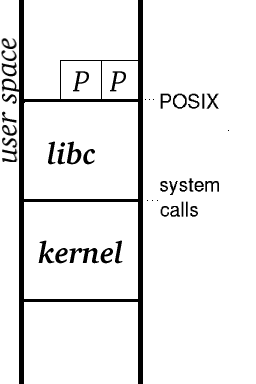
Let us look at the two interfaces: that between kernel and user space,
and that between application code and system code. We have three layers,
with libc between the kernel and the application code.
#include <stdio.h>
int main() {
printf("Hello world!\n");
return 0;
}
programs for the libc interface. This C program calls the
routine printf() that is part of the C library. A large part
of the API (Application Program(ming) Interface) of the C library
in a Unix environment is described by POSIX. The latest version of
this standard is
POSIX 1003.1-2001.
From the viewpoint of the application programmer
(and from the viewpoint of the POSIX standard)
there is no distinction between library routines and system calls.
Kernel and C library together provide the services described.
Many things are handled by the C library itself - those are
the things the user could have programmed himself, but need not
since the author of the library did this job already.
Maybe the presence of the library also saves some memory:
many utilities can share common library code.
But for the basic things, starting programs, allocating memory,
file I/O etc., the C library invokes the kernel.
The kernel provides certain services, and user space,
that is, everything outside the kernel, both libraries and
application programs, uses these.
Programs in user space contain system calls that ask the
kernel to do something, and the kernel does so, or returns
an error code.
Application programs do not usually contain direct system calls.
Instead, they use library calls and the library uses system calls.
But an application program can construct a system call "by hand".
For example, in order to use the system call _llseek
(to seek in a file larger than 4 GB when lseek does not
support that), one can write
#include <linux/unistd.h>
_syscall5(int, _llseek, unsigned int, fd,
unsigned long, offset_high, unsigned long, offset_low,
long long *, result, unsigned int, origin)
long long
my_llseek(unsigned int fd, unsigned long long offset, unsigned int origin) {
long long result;
int retval;
retval = _llseek (fd, offset >> 32, offset & 0xffffffff,
&result, origin);
return (retval == -1) ? -1 : result;
}
This _syscall5 is a macro that expands to the definition
of _llseek as system call, with a tiny wrapper to set
errno if necessary and the routine my_llseek
invokes this system call. Read the details in
/usr/include/asm/unistd.h.
An alternative is to use the syscall() call. It allows one
to invoke system calls by number. See syscall(2). For example,
syscall(__NR_getuid) is equivalent to getuid():
Typically, the kernel returns a negative value to indicate an error:
return -EPERM; /* Operation not permitted */
Typically, libc returns -1 to indicate an error, and sets the global
variable errno to a value indicating what was wrong.
Thus, one expects glueing code somewhat like
int chdir(char *dir) {
int res = sys_chdir(dir);
if (res < 0 && res > -4096) {
errno = -res;
return -1;
}
return res;
}
Such glueing code is automatically provided if one uses
the kernel macros _syscallN, with N
in 0..6 (for system calls with N parameters),
defined in /usr/include/asm/unistd.h.
These macros all end with a call of the macro __syscall_return
defined for 2.6.14 as
#define __syscall_return(type, res) \
do { \
if ((unsigned long)(res) >= (unsigned long)(-(128 + 1))) { \
errno = -(res); \
res = -1; \
} \
return (type) (res); \
} while (0)
that is supposed to convert the error codes to -1.
(The code is buggy: the -(128+1) and the accompanying comment
suggest that this is a test for 1..128, but it is a test for 1..129,
and in fact error numbers fill the range 1..131 for this kernel.)
Most system calls return positive values, but some can return arbitrary
values, and it is impossible to see whether an error occurred.
% /lib/libc.so.6
GNU C Library stable release version 2.2.5, by Roland McGrath et al.
...
But several other C libraries exist.
In ancient times we had libc4, a library still used by the
Mastodon
distribution. It uses the a.out format for binaries instead of the newer
ELF format.
In old times we had libc5. It is not much used anymore,
but people sometimes like it because it is much smaller than glibc.
The last one is still in an early stage of development.
It is intended for early user space (see also below), when the Linux kernel
has been booted but no filesystem has been found on disk yet.
Thus, it should be tiny, and needs only a few functions.
