space applications by way of linkable libraries. We explore some of these operations as we traverse through the implementation of the Linux filesystem.
6.1.6. File Descriptors
A file descriptor is an int datatype that the system uses to identify an open file. The open() system call returns a file descriptor that can later be used on all future operations to be visited upon that file by that process. In a later section, we see what the file descriptor stands for in kernel terms.
Each process holds an array of file descriptors. When we discuss the kernel structures that support the filesystem, we see how this information is maintained in an array. It is by convention that the first element of the array (file descriptor 0) is associated with the process' standard input, the second (file descriptor 1) with standard output, and the third (file descriptor 2) with standard error. This allows applications to open a file on standard input, output, or error. Figure 6.2 illustrates the file descriptor array pertaining to a process.
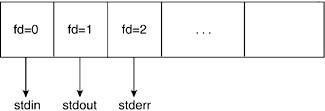
File descriptors are assigned on a "lowest available index" basis. Thus, if a process is to open multiple files, the assigned file descriptors will be incrementally higher unless a previously opened file is closed before the new one. We see how the open and close system calls manipulate file descriptors to ensure this. Hence, within a process' lifetime, it might open two different files that will have the same file descriptor if one is closed before the other is opened. Conversely and separately, two different file descriptors can point to the same file.
6.1.7. Disk Blocks, Partitions, and Implementation
To understand the concerns of filesystem implementation, we need to understand some basic concepts about hard disks. Hard disks magnetically record data. A hard disk contains multiple rotating disks on which data is recorded. A head, which is mounted on a mechanical arm that moves over the surface of the disk, reads and writes the data by moving along the radius of the disks, much like the needle of a turntable. The disks themselves rotate much like LP's on a turntable. Each disk is broken up into concentric rings called tracks. Tracks are numbered starting from the outside to the inside of the disk. Groups of the same numbered tracks (across the disks) are called cylinders. Each track is in turn broken up into (usually) 512K byte sectors. Cylinders, tracks, and heads make up the geometry of a hard drive.
A blank disk must first be formatted before the filesystem is made. Formatting creates tracks, blocks, and partitions in a disk. A partition is a logical disk and is how the operating system allocates or uses the geometry of the hard drive. The partitions provide a way of dividing a single hard disk to look as though there were multiple disks. This allows different filesystems to reside in a common disk. Each partition is split up into tracks and blocks. The creation of tracks and blocks in a disk is done by way of programs such as fdformat whereas the creation of logical partitions is done by programs such as fdisk. Both of these precede creation of the actual filesystem.
The Linux file tree can provide access to more than one filesystem. This means that if you have a disk with multiple partitions, each of which has a filesystem, it is possible to view all these filesystems from one logical namespace. This is done by attaching each filesystem to the main Linux filesystem tree by using the mount command. We say that a filesystem is mounted to refer to the fact that the device filesystem is attached and accessible from the main tree. Filesystems are mounted onto directories. The directory onto which a filesystem is mounted is referred to as the mount point.
One of the main difficulties in filesystem implementation is in determining how the operating system will keep track of the sequence of bytes that make up a file. As previously mentioned, the disk partition space is split into chunks of space called blocks. The size of a block varies by implementation. The management of blocks determines the speed of file access and the level of fragmentation and therefore wasted space. For example, if we have a block size of 1,024 bytes and a file size of 1,567 bytes, the file spans two blocks. The operating system keeps track of the blocks that belong to a particular file by keeping the information in a structure called an index node (inode).
6.1.8. Performance
There are various ways in which the filesystem improves system performance. One way is by maintaining internal infrastructure in the kernel that quickly accesses an inode that corresponds to a given pathname. We see how the kernel does this when we explain filesystem implementation.
The page cache is another method in which the filesystem improves performance. The page cache is an in-memory collection of pages. It is designed to cache many different types of pages, originating from disk files, memory-mapped files, or any other page object the kernel can access. This caching mechanism greatly reduces disk accesses and thus improves system performance. This chapter shows how the page cache interacts with disk accesses in the course of file manipulation.
6.2. Linux Virtual Filesystem
The implementation of filesystems varies from system to system. For example, in Windows, the implementation of how a file relates to a disk block differs from how a file in a UNIX filesystem relates to a disk block. In fact, Microsoft has various implementations of filesystems that correspond to its various operating systems: MS-DOS for DOS and Win 3.x, VFAT for Windows 9x, and NTFS for Windows NT. UNIX operating systems also have various implementations, such as SYSV and MINIX. Linux specifically uses filesystems such as ext2, ext3, and ResierFS.
One of the best attributes of Linux is the many filesystems it supports. Not only can you view files from its own filesystems (ext2, ext3, and ReiserFS), but you can also view files from filesystems pertaining to other operating systems. On a single Linux system, you are capable of accessing files from numerous different formats. Table 6.1 lists the currently supported filesystems. To a user, there is no difference between one filesystem and another; he can indiscriminately mount any of the supported filesystems to his original tree namespace.
Table 6.1. Some of the Linux Supported FilesystemsFilesystem Name | Description |
|---|
ext2 | Second extended filesystem | ext3 | ext3 journaling filesystem | Reiserfs | Journaling filesystem | JFS | IBM's journaled filesystem | XFS | SGI Irix's high-performance journaling filesystem | MINIX | Original Linux filesystem, minix OS filesystem | ISO9660 | CD-ROM filesystem | JOLIET | Microsoft CRDOM filesystem extensions | UDF | Alternative CROM, DVD filesystem | MSDOS | Microsoft Disk Operating System | VFAT | Windows 95 Virtual File Allocation Table | NTFS | Windows NT, 2000, XP, 2003 filesystem | ADFS | Acorn Disk filesystem | HFS | Apple Macintosh filesystem | BEFS | BeOs filesystem | FreeVxfs | Veritas Vxfs support | HPFS | OS/2 support | SysVfs | System V filesystem support | NFS | Networking filesystem support | AFS | Andrew filesystem (also networking) | UFS | BSD filesystem support | NCP | NetWare filesystem | SMB | Samba |
Linux supports more than on-disk filesystems. It also supports network-mounted filesystems and special filesystems that are used for things other than managing disk space. For example, procfs is a pseudo filesystem. This virtual filesystem provides information about different aspects of your system. A procfs filesystem does not take up hard disk space and files are created on the fly upon access. Another such filesystem is devfs, which provides an interface to device drivers.
Linux achieves this "masquerading" of the physical filesystem specifics by introducing an intermediate layer of abstraction between user space and the physical filesystem. This layer is known as the virtual filesystem (VFS). It separates the filesystem-specific structures and functions from the rest of the kernel. The VFS manages the filesystem-related system calls and translates them to the appropriate filesystem type functions. Figure 6.3 overviews the filesystem-management structure.
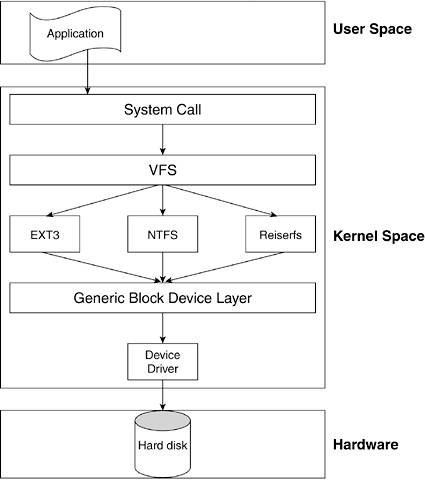
The user application accesses the generic VFS through system calls. Each supported filesystem must have an implementation of a set of functions that perform the VFS-supported operations (for example, open, read, write, and close). The VFS keeps track of the filesystems it supports and the functions that perform each of the operations. You know from
Chapter 5 that a generic block device layer exists between the filesystem and the actual device driver. This provides a layer of abstraction that allows the implementation of the filesystem-specific code to be independent of the specific device it eventually accesses.
6.2.1. VFS Data Structures
The VFS relies on data structures to hold its generic representation of a filesystem.
The data structures are as follows:
superblock structure.
Stores information relating to mounted filesystems
inode structure.
Stores information relating to files
file structure.
Stores information related to files opened by a process
dentry structure.
Stores information related to a pathname and the file pointed to
In addition to these structures, the VFS also uses additional structures such as vfsmount, and nameidata, which hold mounting information and pathname lookup information, respectively. We see how these two structures relate to the main ones just described, although we do not independently cover them.
The structures that compose the VFS are associated with actions that can be applied on the object represented by the structure. These actions are defined in a table of operations for each object. The tables of operations are lists of function pointers. We define the operations table for each object as we describe them. We now closely look at each of these structures. (Note that we do not focus on any locking mechanisms for the purposes of clarity and brevity.)
6.2.1.1. superblock Structure
When a filesystem is mounted, all information concerning it is stored is the super_block struct. One superblock structure exists for every mounted filesystem. We show the structure definition followed by explanations of some of the more important fields:
-----------------------------------------------------------------------
include/linux/fs.h
666 struct super_block {
667 struct list_head s_list;
668 dev_t s_dev;
669 unsigned long s_blocksize;
670 unsigned long s_old_blocksize;
671 unsigned char s_blocksize_bits;
672 unsigned char s_dirt;
673 unsigned long long s_maxbytes;
674 struct file_system_type *s_type;
675 struct super_operations *s_op;
676 struct dquot_operations *dq_op;
677 struct quotactl_ops *s_qcop;
678 struct export_operations *s_export_op;
679 unsigned long s_flags;
680 unsigned long s_magic;
681 struct dentry *s_root;
682 struct rw_semaphore s_umount;
683 struct semaphore s_lock;
684 int s_count;
685 int s_syncing;
686 int s_need_sync_fs;
687 atomic_t s_active;
688 void *s_security;
689
690 struct list_head s_dirty;
691 struct list_head s_io;
692 struct hlist_head s_anon;
693 struct list_head s_files;
694
695 struct block_device *s_bdev;
696 struct list_head s_instances;
697 struct quota_info s_dquot;
698
699 char s_id[32];
700
701 struct kobject kobj;
702 void *s_fs_info;
...
708 struct semaphore s_vfs_rename_sem;
709 };
-----------------------------------------------------------------------
Line 667
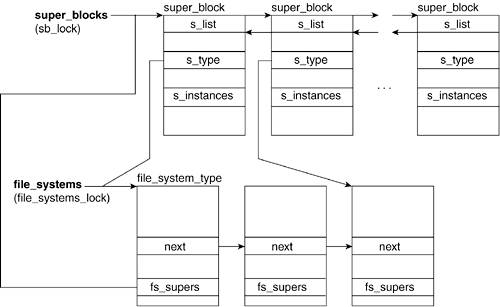
The s_list field is of type list_head, which is a pointer to the next and previous elements in the circular doubly linked list in which this super_block is embedded. Like many other structures in the Linux kernel, the super_block structs are maintained in a circular doubly linked list. The list_head datatype contains pointers to two other list_heads: the list_head of the next superblock object and the list_head of the previous superblock objects. (The global variable super_blocks (fs/super.c) points to the first element in the list.)
Line 672
On disk-based filesystems, the superblock structure is filled with information originally maintained in a special disk sector that is loaded into the superblock structure. Because the VFS allows editing of fields in the superblock structure, the information in the superblock structure can find itself out of sync with the on-disk data. This field identifies that the superblock structure has been edited and needs to sync up with the disk.
Line 673
This field of type unsigned long defines the maximum file size allowed in the filesystem.
Line 674
The superblock structure contains general filesystem information. However, it needs to be associated with the specific filesystem information (for example, MSDOS, ext2, MINIX, and NFS). The file_system_type structure holds filesystem-specific information, one for each type of filesystem configured into the kernel. This field points to the appropriate filesystem-specific struct and is how the VFS manages the interaction from general request to specific filesystem operation.
Figure 6.4 shows the relation between the superblock and the file_system_type structures. We show how the superblock->s_type field points to the appropriate file_system_type struct in the file_systems list. (In the "Global and Local List References" section later in this chapter, we show what the file_systems list is.)
Line 675
The field is a pointer of type super_operations struct. This datatype holds the table of superblock operations. The super_operations struct itself holds function pointers that are initialized with the particular filesystem's superblock operations. The next section explains super_operations in more detail.
Line 681
This field is a pointer to a dentry struct. The dentry struct holds the pathname of a file. This particular dentry object is the one associated with the mount directory whose superblock this belongs to.
Line 690
The s_dirty field (not to be confused with s_dirt) is a list_head struct that points to the first and last elements in the list of dirty inodes belonging to this filesystem.
Line 693
The s_files field is a list_head struct that points to the first element of a list of file structs that are both in use and assigned to the superblock. In the "file Structure" section, you see that this is one of the three lists in which a file structure can find itself.
Line 696
The field of s_instances is a list_head structure that points to the adjacent superblock elements in the list of superblocks with the same filesystem type. The head of this list is referenced by the fs_supers field of the file_system_type structure.
Line 702
This void * data type points to additional superblock information that is specific to a particular filesystem (for example, ext3_sb_info). This acts as a sort of catch-all for any superblock data on disk for that specific filesystem that was not abstracted out into the virtual filesystem superblock concept.
6.2.1.2. superblock Operations
The s_op field of the superblock points to a table of operations that the filesystem's superblock can perform. This list is specific to each filesystem because it operates directly on the filesystem's implementation. The table of operations is stored in a structure of type super_operations:
-----------------------------------------------------------------------
include/linux/fs.h
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
void (*destroy_inode)(struct inode *);
void (*read_inode) (struct inode *);
void (*dirty_inode) (struct inode *);
void (*write_inode) (struct inode *, int);
void (*put_inode) (struct inode *);
void (*drop_inode) (struct inode *);
void (*delete_inode) (struct inode *);
void (*put_super) (struct super_block *);
void (*write_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
void (*write_super_lockfs) (struct super_block *);
void (*unlockfs) (struct super_block *);
int (*statfs) (struct super_block *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*clear_inode) (struct inode *);
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct vfsmount *);
};
-----------------------------------------------------------------------
When the superblock of a filesystem is initialized, the s_op field is set to point at the appropriate table of operations. In the "
Moving from the Generic to the Specific" section later in this chapter, we show how this table of operations is implemented in the ext2 filesystem. Table 6.2 shows the list of superblock operations. Some of these functions are optional and are only filled in by a subset of the supported filesystems. Those that do not support a particular optional function set the field to NULL in the operations struct.
Table 6.2. Superblock OperationsSuperblock Operations Name | Description |
|---|
alloc_inode | New in 2.6. It allocates and initializes a vfs inode under the superblock. The specifics of initialization are left up to the particular filesystem. The allocation is done with a call to kmem_cache_create() or kemem_cache_alloc() (see
Chapter 4) on the inode's cache. | destroy_inode | New in 2.6. It deallocates the specified inode pertaining to the superblock. The deallocation is done with a call to kmem_cache_free(). | read_inode | Reads the inode specified by the inode->i_ino field. The inode's fields are updated from the on-disk data. Particularly important is inode->i_op. | dirty_inode | Places an inode in the superblock's dirty inode list. The head and tail of the circular, doubly linked list is referenced by way of the superblock->s_dirty field. Figure 6.5 illustrates a superblock's dirty inode list. | write_inode | Writes the inode information to disk. | put_inode | Releases the inode from the inode cache. It's called by iput(). | drop_inode | Called when the last access to an inode is dropped. | delete_inode | Deletes an inode from disk. Used on inodes that are no longer needed. It's called from generic_delete_inode(). | put_super | Frees the superblock (for example, when unmounting a filesystem). | write_super | Writes the superblock information to disk. | sync_fs | Currently used only by ext3, Resiserfs, XFS, and JFS, this function writes out dirty superblock struct data to the disk. | write_super_lockfs | In use by ext3, JFS, Resierfs, and XFS, this function blocks changes to the filesystem. It then updates the disk superblock. | unlockfs | Reverses the block set by the write_super_lockfs() function. | stat_fs | Called to get filesystem statistics. | remount_fs | Called when the filesystem is remounted to update any mount options. | clear_inode | Releases the inode and all pages associated with it. | umount_begin | Called when a mount operation must be interrupted. | show_options | Used to get filesystem information from a mounted filesystem. |
This completes our introduction of the superblock structure and its operations. Now, we explore the inode structure in detail.
6.2.1.3. inode Structure
We mentioned that inodes are structures that keep track of file information, such as pointers, to the blocks that contain all the file data. Recall that directories, devices, and pipes (for example) are also represented as files in the kernel, so an inode can represent one of them as well. Inode objects exist for the full lifetime of the file and contain data that is maintained on disk.
Inodes are kept in lists to facilitate referencing. One list is a hash table that reduces the time it takes to find a particular inode. An inode also finds itself in one of three types of doubly linked list. Table 6.3 shows the three list types. Figure 6.5 shows the relationship between a superblock structure and its list of dirty inodes.
Table 6.3. Inode ListsList | i_count | Dirty | Reference Pointer |
|---|
Valid, unused | i_count = 0 | Not dirty | inode_unused (global) | Valid, in use | i_count > 0 | Not dirty | inode_in_use (global) | Dirty inodes | i_count > 0 | Dirty | superblock's s_dirty field |
The inode struct is large and has many fields. The following is a description of a small subset of the inode struct fields:
-----------------------------------------------------------------------
include/linux/fs.h
368 struct inode {
369 struct hlist_node i_hash;
370 struct list_head i_list;
371 struct list_head i_dentry;
372 unsigned long i_ino;
373 atomic_t i_count;
...
390 struct inode_operations *i_op;
...
392 struct super_block *i_sb;
...
407 unsigned long i_state;
...
421 };
-----------------------------------------------------------------------
Line 369
The i_hash field is of type hlist_node. This contains a pointer to the hash list, which is used for speedy inode lookup. The inode hash list is referenced by the global variable inode_hashtable.
Line 370
This field links to the adjacent structures in the inode lists. Inodes can find themselves in one of the three linked lists.
Line 371
This field points to a list of dentry structs that corresponds to the file. The dentry struct contains the pathname pertaining to the file being represented by the inode. A file can have multiple dentry structs if it has multiple aliases.
Line 372
This field holds the unique inode number. When an inode gets allocated within a particular superblock, this number is an automatically incremented value from a previously assigned inode ID. When the superblock operation read_inode() is called, the inode indicated in this field is read from disk.
Line 373
The i_count field is a counter that gets incremented with every inode use. A value of 0 indicates that the inode is unused and a positive value indicates that it is in use.
Line 392
This field holds the pointer to the superblock of the filesystem in which the file resides. Figure 6.5 shows how all the inodes in a superblocks' dirty inode list will have their i_sb field pointing to a common superblock.
Line 407
This field corresponds to inode state flags. Table 6.4 lists the possible values.
Table 6.4. Inode StatesInode State Flags | Description |
|---|
I_DIRTY_SYNC | See I_DIRTY description. | I_DIRTY_DATASYNC | See I_DIRTY description. | I_DIRTY_PAGES | See I_DIRTY description. | I_DIRTY | This macro correlates to any of the three I_DIRTY_* flags. It enables a quick check for any of those flags. The I_DIRTY* flags indicate that the contents of the inode have been written to and need to be synchronized. | I_LOCK | Set when the inode is locked and cleared when the inode is unlocked. An inode is locked when it is first created and when it is involved in I/O transfers. | I_FREEING | Gets set when an inode is being removed. This flag serves the purpose of tagging the inode as unusable as it is being deleted so no one takes a new reference to it. | I_CLEAR | Indicates that the inode is no longer useful. | I_NEW | Gets set upon inode creation. The flag gets removed the first time the new inode is unlocked. |
An inode with the I_LOCK or I_DIRTY flags set finds itself in the inode_in_use list. Without either of these flags, it is added to the inode_unused list.
6.2.1.4. dentry Structure
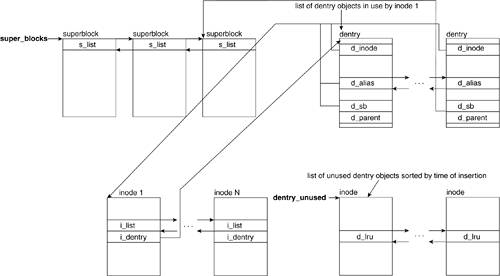
The dentry structure represents a directory entry and the VFS uses it to keep track of relations based on directory naming, organization, and logical layout of files. Each dentry object corresponds to a component in a pathname and associates other structures and information that relates to it. For example, in the path /home/lkp/Chapter06.txt, there is a dentry created for /, home, lkp, and Chapter06.txt. Each dentry has a reference to that component's inode, superblock, and related information. Figure 6.6 illustrates the relationship between the superblock, the inode, and the dentry structs.
We now look at some of the fields of the dentry struct:
-----------------------------------------------------------------------
include/linux/dcache.h
81 struct dentry {
...
85 struct inode * d_inode;
86 struct list_head d_lru;
87 struct list_head d_child; /* child of parent list */
88 struct list_head d_subdirs; /* our children */
89 struct list_head d_alias;
90 unsigned long d_time; /* used by d_revalidate */
91 struct dentry_operations *d_op;
92 struct super_block * d_sb;
...
100 struct dentry * d_parent;
...
105 } ____cacheline_aligned;
-----------------------------------------------------------------------
Line 85
The d_inode field points to the inode corresponding with the file associated with the dentry. In the case that the pathname component corresponding with the dentry does not have an associated inode, the value is NULL.
Lines 8588
These are the pointers to the adjacent elements in the dentry lists. A dentry object can find itself in one of the kinds of lists shown in Table 6.5.
Table 6.5. Dentry ListsListname | List Pointer | Description |
|---|
Used dentrys | d_alias | The inode with which these dentrys are associated points to the head of the list via the i_dentry field. | Unused dentrys | d_lru | These dentrys are no longer in use but are kept around in case the same components are accessed in a pathname. |
Line 91
The d_op field points to the table of dentry operations.
Line 92
This is a pointer to the superblock associated with the component represented by the dentry. Refer to Figure 6.6 to see how a dentry is associated with a superblock struct.
Line 100
This field holds a pointer to the parent dentry, or the dentry corresponding to the parent component in the pathname. For example, in the pathname /home/paul, the d_parent field of the dentry for paul points to the dentry for home, and the d_parent field of this dentry in turn points to the dentry for /.
6.2.1.5. file Structure
Another structure that the VFS uses is the file structure. When a process manipulates a file, the file structure is the datatype the VFS uses to hold information regarding the process/file association. Unlike other structures, no original on-disk data is held by a file structure; file structures are created on-the-fly upon the issue of the open() syscall and are destroyed upon issue of the close() syscall. Recall from
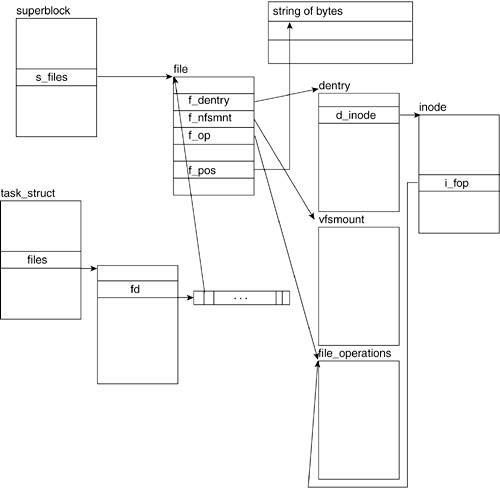
Chapter 3 that throughout the lifetime of a process, the file structures representing files opened by the process are referenced through the process descriptor (the task_struct). Figure 6.7 illustrates how the file structure associates with the other VFS structures. The task_struct points to the file descriptor table, which holds a list of pointers to all the file descriptors that process has opened. Recall that the first three entries in the descriptor table correspond to the file descriptors for stdin, stdout, and stderr, respectively.