All of the libraries uClibc, dietlibc and newlib are meant for embedded use.
Especially uClibc is fairly complete. They are much smaller than glibc.
There are also projects to recreate all standard utilities
in a minimal form. See, for example
busybox.
ExerciseInstall and use uClibc. What is the difference
in size compared to glibc of statically compiled binaries?
Of dynamically compiled binaries? Is there a speed difference?
In 2.5.46 the first version of early userspace was merged into
the official kernel tree. One sees the effects mainly in the
dmesg output
-> /dev
-> /dev/console
-> /root
The subdirectory /usr of the kernel source tree
is for early userspace stuff. In init/main.c
there is the call populate_rootfs() that unpacks
the cpio archive initramfs_data.cpio.gz into the kernel rootfs.
There are only these three device nodes, no actual programs yet,
since programs need a library, and klibc has not been merged yet.
If one wants to play with this, find kernel 2.5.64 and apply the above
klibc patch. It contains a usr/root/hello.c program,
that however is never invoked. Add an invocation in init/main.c
before the prepare_namespace(), e.g.,
in gen_init_cpio.c, the program used to generate
initramfs_data.cpio.gz. (Of course one can also generate
this cpio archive using cpio, and give it arbitrary contents.
If the contents is large, a patch is needed that is first present
in 2.5.65.)
If after booting you see Hi Ma! then hello.c
executed successfully, but the boot will stop there, since
this process is "init" and must never exit.
(So, the "hello" program should do its work and then exec the real init.)
Note that the / here is in the initramfs filesystem.
But after prepare_namespace() one has / in
the root filesystem.
The binary files one meets in daily life are object files,
executables and libraries.
Given the standard example hello.c, that contains
something like
main() { printf("Hello!\n"); }
one creates the object file hello.o by cc -c hello.c,
or the executable hello by cc -o hello hello.c.
Now this executable does not contain code for the printf()
function. The command
shows that this executable requires ld-linux.so.2 and
libc.so.6 at run time. The former is a linker that will
at startup time insert the address of the printf() routine
(found in libc.so.6) into a table with function pointers.
(For linux-gate.so.1, see the section on
vsyscalls.)
See also ld.so(8).
It is possible to produce complete executables, that do not require
run-time linking by giving cc the -static flag:
cc -static -o hello-static hello.c.
The strip utility removes the symbol table.
Static executables are huge and usually needed only
in emergency situations. For example, it is common to have
a statically linked version sln of the ln
utility, to set up links like /lib/libc.so.6 -> libc-2.3.2.so
making the library name point at the actual library.
(Changing such links should be done with ln -sf ..,
so that there never is a moment that the libc link points
to nowhere. If one tries to go in two steps: remove old link,
create new link, then the second step will fail with an ln
that needs libc, and suddenly no command works anymore.)
It is also common to have a statically linked /sbin/init.
Binary formats
Various binary formats exist, like a.out, COFF, and ELF.
ELF is the modern format. Support for a.out is disappearing.
The linux libc4 (like libc.so.4.6.27) libraries use
the a.out format. In 1995 the big changeover to ELF happened.
The new libraries are called libc5 (like libc.so.5.0.9).
Around 1997/1998 libc5, maintained by HJLu, was replaced by
libc6, also known as glibc2, maintained by Ulrich Drepper.
The a.out format comes in several flavours, such as
OMAGIC, NMAGIC, ZMAGIC, QMAGIC.
The OMAGIC format is very compact, but program in this format cannot
be swapped or demand paged because it has a non-page-aligned header.
The ZMAGIC format has its .text section aligned to a 1024-byte boundary,
allowing bmap(), provided the binary lives on a filesystem
with 1024-byte blocks.
It was superseded by the QMAGIC format, that has its .text section
starting at offset 0 (so that it contains the header)
but with the first page not mapped.
The result is that QMAGIC binaries are 992 bytes smaller than ZMAGIC ones,
and moreover allow one to trap dereference of NULL pointers.
The binary format of an executable must be understood by
the kernel when it handles an exec() call.
There are kernel configuration options CONFIG_BINFMT_AOUT,
CONFIG_BINFMT_MISC, CONFIG_BINFMT_ELF etc.
Support for certain types of binaries can also be compiled as a module.