The kernel keeps file structures in circular doubly linked lists. There are three lists in which a file structure can find itself embedded depending on its usage and assignment. Table 6.6 describes the three lists.
Table 6.6. File ListsName | Reference Pointer to Head of List | Description |
|---|
The free file object list | Global variable free_list | A doubly linked list composed of all file objects that are available. The size of this list is always at least NR_RESERVED_FILES large. | The in-use but unassigned file object list | Global variable anon_list | A doubly linked list composed of all file objects that are being used but have not been assigned to a superblock. | Superblock file object list | Superblock field s_files | A doubly linked list composed of all file objects that have a file associated with a superblock. |
The kernel creates the file structure by way of get_empty_filp(). This routine returns a pointer to the file structure or returns NULL if there are no more free structures or if the system has run out of memory.
We now look at some of the more important fields in the file structure:
-----------------------------------------------------------------------
include/linux/fs.h
506 struct file {
507 struct list_head f_list;
508 struct dentry *f_dentry;
509 struct vfsmount *f_vfsmnt;
510 struct file_operations *f_op;
511 atomic_t f_count;
512 unsigned int f_flags;
513 mode_t f_mode;
514 loff_t f_pos;
515 struct fown_struct f_owner;
516 unsigned int f_uid, f_gid;
517 struct file_ra_state f_ra;
...
527 struct address_space *f_mapping;
...
529 };
-----------------------------------------------------------------------
Line 507
The f_list field of type list_head holds the pointers to the adjacent file structures in the list.
Line 508
This is a pointer to the dentry structure associated with the file.
Line 509
This is a pointer to the vfsmount structure that is associated with the mounted filesystem that the file is in. All filesystems that are mounted have a vfsmount structure that holds the related information. Figure 6.8 illustrates the data structures associated with vfsmount structures.
Line 510
This is a pointer to the file_operations structure, which holds the table of file operations that can be applied to a file. (The inodes field i_fop points to the same structure.) Figure 6.7 illustrates this relationship.
Line 511
Numerous processes can concurrently access a file. The f_count field is set to 0 when the file structure is unused (and, therefore, available for use). The f_count field is set to 1 when it's associated with a file and incremented by one thereafter with each process that handles the file. Thus, if a file object that is in use represents a file accessed by four different processes, the f_count field holds a value of 5.
Line 512
The f_flags field contains the flags that are passed in via the open() syscall. We cover this in more detail in the "open()" section.
Line 514
The f_pos field holds the file offset. This is essentially the read/write pointer that some of the methods in the file operations table use to refer to the current position in the file.
Line 516
We need to know who the owner of the process is to determine file access permissions when the file is manipulated. These fields correspond to the uid and the gid of the user who started the process and opened the file structure.
Line 517
A file can read pages from the page cache, which is the in-memory collection of pages, in advance. The read-ahead optimization involves reading adjacent pages of a file prior to any of them being requested to reduce the number of costly disk accesses. The f_ra field holds a structure of type file_ra_state, which contains all the information related to the file's read-ahead state.
Line 527
This field points to the address_space struct, which corresponds to the page-caching mechanism for this file. This is discussed in detail in the "Page Cache" section.
6.2.2. Global and Local List References
The Linux kernel uses global variables that hold pointers to linked lists of the structures previously mentioned. All structures are kept in a doubly linked list. The kernel keeps a pointer to the head of the list using this as an access point to the list. The structures all have fields of type list_head, which they use to point to the previous and next elements in the list. Table 6.7 summarizes the global variables that the kernel holds and the type of list it keeps a reference to.
Table 6.7. VFS-Related Global VariablesGlobal Variable | Structure Type |
|---|
super_blocks | super_block | file_systems | file_system_type | dentry_unused | dentry | vfsmntlist | vfsmount | inode_in_use | inode | inode_unused | inode |
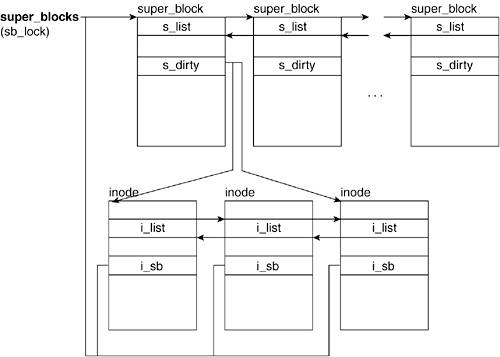
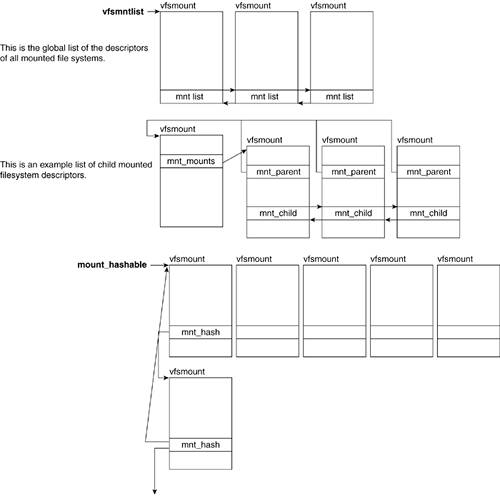
The super_block, file_system_type, dentry, and vfsmount structures are all kept in their own list. Inodes can find themselves in either global inode_in_use or inode_unused, or in the local list of the superblock under which they correspond. Figure 6.9 shows how some of these structures interrelate.
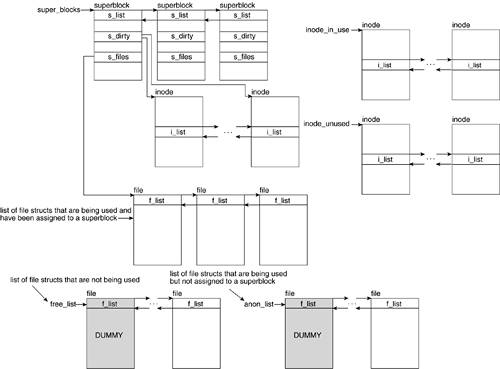
The super_blocks variable points to the head of the superblock list with the elements pointing to the previous and next elements in the list by means of the s_list field. The s_dirty field of the superblock structure in turn points to the inodes it owns, which need to be synchronized with the disk. Inodes not in a local superblock list are in the inode_in_use or inode_unused lists. All inodes point to the next and previous elements in the list by way of the i_list field.
The superblock also points to the head of the list containing the file structs that have been assigned to that superblock by way of the s_files list. The file structs that have not been assigned are placed in one of the free_list lists of the anon_list list. Both lists have a dummy file struct as the head of the list. All file structs point to the next and previous elements in their list by using the f_list field.
Refer to Figure 6.6 to see how the inode points to the list of dentry structures by using the i_dentry field.
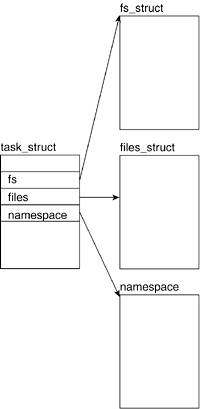
6.3. Structures Associated with VFS
Other than the four main VFS structures, a few other structures interact with VFS: fs_struct, files_struct, namespace, and fd_set. The structures fs_struct, files_stuct, and namespace are all process-related objects that contain file-related data. Figure 6.10 relates how a process descriptor associates with file-related structures. We now look at these additional structures.
6.3.1. fs_struct Structure
In Linux, multiple processes could refer to a single file. As a result, the Linux VFS must store information about how processes and files interact. For example, a process started by one user might differ from a process started by another user with respect to permissions related to file operations. The fs_struct structure holds all the information associating a particular process to a file. We need to examine the fs_struct structure prior to examining the files_struct structure because it uses the fs_struct datatype.
fs_struct can be referred to by multiple process descriptors, so it is not uncommon that an fs_struct representing a file is referenced by many task_struct descriptors:
-----------------------------------------------------------------------
include/linux/fs_struct.h
7 struct fs_struct {
8 atomic_t count;
9 rwlock_t lock;
10 int umask;
11 struct dentry * root, * pwd, * altroot;
12 struct vfsmount * rootmnt, * pwdmnt, * altrootmnt;
13 };
-----------------------------------------------------------------------
6.3.1.1. count
The count field holds the number of process descriptors that reference the particular fs_struct.
6.3.1.2. umask
The umask field holds the mask representing the permissions to be set on files opened.
6.3.1.3. root, pwd, and altroot
The root and pwd fields are pointers to the dentry object associated with the process' root directory and current working directory, respectively. altroot is a pointer to the dentry structure of an alternative root directory. This field is used for emulation environments.
6.3.1.4. rootmnt, pwdmnt, and altrootmnt
The fields rootmnt, pwdmnt, and altrootmnt are pointers to the mounted filesystem object of the process' root, current working, and alternative root directories, respectively.
6.3.2. files_struct Structure
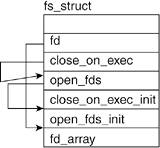
files_struct contains information related to open files and their descriptors. In the introduction, we mentioned that file descriptors are unique int datatypes associated with an open file. In kernel terms, the file descriptor is the index into the fd array of the files object of the current task's task_struct or current->files->fd. Figure 6.7 shows the fd array of a task_struct and how it points to the file's file structure.
Linux can associate sets of file descriptors according to shared qualities, such as read-only or read-write. The fd_struct structure represents the file descriptor sets. The files_struct uses these sets to group its file descriptors:
-----------------------------------------------------------------------
include/linux/file.h
22 struct files_struct {
23 atomic_t count;
24 spinlock_t file_lock
25 int max_fds;
26 int max_fdset;
27 int next_fd;
28 struct file ** fd;
29 fd_set *close_on_exec;
30 fd_set *open_fds;
31 fd_set close_on_exec_init;
32 fd_set open_fds_init;
33 struct file * fd_array[NR_OPEN_DEFAULT];
34 };
-----------------------------------------------------------------------
Line 23
The count field exists because the files_struct can be referred to by multiple process descriptors, much like the fs_struct. This field is incremented in the kernel routine fget() and decremented in the kernel routine fput(). These functions are called during the file-closing process.
Line 25
The max_fds field keeps track of the maximum number of files that the process can have open. The default of max_fds is 32 as associated with NR_OPEN_DEFAULT size of the fd_array. When a file wants to open more than 32 files, this value is grown.
Line 26
The max_fdset field keeps track of the maximum number of file descriptors. Similar to max_fds, this field can be expanded if the total number of files the process has open exceeds its value.
Line 27
The next_fd field holds the value of the next file descriptor to be assigned. We see how it is manipulated through the opening and closing of files, but one thing should be understood: File descriptors are assigned in an incremental manner unless a previously assigned file descriptor's associated file is closed. In this case, the next_fd field is set to that value. Thus, file descriptors are assigned in a lowest available value manner.
Line 28
The fd array points to the open file object array. It defaults to fd_array, which holds 32 file descriptors. When a request for more than 32 file descriptors comes in, it points to a newly generated array.
Lines 3032
close_on_exec, open_fds, close_on_exec_init, and open_fds_init are all fields of type fd_set. We mentioned that the fd_set structure holds sets of file descriptors. Before explaining each field individually, we look at the fd_set structure.
The fd_set datatype can be traced back to a struct that holds an array of unsigned longs, each of which holds a file descriptor:
-----------------------------------------------------------------------
include/linux/types.h
22 typedef __kernel_fd_set fd_set;
-----------------------------------------------------------------------
The fd_set datatype is a type definition of __kernel_fd_set. This datatype structure holds an array of unsigned longs:
-----------------------------------------------------------------------
include/linux/posix_types.h
36 typedef struct {
37 unsigned long fds_bits [__FDSET_LONGS];
38 } __kernel_fd_set;
-----------------------------------------------------------------------
__FDSET_LONGS has a value of 32 on a 32-bit system and 16 on a 64-bit system, which ensures that fd_sets always has a bitmap of size 1,024. This is where __FDSET_LONGS is defined:
-----------------------------------------------------------------------
include/linux/posix_types.h
6 #undef __NFDBITS
7 #define __NFDBITS (8 * sizeof(unsigned long))
8
9 #undef __FD_SETSIZE
10 #define __FD_SETSIZE 1024
11
12 #undef __FDSET_LONGS
13 #define __FDSET_LONGS (__FD_SETSIZE/__NFDBITS)
-----------------------------------------------------------------------
Four macros are available for the manipulation of these file descriptor sets (see Table 6.8).
Table 6.8. File Descriptor Set MacrosMacro | Description |
|---|
FD_SET | Sets the file descriptor in the set. | FD_CLR | Clears the file descriptor from the set. | FD_ZERO | Clears the file descriptor set. | FD_ISSET | Returns if the file descriptor is set. |
Now, we look at the various fields.
6.3.2.1. close_on_exec
The close_on_exec field is a pointer to the set of file descriptors that are marked to be closed on exec(). It initially (and usually) points to the close_on_exec_init field. This changes if the number of file descriptors marked to be open on exec() grows beyond the size of the close_on_exec_init bit field.
6.3.2.2. open_fds
The open_fds field is a pointer to the set of file descriptors that are marked as open. Like close_on_exec, it initially points to the open_fds_init field and changes if the number of file descriptors marked as open grows beyond the size of open_fds_init bit field.
6.3.2.3. close_on_exec
The close_on_exec_init field holds the bit field that keeps track of the file descriptors of files that are to be closed on exec().
6.3.2.4. open_fds_init
The open_fds_init field holds the bit field that keeps track of the file descriptors of files that are open.
6.3.2.5. fd_array
The fd_array array pointer points to the first 32 open file descriptors.
The fs_struct structures are initialized by the INIT_FILES macro:
-----------------------------------------------------------------------
include/linux/init_task.h
6 #define INIT_FILES \
7 {
8 .count = ATOMIC_INIT(1),
9 .file_lock = SPIN_LOCK_UNLOCKED,
10 .max_fds = NR_OPEN_DEFAULT,
11 .max_fdset = __FD_SETSIZE,
12 .next_fd = 0,
13 .fd = &init_files.fd_array[0],
14 .close_on_exec = &init_files.close_on_exec_init,
15 .open_fds = &init_files.open_fds_init,
16 .close_on_exec_init = { { 0, } },
17 .open_fds_init = { { 0, } },
18 .fd_array = { NULL, }
19 }
-----------------------------------------------------------------------
Figure 6.11 illustrates what the fs_struct looks like after it is initialized.
-----------------------------------------------------------------------
include/linux/file.h
6 #define NR_OPEN_DEFAULT BITS_PER_LONG
-----------------------------------------------------------------------
The NR_OPEN_DEFAULT global definition is set to BITS_PER_LONG, which is 32 on 32-bit systems and 64 on 64-bit systems.
|
6.4. Page Cache
In the introductory sections, we mentioned that the page cache is an in-memory collection of pages. When data is frequently accessed, it is important to be able to quickly access the data. When data is duplicated and synchronized across two devices, one of which typically is smaller in storage size but allows much faster access than the other, we call it a cache. A page cache is how an operating system stores parts of the hard drive in memory for faster access. We now look at how it works and is implemented.
When you perform a write to a file on your hard drive, that file is broken into chunks called pages, that are swapped into memory (RAM). The operating system updates the page in memory and, at a later date, the page is written to disk.
If a page is copied from the hard drive to RAM (which is called swapping into memory), it can become either clean or dirty. A dirty page has been modified in memory but the modifications have not yet been written to disk. A clean page exists in memory in the same state that it exists on disk.
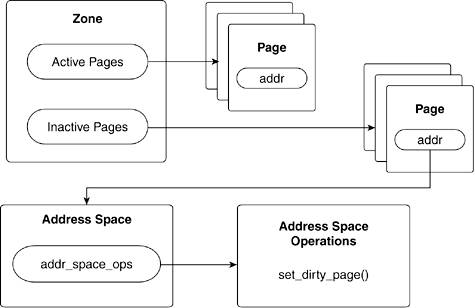
In Linux, the memory is divided into zones. Each zone has a list of active and inactive pages. When a page is inactive for a certain amount of time, it gets swapped out (written back to disk) to free memory. Each page in the zones list has a pointer to an address_space. Each address_space has a pointer to an address_space_operations structure. Pages are marked dirty by calling the set_dirty_page() function of the address_space_operation structure. Figure 6.12 illustrates this dependency.
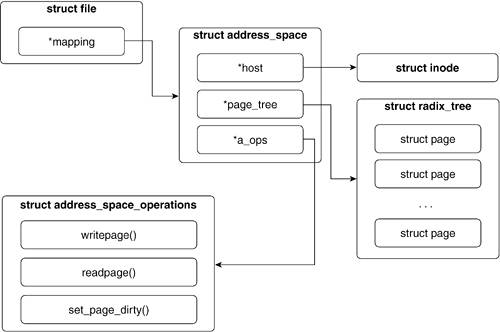
6.4.1. address_space Structure
The core of the page cache is the address_space object. Let's take a close look at it.
-----------------------------------------------------------------------
include/linux/fs.h
326 struct address_space {
327 struct inode *host; /* owner: inode, block_device */
328 struct radix_tree_root page_tree; /* radix tree of all pages */
329 spinlock_t tree_lock; /* and spinlock protecting it */
330 unsigned long nrpages; /* number of total pages */
331 pgoff_t writeback_index;/* writeback starts here */
332 struct address_space_operations *a_ops; /* methods */
333 struct prio_tree_root i_mmap; /* tree of private mappings */
334 unsigned int i_mmap_writable;/* count VM_SHARED mappings */
335 struct list_head i_mmap_nonlinear;/*list VM_NONLINEAR mappings */
336 spinlock_t i_mmap_lock; /* protect tree, count, list */
337 atomic_t truncate_count; /* Cover race condition with truncate */
338 unsigned long flags; /* error bits/gfp mask */
339 struct backing_dev_info *backing_dev_info; /* device readahead, etc */
340 spinlock_t private_lock; /* for use by the address_space */
341 struct list_head private_list; /* ditto */
342 struct address_space *assoc_mapping; /* ditto */
343 };
-----------------------------------------------------------------------
The inline comments of the structure are fairly descriptive. Some additional explanation might help in understanding how the page cache operates.
Usually, an address_space is associated with an inode and the host field points to this inode. However, the generic intent of the page cache and address space structure need not require this field. It could be NULL if the address_space is associated with a kernel object that is not an inode.
The address_space structure has a field that should be intuitively familiar to you by now: address_space_operations. Like the file structure file_operations, address_space_operations contains information about what operations are valid for this address_space.
-----------------------------------------------------------------------
include/linux/fs.h
297 struct address_space_operations {
298 int (*writepage)(struct page *page, struct writeback_control *wbc);
299 int (*readpage)(struct file *, struct page *);
300 int (*sync_page)(struct page *);
301
302 /* Write back some dirty pages from this mapping. */
303 int (*writepages)(struct address_space *, struct writeback_control *);
304
305 /* Set a page dirty */
306 int (*set_page_dirty)(struct page *page);
307
308 int (*readpages)(struct file *filp, struct address_space *mapping,
309 struct list_head *pages, unsigned nr_pages);
310
311 /*
312 * ext3 requires that a successful prepare_write() call be followed
313 * by a commit_write() call - they must be balanced
314 */
315 int (*prepare_write)(struct file *, struct page *, unsigned, unsigned);
316 int (*commit_write)(struct file *, struct page *, unsigned, unsigned);
317 /* Unfortunately this kludge is needed for FIBMAP. Don't use it */
318 sector_t (*bmap)(struct address_space *, sector_t);
319 int (*invalidatepage) (struct page *, unsigned long);
320 int (*releasepage) (struct page *, int);
321 ssize_t (*direct_IO)(int, struct kiocb *, const struct iovec *iov,
322 loff_t offset, unsigned long nr_segs);
323 };
-----------------------------------------------------------------------
These functions are reasonably straightforward. readpage() and writepage() read and write pages associated with an address space, respectively. Multiple pages can be written and read via readpages() and writepages(). Journaling file systems, such as ext3, can provide functions for prepare_write() and commit_write().
When the kernel checks the page cache for a page, it must be blazingly fast. As such, each address space has a radix_tree, which performs a quick search to determine if the page is in the page cache or not.
Figure 6.13 illustrates how files, inodes, address spaces, and pages relate to each other; this figure is useful for the upcoming analysis of the page cache code.
6.4.2. buffer_head Structure
Each sector on a block device is represented by the Linux kernel as a buffer_head structure. A buffer_head contains all the information necessary to map a physical sector to a buffer in physical memory. The buffer_head structure is illustrated in Figure 6.14.
-----------------------------------------------------------------------
include/linux/buffer_head.h
47 struct buffer_head {
48 /* First cache line: */
49 unsigned long b_state; /* buffer state bitmap (see above) */
50 atomic_t b_count; /* users using this block */
51 struct buffer_head *b_this_page;/* circular list of page's buffers */
52 struct page *b_page; /* the page this bh is mapped to */
53
54 sector_t b_blocknr; /* block number */
55 u32 b_size; /* block size */
56 char *b_data; /* pointer to data block */
57
58 struct block_device *b_bdev;
59 bh_end_io_t *b_end_io; /* I/O completion */
60 void *b_private; /* reserved for b_end_io */
61 struct list_head b_assoc_buffers; /* associated with another mapping */
62 };
-----------------------------------------------------------------------
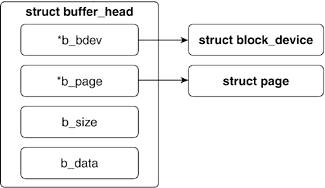
The physical sector that a buffer_head structure refers to is logical block b_blocknr on device b_dev.
The physical memory that a buffer_head structure refers to is a block of memory starting at b_data of b_size bytes. This memory block is within the physical page of b_page.
The other definitions within the buffer_head structure are used for managing housekeeping tasks for how the physical sector is mapped to the physical memory. (Because this is a digression on bio structures and not buffer_head structures, refer to mpage.c for more detailed information on struct buffer_head.)
As mentioned in Chapter 4, each physical memory page in the Linux kernel is represented by a struct page. A page is composed of a number of I/O blocks. As each I/O block can be no larger than a page (although it can be smaller), a page is composed of one or more I/O blocks.
In older versions of Linux, block I/O was only done via buffers, but in 2.6, a new way was developed, using bio structures. The new way allows the Linux kernel to group block I/O together in a more manageable way.
Suppose we write a portion of the top of a text file and the bottom of a text file. This update would likely need two buffer_head structures for the data transfer: one that points to the top and one that points to the bottom. A bio structure allows file operations to bundle discrete chunks together in a single structure. This alternate way of looking at buffers and pages occurs by looking at the contiguous memory segments of a buffer. The bio_vec structure represents a contiguous memory segment in a buffer. The bio_vec structure is illustrated in Figure 6.15.
-----------------------------------------------------------------------
include/linux/bio.h
47 struct bio_vec {
48 struct page *bv_page;
49 unsigned int bv_len;
50 unsigned int bv_offset;
51 };
-----------------------------------------------------------------------
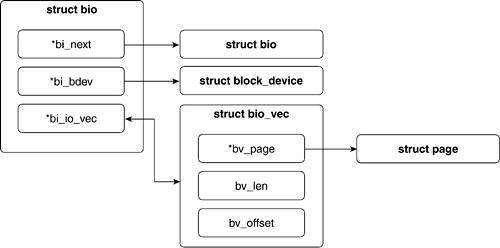
The bio_vec structure holds a pointer to a page, the length of the segment, and the offset of the segment within the page.
A bio structure is composed of an array of bio_vec structures (along with other housekeeping fields). Thus, a bio structure represents a number of contiguous memory segments of one or more buffers on one or more pages.
6.5. VFS System Calls and the Filesystem Layer
Until this point, we covered all the structures that are associated with the VFS and the page cache. Now, we focus on two of the system calls used in file manipulation and trace their execution down to the kernel level. We see how the open(), close(), read(), and write() system calls make use of the structures previously described.
We mentioned that in the VFS, files are treated as complete abstractions. You can open, read, write, or close a file, but the specifics of what physically happens are unimportant to the VFS layer. Chapter 5 covers these specifics.
Hooked into the VFS is the filesystem-specific layer that translates the VFS' file I/O to pages and blocks. Because you can have many specific filesystem types on a computer system, like an ext2 formatted hard disk and an iso9660 cdrom, the filesystem layer can be divided into two main sections: the generic filesystem operations and the specific filesystem operations (refer to Figure 6.3).
Following our top-down approach, this section traces a read and write request from the VFS call of read(), or write(), tHRough the filesystem layer until a specific block I/O request is handed off to the block device driver. In our travels, we move between the generic filesystem and specific filesystem layer. We use the ext2 filesystem driver as the example of the specific filesystem layer, but keep in mind that different filesystem drivers could be accessed depending on what file is being acted upon. As we progress, we will also encounter the page cache, which is a construct within Linux that is positioned in the generic filesystem layer. In older versions of Linux, a buffer cache and page cache exist, but in the 2.6 kernel, the page cache has consumed any buffer cache functionality.
6.5.1. open ()
When a process wants to manipulate the contents of a file, it issues the open()system call:
-----------------------------------------------------------------------
synopsis
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
int creat(const char *pathname, mode_t mode);
-----------------------------------------------------------------------
The open syscall takes as its arguments the pathname of the file, the flags to identify access mode of the file being opened, and the permission bit mask (if the file is being created). open() returns the file descriptor of the opened file (if successful) or an error code (if it fails).
The flags parameter is formed by bitwise ORing one or more of the constants defined in include/linux/fcntl.h. Table 6.9 lists the flags for open() and the corresponding value of the constant. Only one of O_RDONLY, O_WRONLY, or O_RDWR flags has to be specified. The additional flags are optional.
Table 6.9. open() FlagsFlag Name | Value | Description |
|---|
O_RDONLY | 0 | Opens file for reading. | O_WRONLY | 1 | Opens file for writing. | O_RDWR | 2 | Opens file for reading and writing. | O_CREAT | 100 | Indicates that, if the file does not exist, it should be created. The creat() function is equivalent to the open() function with this flag set. | O_EXCL | 200 | Used in conjunction with O_CREAT, this indicates the open() should fail if the file does exist. | O_NOCTTY | 400 | In the case that pathname refers to a terminal device, the process should not consider it a controlling terminal. | O_TRUNC | 0x1000 | If the file exists, truncate it to 0 bytes. | O_APPEND | 0x2000 | Writes at the end of the file. | O_NONBLOCK | 0x4000 | Opens the file in non-blocking mode. | O_NDELAY | 0x4000 | Same value as O_NONBLOCK. | O_SYNC | 0x10000 | Writes to the file have to wait for the completion of physical I/O. Applied to files on block devices. | O_DIRECT | 0x20000 | Minimizes cache buffering on I/O to the file. | O_LARGEFILE | 0x100000 | The large filesystem allows files of sizes greater than can be represented in 31 bits. This ensures they can be opened. | O_DIRECTORY | 0x200000 | If the pathname does not indicate a directory, the open is to fail. | O_NOFOLLOW | 0x400000 | If the pathname is a symbolic link, the open is to fail. |
Let's look at the system call:
-----------------------------------------------------------------------
fs/open.c
927 asmlinkage long sys_open (const char __user * filename, int flags, int mode)
928 {
929 char * tmp;
930 int fd, error;
931
932 #if BITS_PER_LONG != 32
933 flags |= O_LARGEFILE;
934 #endif
935 tmp = getname(filename);
936 fd = PTR_ERR(tmp);
937 if (!IS_ERR(tmp)) {
938 fd = get_unused_fd();
939 if (fd >= 0) {
940 struct file *f = filp_open(tmp, flags, mode);
941 error = PTR_ERR(f);
942 if (IS_ERR(f))
943 goto out_error;
944 fd_install(fd, f);
945 }
946 out:
947 putname(tmp);
948 }
949 return fd;
950
951 out_error:
952 put_unused_fd(fd);
953 fd = error;
954 goto out;
955 }
-----------------------------------------------------------------------
Lines 932934
Verify if our system is non-32-bit. If so, enable the large filesystem support flag O_LARGEFILE. This allows the function to open files with sizes greater than those represented by 31 bits.
Line 935
The getname() routine copies the filename from user space to kernel space by invoking strncpy_from_user().
Line 938
The get_unused_fd() routine returns the first available file descriptor (or index into fd array: current->files->fd) and marks it busy. The local variable fd is set to this value.
Line 940
The filp_open() function performs the bulk of the open syscall work and returns the file structure that will associate the process with the file. Let's take a closer look at the filp_open() routine:
-----------------------------------------------------------------------
fs/open.c
740 struct file *filp_open(const char * filename, int flags, int mode)
741 {
742 int namei_flags, error;
743 struct nameidata nd;
744
745 namei_flags = flags;
746 if ((namei_flags+1) & O_ACCMODE)
747 namei_flags++;
748 if (namei_flags & O_TRUNC)
749 namei_flags |= 2;
750
751 error = open_namei(filename, namei_flags, mode, &nd);
752 if (!error)
753 return dentry_open(nd.dentry, nd.mnt, flags);
754
755 return ERR_PTR(error);
-----------------------------------------------------------------------
Lines 745749
The pathname lookup functions, such as open_namei(), expect the access mode flags encoded in a specific format that is different from the format used by the open system call. These lines copy the access mode flags into the namei_flags variable and format the access mode flags for interpretation by open_namei().
The main difference is that, for pathname lookup, it can be the case that the access mode might not require read or write permission. This "no permission" access mode does not make sense when trying to open a file and is thus not included under the open system call flags. "No permission" is indicated by the value of 00. Read permission is then indicated by setting the value of the low-order bit to 1 whereas write permission is indicated by setting the value of the high-order bit to 1. The open system call flags for O_RDONLY, O_WRONLY, and O_RDWR evaluate to 00, 01, and 02, respectively as seen in include/asm/fcntl.h.
The namei_flags variable can extract the access mode by logically bit ANDing it with the O_ACCMODE variable. This variable holds the value of 3 and evaluates to true if the variable to be ANDed with it holds a value of 1, 2, or 3. If the open system call flag was set to O_RDONLY, O_WRONLY, and O_RDWR, adding a 1 to this value translates it into the pathname lookup format and evaluates to true when ANDed with O_ACCMODE. The second check just assures that if the open system call flag is set to allow for file truncation, the high-order bit is set in the access mode specifying write access.
Line 751
The open_namei() routine performs the pathname lookup, generates the associated nameidata structure, and derives the corresponding inode.
Line 753
The dentry_open() is a wrapper routine around dentry_open_it(), which creates and initializes the file structure. It creates the file structure via a call to the kernel routine get_empty_filp(). This routine returns ENFILE if the files_stat.nr_files is greater than or equal to files_stat.max_files. This case indicates that the system's limit on the total number of open files has been reached.
Let's look at the dentry_open_it() routine:
-----------------------------------------------------------------------
fs/open.c
844 struct file *dentry_open_it(struct dentry *dentry, struct 845 vfsmount *mnt, int
 flags, struct lookup_intent *it)
846 {
847 struct file * f;
848 struct inode *inode;
849 int error;
850
851 error = -ENFILE;
852 f = get_empty_filp();
...
855 f->f_flags = flags;
856 f->f_mode = (flags+1) & O_ACCMODE;
857 f->f_it = it;
858 inode = dentry->d_inode;
859 if (f->f_mode & FMODE_WRITE) {
860 error = get_write_access(inode);
861 if (error)
862 goto cleanup_file;
863 }
...
866 f->f_dentry = dentry;
867 f->f_vfsmnt = mnt;
868 f->f_pos = 0;
869 f->f_op = fops_get(inode->i_fop);
870 file_move(f, &inode->i_sb->s_files);
871
872 if (f->f_op && f->f_op->open) {
873 error = f->f_op->open(inode,f);
874 if (error)
875 goto cleanup_all;
876 intent_release(it);
877 }
...
891 return f;
...
907 }
----------------------------------------------------------------------- flags, struct lookup_intent *it)
846 {
847 struct file * f;
848 struct inode *inode;
849 int error;
850
851 error = -ENFILE;
852 f = get_empty_filp();
...
855 f->f_flags = flags;
856 f->f_mode = (flags+1) & O_ACCMODE;
857 f->f_it = it;
858 inode = dentry->d_inode;
859 if (f->f_mode & FMODE_WRITE) {
860 error = get_write_access(inode);
861 if (error)
862 goto cleanup_file;
863 }
...
866 f->f_dentry = dentry;
867 f->f_vfsmnt = mnt;
868 f->f_pos = 0;
869 f->f_op = fops_get(inode->i_fop);
870 file_move(f, &inode->i_sb->s_files);
871
872 if (f->f_op && f->f_op->open) {
873 error = f->f_op->open(inode,f);
874 if (error)
875 goto cleanup_all;
876 intent_release(it);
877 }
...
891 return f;
...
907 }
-----------------------------------------------------------------------
Line 852
The file struct is assigned by way of the call to get_empty_filp().
Lines 855856
The f_flags field of the file struct is set to the flags passed in to the open system call. The f_mode field is set to the access modes passed to the open system call, but in the format expected by the pathname lookup functions.
Lines 866869
The files struct's f_dentry field is set to point to the dentry struct that is associated with the file's pathname. The f_vfsmnt field is set to point to the vmfsmount struct for the filesystem. f_pos is set to 0, which indicates that the starting position of the file_offset is at the beginning of the file. The f_op field is set to point to the table of operations pointed to by the file's inode.
Line 870
The file_move() routine is called to insert the file structure into the filesystem's superblock list of file structures representing open files.
Lines 872877
This is where the next level of the open function occurs. It is called here if the file has more file-specific functionality to perform to open the file. It is also called if the file operations table for the file contains an open routing.
This concludes the dentry_open_it() routine.
By the end of filp_open(), we will have a file structure allocated, inserted at the head of the superblock's s_files field, with f_dentry pointing to the dentry object, f_vfsmount pointing to the vfsmount object, f_op pointing to the inode's i_fop file operations table, f_flags set to the access flags, and f_mode set to the permission mode passed to the open() call.
Line 944
The fd_install() routine sets the fd array pointer to the address of the file object returned by filp_open(). That is, it sets current->files->fd[fd].
Line 947
The putname() routine frees the kernel space allocated to store the filename.
Line 949
The file descriptor fd is returned.
Line 952
The put_unused_fd() routine clears the file descriptor that has been allocated. This is called when a file object failed to be created.
To summarize, the hierarchical call of the open() syscall process looks like this:
sys_open:
getname().
Moves filename to kernel space
get_unused_fd().
Gets next available file descriptor
filp_open().
Creates the nameidata struct
open_namei().
Initializes the nameidata struct
dentry_open().
Creates and initializes the file object
fd_install().
Sets current->files->fd[fd] to the file object
putname().
Deallocates kernel space for filename
Figure 6.16 illustrates the structures that are initialized and set and identifies the routines where this was done.
Table 6.10 shows some of the sys_open() return errors and the kernel routines that find them.
Table 6.10. sys_open() ErrorsError Code | Description | Function Returning Error |
|---|
ENAMETOOLONG | Pathname too long. | getname() | ENOENT | File does not exist (and flag O_CREAT not set). | getname() | EMFILE | Process has maximum number of files open. | get_unused_fd() | ENFILE | System has maximum number of files open. | get_unused_filp() |
6.5.2. close ()
After a process finishes with a file, it issues the close() system call:
synopsis
#include <unistd.h>
int close(int fd);
-----------------------------------------------------------------------
The close system call takes as parameter the file descriptor of the file to be closed. In standard C programs, this call is made implicitly upon program termination. Let's delve into the code for sys_close():
-----------------------------------------------------------------------
fs/open.c
1020 asmlinkage long sys_close(unsigned int fd)
1021 {
1022 struct file * filp;
1023 struct files_struct *files = current->files;
1024
1025 spin_lock(&files->file_lock);
1026 if (fd >= files->max_fds)
1027 goto out_unlock;
1028 filp = files->fd[fd];
1029 if (!filp)
1030 goto out_unlock;
1031 files->fd[fd] = NULL;
1032 FD_CLR(fd, files->close_on_exec);
1033 __put_unused_fd(files, fd);
1034 spin_unlock(&files->file_lock);
1035 return filp_close(filp, files);
1036
1037 out_unlock:
1038 spin_unlock(&files->file_lock);
1039 return -EBADF;
1040 }
-----------------------------------------------------------------------
Line 1023
The current task_struct's files field point at the files_struct that corresponds to our file.
Lines 10251030
These lines begin by locking the file so as to not run into synchronization problems. We then check that the file descriptor is valid. If the file descriptor number is greater than the highest allowable file number for that file, we remove the lock and return the error EBADF. Otherwise, we acquire the file structure address. If the file descriptor index does not yield a file structure, we also remove the lock and return the error as there would be nothing to close.
Lines 10311032
Here, we set the current->files->fd[fd] to NULL, removing the pointer to the file object. We also clear the file descriptor's bit in the file descriptor set referred to by files->close_on_exec. Because the file descriptor is closed, the process need not worry about keeping track of it in the case of a call to exec().
Line 1033
The kernel routine __put_unused_fd() clears the file descriptor's bit in the file descriptor set files->open_fds because it is no longer open. It also does something that assures us of the "lowest available index" assignment of file descriptors:
-----------------------------------------------------------------------
fs/open.c
897 static inline void __put_unused_fd(struct files_struct *files, unsigned int fd)
898 {
899 __FD_CLR(fd, files->open_fds);
890 if (fd < files->next_fd)
891 files->next_fd = fd;
892 }
-----------------------------------------------------------------------
Lines 890891
The next_fd field holds the value of the next file descriptor to be assigned. If the current file descriptor's value is less than that held by files->next_fd, this field will be set to the value of the current file descriptor instead. This assures that file descriptors are assigned on the basis of the lowest available value.
Lines 10341035
The lock on the file is now released and the control is passed to the filp_close() function that will be in charge of returning the appropriate value to the close system call. The filp_close() function performs the bulk of the close syscall work. Let's take a closer look at the filp_close() routine:
-----------------------------------------------------------------------
fs/open.c
987 int filp_close(struct file *filp, fl_owner_t id)
988 {
989 int retval;
990 /* Report and clear outstanding errors */
991 retval = filp->f_error;
992 if (retval)
993 filp->f_error = 0;
994
995 if (!file_count(filp)) {
996 printk(KERN_ERR "VFS: Close: file count is 0\n");
997 return retval;
998 }
999
1000 if (filp->f_op && filp->f_op->flush) {
1001 int err = filp->f_op->flush(filp);
1002 if (!retval)
1003 retval = err;
1004 }
1005
1006 dnotify_flush(filp, id);
1007 locks_remove_posix(filp, id);
1008 fput(filp);
1009 return retval;
1010 }
-----------------------------------------------------------------------
Lines 991993
These lines clear any outstanding errors.
Lines 995997
This is a sanity check on the conditions necessary to close a file. A file with a file_count of 0 should already be closed. Hence, in this case, filp_close returns an error.
Lines 10001001
Invokes the file operation flush() (if it is defined). What this does is determined by the particular filesystem.
Line 1008
fput() is called to release the file structure. The actions performed by this routine include calling file operation release(), removing the pointer to the dentry and vfsmount objects, and finally, releasing the file object.
The hierarchical call of the close() syscall process looks like this:
sys_close():
__put_unused_fd().
Returns file descriptor to the available pool
filp_close().
Prepares file object for clearing
fput().
Clears file object
Table 6.11 shows some of the sys_close() return errors and the kernel routines that find them.
Table 6.11. sys_close() ErrorsError | Function | Description |
|---|
EBADF | sys_close() | Invalid file descriptor |
6.5.3. read()
When a user level program calls read(), Linux translates this to a system call, sys_read():
-----------------------------------------------------------------------
fs/read_write.c
272 asmlinkage ssize_t sys_read(unsigned int fd, char __user * buf, size_t count)
273 {
274 struct file *file;
275 ssize_t ret = -EBADF;
276 int fput_needed;
277
278 file = fget_light(fd, &fput_needed);
279 if (file) {
280 ret = vfs_read(file, buf, count, &file->f_pos);
281 fput_light(file, fput_needed);
282 }
283
284 return ret;
285 }
-----------------------------------------------------------------------
Line 272
sys_read() takes a file descriptor, a user-space buffer pointer, and a number of bytes to read from the file into the buffer.
Lines 273282
A file lookup is done to translate the file descriptor to a file pointer with fget_light(). We then call vfs_read(), which does all the main work. Each fget_light() needs to be paired with fput_light(,) so we do that after our vfs_read() finishes.
The system call, sys_read(), has passed control to vfs_read(), so let's continue our trace:
-----------------------------------------------------------------------
fs/read_write.c
200 ssize_t vfs_read(struct file *file, char __user *buf, size_t count,
loff_t *pos)
201 {
202 struct inode *inode = file->f_dentry->d_inode;
203 ssize_t ret;
204
205 if (!(file->f_mode & FMODE_READ))
206 return -EBADF;
207 if (!file->f_op || (!file->f_op->read && \ !file->f_op->aio_read))
208 return -EINVAL;
209
210 ret = locks_verify_area(FLOCK_VERIFY_READ, inode,
file, *pos, count);
211 if (!ret) {
212 ret = security_file_permission (file, MAY_READ);
213 if (!ret) {
214 if (file->f_op->read)
215 ret = file->f_op->read(file,
buf, count, pos);
216 else
217 ret = do_sync_read(file, buf,
count, pos);
218 if (ret > 0)
219 dnotify_parent(file->f_dentry,
DN_ACCESS);
220 }
221 }
222
223 return ret;
224 }
-----------------------------------------------------------------------
Line 200
The first three parameters are all passed via, or are translations from, the original sys_read() parameters. The fourth parameter is the offset within file, where the read should start. This could be non-zero if vfs_read() is called explicitly because it could be called from within the kernel.
Line 202
We store a pointer to the file's inode.
Lines 205208
Basic checking is done on the file operations structure to ensure that read or asynchronous read operations have been defined. If no read operation is defined, or if the operations table is missing, the function returns the EINVAL error at this point. This error indicates that the file descriptor is attached to a structure that cannot be used for reading.
Lines 210214
We verify that the area to be read is not locked and that the file is authorized to be read. If it is not, we notify the parent of the file (on lines 218219).
Lines 215217
These are the guts of vfs_read(). If the read file operation has been defined, we call it; otherwise, we call do_sync_read().
In our tracing, we follow the standard file operation read and not the do_sync_read() function. Later, it becomes clear that both calls eventually reach the same underlying point.
6.5.3.1. Moving from the Generic to the Specific
This is our first encounter with one of the many abstractions where we move between the generic filesystem layer and the specific filesystem layer. Figure 6.17 illustrates how the file structure points to the specific filesystem table or operations. Recall that when read_inode() is called, the inode information is filled in, including having the fop field point to the appropriate table of operations defined by the specific filesystem implementation (for example, ext2).
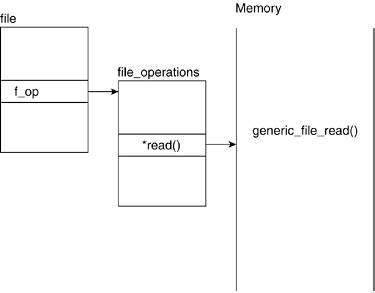
When a file is created, or mounted, the specific filesystem layer initializes its file operations structure. Because we are operating on a file on an ext2 filesystem, the file operations structure is as follows:
-----------------------------------------------------------------------
fs/ext2/file.c
42 struct file_operations ext2_file_operations = {
43 .llseek = generic_file_llseek,
44 .read = generic_file_read,
45 .write = generic_file_write,
46 .aio_read = generic_file_aio_read,
47 .aio_write = generic_file_aio_write,
48 .ioctl = ext2_ioctl,
49 .mmap = generic_file_mmap,
50 .open = generic_file_open,
51 .release = ext2_release_file,
52 .fsync = ext2_sync_file,
53 .readv = generic_file_readv,
54 .writev = generic_file_writev,
55 .sendfile = generic_file_sendfile,
56 };
-----------------------------------------------------------------------
You can see that for nearly every file operation, the ext2 filesystem has decided that the Linux defaults are acceptable. This leads us to ask when a filesystem would want to implement its own file operations. When a filesystem is sufficiently unlike a UNIX filesystem, extra steps might be necessary to allow Linux to interface with it. For example, MSDOS- or FAT-based filesystems need to implement their own write but can use the generic read.
Discovering that the specific filesystem layer for ext2 passes control to the generic filesystem layer, we now examine generic_file_read():
-----------------------------------------------------------------------
mm/filemap.c
924 ssize_t
925 generic_file_read(struct file *filp, char __user *buf, size_t count, loff_t *ppos)
926 {
927 struct iovec local_iov = { .iov_base = buf, .iov_len = count };
928 struct kiocb kiocb;
929 ssize_t ret;
930
931 init_sync_kiocb(&kiocb, filp);
932 ret = __generic_file_aio_read(&kiocb, &local_iov, 1, ppos);
933 if (-EIOCBQUEUED == ret)
934 ret = wait_on_sync_kiocb(&kiocb);
935 return ret;
936 }
937
938 EXPORT_SYMBOL(generic_file_read);
-----------------------------------------------------------------------
Lines 924925
Notice that the same parameters are simply being passed along from the upper-level reads. We have filp, the file pointer; buf, the pointer to the memory buffer where the file will be read into; count, the number of characters to read; and ppos, the position within the file to begin reading from.
Line 927
An iovec structure is created that contains the address and length of the user space buffer that the results of the read are to be stored in.
Lines 928 and 931
A kiocb structure is initialized using the file pointer. (kiocb stands for kernel I/O control block.)
Line 932
The bulk of the read is done in the generic asynchronous file read function.
|
kiocb and iovec are two datatypes that facilitate asynchronous I/O operations within the Linux kernel.
Asynchronous I/O is desirable when a process wishes to perform an input or output operation without immediately waiting for the result of the operation. It is extremely desirable for high I/O environments, as you can allow the device the opportunity to order and schedule the I/O requests instead of the process.
In Linux, an I/O vector (iovec) represents an address range of memory and is defined as
-------------------------------------------------------------------------
include/linux/uio.h
20 struct iovec
21 {
22 void __user *iov_base; /* BSD uses caddr_t (1003.1g requires
void *) */
23 __kernel_size_t iov_len; /* Must be size_t (1003.1g) */
24 };
-------------------------------------------------------------------------
This is simply a pointer to a section of memory and the length of the memory.
The kernel I/O control block (kiocb) is a structure that is required to help manage how and when the I/O vector gets operated upon asynchronously.
__generic_file_aio_read() function uses the kiocb and iovec structures to read the page_cache directly. |
Lines 933935
After we send off the read, we wait until the read finishes and then return the result of the read operation.
Recall the do_sync_read() path in vfs_read(); it would have eventually called this same function via another path. Let's continue the trace of file I/O by examining __generic_file_aio_read():
-----------------------------------------------------------------------
mm/filemap.c
835 ssize_t
836 __generic_file_aio_read(struct kiocb *iocb,
const struct iovec *iov,
837 unsigned long nr_segs, loff_t *ppos)
838 {
839 struct file *filp = iocb->ki_filp;
840 ssize_t retval;
841 unsigned long seg;
842 size_t count;
843
844 count = 0;
845 for (seg = 0; seg < nr_segs; seg++) {
846 const struct iovec *iv = &iov[seg];
...
852 count += iv->iov_len;
853 if (unlikely((ssize_t)(count|iv->iov_len) <
0))
854 return -EINVAL;
855 if (access_ok(VERIFY_WRITE, iv->iov_base,
iv->iov_len))
856 continue;
857 if (seg == 0)
858 return -EFAULT;
859 nr_segs = seg;
860 count -= iv->iov_len
861 break;
862 }
...
-----------------------------------------------------------------------
Lines 835842
Recall that nr_segs was set to 1 by our caller and that iocb and iov contain the file pointer and buffer information. We immediately extract the file pointer from iocb.
Lines 845862
This for loop verifies that the iovec struct passed is composed of valid segments. Recall that it contains the user space buffer information.
-----------------------------------------------------------------------
mm/filemap.c
...
863
864 /* coalesce the iovecs and go direct-to-BIO for O_DIRECT */
865 if (filp->f_flags & O_DIRECT) {
866 loff_t pos = *ppos, size;
867 struct address_space *mapping;
868 struct inode *inode;
869
870 mapping = filp->f_mapping;
871 inode = mapping->host;
872 retval = 0;
873 if (!count)
874 goto out; /* skip atime */
875 size = i_size_read(inode);
876 if (pos < size) {
877 retval = generic_file_direct_IO(READ, iocb,
878 iov, pos, nr_segs);
879 if (retval >= 0 && !is_sync_kiocb(iocb))
880 retval = -EIOCBQUEUED;
881 if (retval > 0)
882 *ppos = pos + retval;
883 }
884 file_accessed(filp);
885 goto out;
886 }
...
-----------------------------------------------------------------------
Lines 863886
This section of code is only entered if the read is direct I/O. Direct I/O bypasses the page cache and is a useful property of certain block devices. For our purposes, however, we do not enter this section of code at all. Most file I/O takes our path as the page cache, which we describe soon, which is much faster than the underlying block device.
-----------------------------------------------------------------------
mm/filemap.c
...
887
888 retval = 0;
889 if (count) {
890 for (seg = 0; seg < nr_segs; seg++) {
891 read_descriptor_t desc;
892
893 desc.written = 0;
894 desc.buf = iov[seg].iov_base;
895 desc.count = iov[seg].iov_len;
896 if (desc.count == 0)
897 continue;
898 desc.error = 0;
899 do_generic_file_read(filp,ppos,&desc,file_read_actor);
900 retval += desc.written;
901 if (!retval) {
902 retval = desc.error;
903 break;
904 }
905 }
906 }
907 out:
08 return retval;
909 }
-----------------------------------------------------------------------
Lines 889890
Because our iovec is valid and we have only one segment, we execute this for loop once only.
Lines 891898
We translate the iovec structure into a read_descriptor_t structure. The read_descriptor_t structure keeps track of the status of the read. Here is the description of the read_descriptor_t structure:
-----------------------------------------------------------------------
include/linux/fs.h
837 typedef struct {
838 size_t written;
839 size_t count;
840 char __user * buf;
841 int error;
842 } read_descriptor_t;
-----------------------------------------------------------------------
Line 838
The field written keeps a running count of the number of bytes transferred.
Line 839
The field count keeps a running count of the number of bytes left to be transferred.
Line 840
The field buf holds the current position into the buffer.
Line 841
The field error holds any error code encountered during the read operation.
Lines 899
We pass our new read_descriptor_t structure desc to do_generic_file_read(), along with our file pointer filp and our position ppos. file_read_actor() is a function that copies a page to the user space buffer located in desc.
Lines 900909
The amount read is calculated and returned to the caller.
At this point in the read() internals, we are about to access the page cache and determine if the sections of the file we want to read already exist in RAM, so we don't have to directly access the block device.
6.5.3.2. Tracing the Page Cache
Recall that the last function we encountered passed a file pointer filp, an offset ppos, a read_descriptor_t desc, and a function file_read_actor into do_generic_file_read().
-----------------------------------------------------------------------
include/linux/fs.h
1420 static inline void do_generic_file_read(struct file * filp, loff_t *ppos,
1421 read_descriptor_t * desc,
1422 read_actor_t actor)
1423 {
1424 do_generic_mapping_read(filp->f_mapping,
1425 &filp->f_ra,
1426 filp,
1427 ppos,
1428 desc,
1429 actor);
1430 }
-----------------------------------------------------------------------
Lines 14201430
do_generic_file_read() is simply a wrapper to do_generic_mapping_read(). filp->f_mapping is a pointer to an address_space object and filp->f_ra is a structure that holds the address of the file's read-ahead state.
So, we've transformed our read of a file into a read of the page cache via the address_space object in our file pointer. Because do_generic_mapping_read() is an extremely long function with a number of separate cases, we try to make the analysis of the code as painless as possible.
-----------------------------------------------------------------------
mm/filemap.c
645 void do_generic_mapping_read(struct address_space *mapping,
646 struct file_ra_state *_ra,
647 struct file * filp,
648 loff_t *ppos,
649 read_descriptor_t * desc,
650 read_actor_t actor)
651 {
652 struct inode *inode = mapping->host;
653 unsigned long index, offset;
654 struct page *cached_page;
655 int error;
656 struct file_ra_state ra = *_ra;
657
658 cached_page = NULL;
659 index = *ppos >> PAGE_CACHE_SHIFT;
660 offset = *ppos & ~PAGE_CACHE_MASK;
-----------------------------------------------------------------------
Line 652
We extract the inode of the file we're reading from address_space.
Lines 658660
We initialize cached_page to NULL until we can determine if it exists within the page cache. We also calculate index and offset based on page cache constraints. The index corresponds to the page number within the page cache, and the offset corresponds to the displacement within that page. When the page size is 4,096 bytes, a right bit shift of 12 on the file pointer yields the index of the page.
"The page cache can [be] done in larger chunks than one page, because it allows for more efficient throughput" (linux/pagemap.h). PAGE_CACHE_SHIFT and PAGE_CACHE_MASK are settings that control the structure and size of the page cache:
-----------------------------------------------------------------------
mm/filemap.c
661
662 for (;;) {
663 struct page *page;
664 unsigned long end_index, nr, ret;
665 loff_t isize = i_size_read(inode);
666
667 end_index = isize >> PAGE_CACHE_SHIFT;
668
669 if (index > end_index)
670 break;
671 nr = PAGE_CACHE_SIZE;
672 if (index == end_index) {
673 nr = isize & ~PAGE_CACHE_MASK;
674 if (nr <= offset)
675 break;
676 }
677
678 cond_resched();
679 page_cache_readahead(mapping, &ra, filp, index);
680
681 nr = nr - offset;
-----------------------------------------------------------------------
Lines 662681
This section of code iterates through the page cache and retrieves enough pages to fulfill the bytes requested by the read command.
-----------------------------------------------------------------------
mm/filemap.c
682 find_page:
683 page = find_get_page(mapping, index);
684 if (unlikely(page == NULL)) {
685 handle_ra_miss(mapping, &ra, index);
686 goto no_cached_page;
687 }
688 if (!PageUptodate(page))
689 goto page_not_up_to_date;
-----------------------------------------------------------------------
Lines 682689
We attempt to find the first page required. If the page is not in the page cache, we jump to the no_cached_page label. If the page is not up to date, we jump to the page_not_up_to_date label. find_get_page() uses the address space's radix tree to find the page at index, which is the specified offset.
-----------------------------------------------------------------------
mm/filemap.c
690 page_ok:
691 /* If users can be writing to this page using arbitrary
692 * virtual addresses, take care about potential aliasing
693 * before reading the page on the kernel side.
694 */
695 if (mapping_writably_mapped(mapping))
696 flush_dcache_page(page);
697
698 /*
699 * Mark the page accessed if we read the beginning.
700 */
701 if (!offset)
702 mark_page_accessed(page);
...
714 ret = actor(desc, page, offset, nr);
715 offset += ret;
716 index += offset >> PAGE_CACHE_SHIFT;
717 offset &= ~PAGE_CACHE_MASK;
718
719 page_cache_release(page);
720 if (ret == nr && desc->count)
721 continue;
722 break;
723
-----------------------------------------------------------------------
Lines 690723
The inline comments are descriptive so there's no point repeating them. Notice that on lines 656658, if more pages are to be retrieved, we immediately return to the top of the loop where the index and offset manipulations in lines 714716 help choose the next page to retrieve. If no more pages are to be read, we break out of the for loop.
-----------------------------------------------------------------------
mm/filemap.c
724 page_not_up_to_date:
725 /* Get exclusive access to the page ... */
726 lock_page(page);
727
728 /* Did it get unhashed before we got the lock? */
729 if (!page->mapping) {
730 unlock_page(page);
731 page_cache_release(page);
732 continue;
734
735 /* Did somebody else fill it already? */
736 if (PageUptodate(page)) {
737 unlock_page(page);
738 goto page_ok;
739 }
740
-----------------------------------------------------------------------
Lines 724740
If the page is not up to date, we check it again and return to the page_ok label if it is, now, up to date. Otherwise, we try to get exclusive access; this causes us to sleep until we get it. Once we have exclusive access, we see if the page attempts to remove itself from the page cache; if it is, we hasten it along before returning to the top of the for loop. If it is still present and is now up to date, we unlock the page and jump to the page_ok label.
-----------------------------------------------------------------------
mm/filemap.c
741 readpage:
742 /* ... and start the actual read. The read will unlock the page. */
743 error = mapping->a_ops->readpage(filp, page);
744
745 if (!error) {
746 if (PageUptodate(page))
747 goto page_ok;
748 wait_on_page_locked(page);
749 if (PageUptodate(page))
750 goto page_ok;
751 error = -EIO;
752 }
753
754 /* UHHUH! A synchronous read error occurred. Report it */
755 desc->error = error;
756 page_cache_release(page);
757 break;
758
-----------------------------------------------------------------------
Lines 741743
If the page was not up to date, we can fall through the previous label with the page lock held. The actual read, mapping->a_ops->readpage(filp, page), unlocks the page. (We trace readpage() further in a bit, but let's first finish the current explanation.)
Lines 746750
If we read a page successfully, we check that it's up to date and jump to page_ok when it is.
Lines 751758
If a synchronous read error occurred, we log the error in desc, release the page from the page cache, and break out of the for loop.
-----------------------------------------------------------------------
mm/filemap.c
759 no_cached_page:
760 /*
761 * Ok, it wasn't cached, so we need to create a new
762 * page..
763 */
764 if (!cached_page) {
765 cached_page = page_cache_alloc_cold(mapping);
766 if (!cached_page) {
767 desc->error = -ENOMEM;
768 break;
769 }
770 }
771 error = add_to_page_cache_lru(cached_page, mapping,
772 index, GFP_KERNEL);
773 if (error) {
774 if (error == -EEXIST)
775 goto find_page;
776 desc->error = error;
777 break;
778 }
779 page = cached_page;
780 cached_page = NULL;
781 goto readpage;
782 }
-----------------------------------------------------------------------
Lines 698772
If the page to be read wasn't cached, we allocate a new page in the address space and add it to both the least recently used (LRU) cache and the page cache.
Lines 773775
If we have an error adding the page to the cache because it already exists, we jump to the find_page label and try again. This could occur if multiple processes attempt to read the same uncached page; one would attempt allocation and succeed, the other would attempt allocation and find it already existing.
Lines 776777
If there is an error in adding the page to the cache other than it already existing, we log the error and break out of the for loop.
Lines 779781
When we successfully allocate and add the page to the page cache and LRU cache, we set our page pointer to the new page and attempt to read it by jumping to the readpage label.
-----------------------------------------------------------------------
mm/filemap.c
784 *_ra = ra;
785
786 *ppos = ((loff_t) index << PAGE_CACHE_SHIFT) + offset;
787 if (cached_page)
788 page_cache_release(cached_page);
789 file_accessed(filp);
790 }
-----------------------------------------------------------------------
Line 786
We calculate the actual offset based on our page cache index and offset.
Lines 787788
If we allocated a new page and could add it correctly to the page cache, we remove it.
Line 789
We update the file's last accessed time via the inode.
The logic described in this function is the core of the page cache. Notice how the page cache does not touch any specific filesystem data. This allows the Linux kernel to have a page cache that can cache pages regardless of the underlying filesystem structure. Thus, the page cache can hold pages from MINIX, ext2, and MSDOS all at the same time.
The way the page cache maintains its specific filesystem layer agnosticism is by using the readpage() function of the address space. Each specific filesystem implements its own readpage(). So, when the generic filesystem layer calls mapping->a_ops->readpage(), it calls the specific readpage() function from the filesystem driver's address_space_operations structure. For the ext2 filesystem, readpage() is defined as follows:
-----------------------------------------------------------------------
fs/ext2/inode.c
676 struct address_space_operations ext2_aops = {
677 .readpage = ext2_readpage,
678 .readpages = ext2_readpages,
679 .writepage = ext2_writepage,
680 .sync_page = block_sync_page,
681 .prepare_write = ext2_prepare_write,
682 .commit_write = generic_commit_write,
683 .bmap = ext2_bmap,
684 .direct_IO = ext2_direct_IO,
685 .writepages = ext2_writepages,
686 };
-----------------------------------------------------------------------
Thus, readpage()actually calls ext2_readpage():
-----------------------------------------------------------------------
fs/ext2/inode.c
616 static int ext2_readpage(struct file *file, struct page *page)
617 {
618 return mpage_readpage(page, ext2_get_block);
619 }
-----------------------------------------------------------------------
ext2_readpage() calls mpage_readpage(),which is a generic filesystem layer call, but passes it the specific filesystem layer function ext2_get_block().
The generic filesystem function mpage_readpage() expects a get_block() function as its second argument. Each filesystem implements certain I/O functions that are specific to the format of the filesystem; get_block() is one of these. Filesystem get_block() functions map logical blocks in the address_space pages to actual device blocks in the specific filesystem layout. Let's look at the specifics of mpage_readpage():
-----------------------------------------------------------------------
fs/mpage.c
358 int mpage_readpage(struct page *page, get_block_t get_block)
359 {
360 struct bio *bio = NULL;
361 sector_t last_block_in_bio = 0;
362
363 bio = do_mpage_readpage(bio, page, 1,
364 &last_block_in_bio, get_block);
365 if (bio)
366 mpage_bio_submit(READ, bio);
367 return 0;
368 }
-----------------------------------------------------------------------
Lines 360361
We allocate space for managing the bio structure the address space uses to manage the page we are trying to read from the device.
Lines 363364
do_mpage_readpage() is called, which translates the logical page to a bio structure composed of actual pages and blocks. The bio structure keeps track of information associated with block I/O.
Lines 365367
We send the newly created bio structure to mpage_bio_submit() and return.
Let's take a moment and recap (at a high level) the flow of the read function so far:
Using the file descriptor from a call to read(), we locate the file pointer from which we obtain an inode. The filesystem layer checks the in-memory page cache for a page, or pages, that correspond to the given inode. If no page is found, the filesystem layer uses the specific filesystem driver to translate the requested sections of the file to I/O blocks on a given device. We allocate space for pages in the page cache address_space and create a bio structure that ties the new pages with the sectors on the block device.
mpage_readpage() is the function that creates the bio structure and ties together the newly allocated pages from the page cache to the bio structure. However, no data exists in the pages yet. For that, the filesystem layer needs the block device driver to do the actual interfacing to the device. This is done by the submit_bio() function in mpage_bio_submit():
-----------------------------------------------------------------------
fs/mpage.c
90 struct bio *mpage_bio_submit(int rw, struct bio *bio)
91 {
92 bio->bi_end_io = mpage_end_io_read;
93 if (rw == WRITE)
94 bio->bi_end_io = mpage_end_io_write;
95 submit_bio(rw, bio);
96 return NULL;
97 }
-----------------------------------------------------------------------
Line 90
The first thing to notice is that mpage_bio_submit() works for both read and write calls via the rw parameter. It submits a bio structure that, in the read case, is empty and needs to be filled in. In the write case, the bio structure is filled and the block device driver copies the contents to its device.
Lines 9294
If we are reading or writing, we set the appropriate function that will be called when I/O ends.
Lines 9596
We call submit_bio() and return NULL. Recall that mpage_readpage() doesn't do anything with the return value of mpage_bio_submit().
submit_bio() is part of the generic block device driver layer of the Linux kernel.
-----------------------------------------------------------------------
drivers/block/ll_rw_blk.c
2433 void submit_bio(int rw, struct bio *bio)
2434 {
2435 int count = bio_sectors(bio);
2436
2437 BIO_BUG_ON(!bio->bi_size);
2438 BIO_BUG_ON(!bio->bi_io_vec);
2439 bio->bi_rw = rw;
2440 if (rw & WRITE)
2441 mod_page_state(pgpgout, count);
2442 else
2443 mod_page_state(pgpgin, count);
2444
2445 if (unlikely(block_dump)) {
2446 char b[BDEVNAME_SIZE];
2447 printk(KERN_DEBUG "%s(%d): %s block %Lu on %s\n",
2448 current->comm, current->pid,
2449 (rw & WRITE) ? "WRITE" : "READ",
2450 (unsigned long long)bio->bi_sector,
2451 bdevname(bio->bi_bdev,b));
2452 }
2453
2454 generic_make_request(bio);
2455 }
-----------------------------------------------------------------------
Lines 24332443
These calls enable some debugging: Set the read/write attribute of the bio structure, and perform some page state housekeeping.
Lines 24452452
These lines handle the rare case that a block dump occurs. A debug message is thrown.
Line 2454
generic_make_request() contains the main functionality and uses the specific block device driver's request queue to handle the block I/O operation.
Part of the inline comments for generic_make_request() are enlightening:
-----------------------------------------------------------------------
drivers/block/ll_rw_blk.c
2336 * The caller of generic_make_request must make sure that bi_io_vec
2337 * are set to describe the memory buffer, and that bi_dev and bi_sector are
2338 * set to describe the device address, and the
2339 * bi_end_io and optionally bi_private are set to describe how
2340 * completion notification should be signaled.
-----------------------------------------------------------------------
In these stages, we constructed the bio structure, and thus, the bio_vec structures are mapped to the memory buffer mentioned on line 2337, and the bio struct is initialized with the device address parameters as well. If you want to follow the read even further into the block device driver, refer to the "Block Device Overview"section in
Chapter 5, which describes how the block device driver handles request queues and the specific hardware constraints of its device. Figure 6.18 illustrates how the read() system call traverses through the layers of kernel functionality.
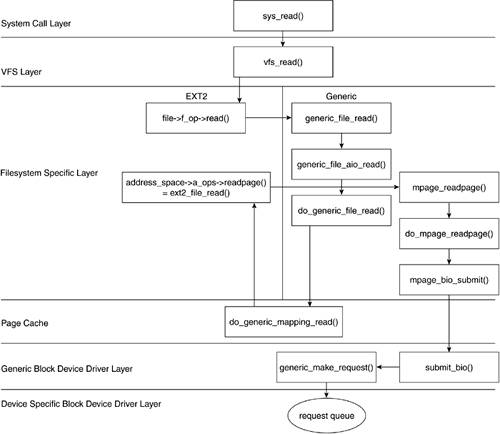
After the block device driver reads the actual data and places it in the bio structure, the code we have traced unwinds. The newly allocated pages in the page cache are filled, and their references are passed back to the VFS layer and copied to the section of user space specified so long ago by the original read() call.
However, we hear you ask, "Isn't this only half of the story? What if we wanted to write instead of read?"
We hope that these descriptions made it somewhat clear that the path a read() call takes through the Linux kernel is similar to the path a write() call takes. However, we now outline some differences.
6.5.4. write()
A write() call gets mapped to sys_write() and then to vfs_write() in the same manner as a read() call:
-----------------------------------------------------------------------
fs/read_write.c
244 ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
245 {
...
259 ret = file->f_op->write(file, buf, count, pos);
...
268 }
-----------------------------------------------------------------------
vfs_write() uses the generic file_operations write function to determine what specific filesystem layer write to use. This is translated, in our example ext2 case, via the ext2_file_operations structure:
-----------------------------------------------------------------------
fs/ext2/file.c
42 struct file_operations ext2_file_operations = {
43 .llseek = generic_file_llseek,
44 .read = generic_file_read,
45 .write = generic_file_write,
...
56 };
-----------------------------------------------------------------------
Lines 4445
Instead of calling generic_file_read(), we call generic_file_write().
generic_file_write() obtains a lock on the file to prevent two writers from simultaneously writing to the same file, and calls generic_file_write_nolock(). generic_file_write_nolock() converts the file pointers and buffers to the kiocb and iovec parameters and calls the page cache write function generic_file_aio_write_nolock().
Here is where a write diverges from a read. If the page to be written isn't in the page cache, the write does not fall through to the device itself. Instead, it reads the page into the page cache and then performs the write. Pages in the page cache are not immediately written to disk; instead, they are marked as "dirty" and, periodically, all dirty pages are written to disk.
There are analogous functions to the read() functions' readpage(). Within generic_file_aio_write_nolock(), the address_space_operations pointer accesses prepare_write() and commit_write(), which are both specific to the filesystem type the file resides upon. Recall ext2_aops, and we see that the ext2 driver uses its own function, ext2_prepare_write(), and a generic function generic_commit_write().
-----------------------------------------------------------------------
fs/ext2/inode.c
628 static int
629 ext2_prepare_write(struct file *file, struct page *page,
630 unsigned from, unsigned to)
631 {
632 return block_prepare_write(page,from,to,ext2_get_block);
633 }
-----------------------------------------------------------------------
Line 632
ext2_prepare_write is simply a wrapper for the generic filesystem function block_prepare_write(), which passes in the ext2 filesystem-specific get_block() function.
block_prepare_write() allocates any new buffers that are required for the write. For example, if data is being appended to a file enough buffers are created, and linked with pages, to store the new data.
generic_commit_write() takes the given page and iterates over the buffers within it, marking each dirty. The prepare and the commit sections of a write are separated to prevent a partial write being flushed from the page cache to the block device.
6.5.4.1. Flushing Dirty Pages
The write() call returns after it has insertedand marked dirtyall the pages it has written to. Linux has a daemon, pdflush, which writes the dirty pages from the page cache to the block device in two cases:
The system's free memory falls below a threshold.
Pages from the page cache are flushed to free up memory.
Dirty pages reach a certain age.
Pages that haven't been written to disk after a certain amount of time are written to their block device.
The pdflush daemon calls the filesystem-specific function writepages() when it is ready to write pages to disk. So, for our example, recall the ext2_file_operation structure, which equates writepages() with ext2_writepages().
-----------------------------------------------------------------------
670 static int
671 ext2_writepages(struct address_space *mapping, struct writeback_control *wbc)
672 {
673 return mpage_writepages(mapping, wbc, ext2_get_block);
674 }
-----------------------------------------------------------------------
Like other specific implementations of generic filesystem functions, ext2_ writepages() simply calls the generic filesystem function mpage_writepages() with the filesystem-specific ext2_get_block() function.
mpage_writepages() loops over the dirty pages and calls mpage_writepage() on each dirty page. Similar to mpage_readpage(), mpage_writepage() returns a bio structure that maps the physical device layout of the page to its physical memory layout. mpage_writepages() then calls submit_bio() to send the new bio structure to the block device driver to transfer the data to the device itself.
|
|
| siddu | Simmmmmmmply superb article.........kudos to u man!!!!!!!!!!!!!
2007-11-14 13:54:46 | | Devesh | By far very best and definite guide on Linux VFS and its structure.
Thanks to you for this article
2008-05-05 09:03:17 | |
|
|
|

 LINUX
LINUX 
 Kernels
Kernels