The kernel has (in exec.c) a linked list formats
and routines (un)register_binfmt() called by modules
who want to announce that they support some binary format.
The routine search_binary_handler() tries all of the
registered modules, calling their load_binary() functions
one by one until one returns success. If all fail, the first few bytes
of the binary are used as a magic (decimal) number to request a
module that was not loaded yet. For example, a ZMAGIC binary
starts with the bytes 0b 01, giving octal 0413, decimal 267
and would cause the module binfmt-267 to be requested.
(Details depend on kernel version.)
Example of an OMAGIC file
Let us create a small OMAGIC binary by hand.
We need a 32-byte header with structure as given in
<asm/a.out.h>.
% cat exb.s
; aout header
.LONG 0407 ; OMAGIC
.LONG 12 ; length of text
.LONG 0 ; length of data
.LONG 0 ; length of bss
.LONG 0 ; length of symbol table
.LONG 0 ; start address
.LONG 0 ; length of relocation info for text
.LONG 0 ; length of relocation info for data
; actual program
main:
mov eax,#1 ; exit(42)
mov ebx,#42
int #0x80
% as86 -3 -b exb exb.s
% od -Ad -tx1 exb
0000 07 01 00 00 0c 00 00 00 00 00 00 00 00 00 00 00
0016 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0032 b8 01 00 00 00 bb 2a 00 00 00 cd 80
0044
% objdump -d exb
exb: file format a.out-i386-linux
Disassembly of section .text:
0000000000000000 <.text>:
0: b8 01 00 00 00 mov $0x1,%eax
5: bb 2a 00 00 00 mov $0x2a,%ebx
a: cd 80 int $0x80
% chmod +x exb
% ./exb
% echo $?
42
%
Thus we have a 44-byte binary that consists of a 32-byte header
followed by a 12-byte program. (The statically linked translation
of the equivalent C program main() { return 42; }
takes 388076 bytes.)
That worked. Now avoid creating the header by hand.
(Without the export line, ld86 will complain
ld86: no start symbol.)
That was (almost) the same 44-byte binary - one header byte differs.
Producing OMAGIC from C source seems to be done using bcc -3 -N,
but I do not have bcc here.
Shared and static libraries
Linking against a static library (with a name like foo.a)
involves copying the code for the functions needed from that library
at compile time.
Linking against a dynamic library (with a name like foo.sa
for a.out, or foo.so for ELF) involves finding references
to the functions needed at compile time, so that these can be found
in the right libraries at run time.
(The files foo.sa are not the actual libraries, but contain
values of global symbols and function addresses needed for run time
linking. The actual library is probably called foo.so.1.2.3.)
The utility ldd tells you what libraries a program needs.
Personality
Linux has the concept of personality of an executable (since 1.1.20).
The purpose is to make the Linux environment more similar to some other
environment, like BSD or SCO or Solaris or older Linux, so that foreign
or old binaries have better chances of working without modification.
For example, the Linux select() system call will update
its timeout parameter to reflect the amount of time left.
With the STICKY_TIMEOUTS flag set in the personality this is not done,
following BSD behaviour.
For example, dereferencing a NULL pointer is sign of a program bug
and causes a segfault because 0 is not in mapped memory. But SVr4
maps page 0 read-only (filled with zeroes) and some programs depend on this.
With the MMAP_PAGE_ZERO flag set in the personality Linux will also do this.
Or, for example, the Linux mmap() system call will nowadays
randomize the assigned addresses as a defense against hacking attempts,
but with the ADDR_NO_RANDOMIZE flag set in the personality this is not done
(since 2.6.12).
The personality value is composed of a 2-byte value identifying the system
(Linux, SVR4, SUNOS, HPUX etc), and a number of 1-bit flags.
See <linux/personality.h>.
The personality is inherited from the parent process, and
changed using the personality() system call.
The setarch utility is a convenient tool for starting
a process with a given personality.
System calls are identified by their numbers. The number of
the call foo is __NR_foo. For example,
the number of _llseek used above is __NR__llseek,
defined as 140 in /usr/include/asm-i386/unistd.h.
Different architectures have different numbers.
Often, the kernel routine that handles the call foo
is called sys_foo. One finds the association between
numbers and names in the sys_call_table, for example in
arch/i386/kernel/entry.S.
Change
The world changes and system calls change.
Since one must not break old binaries, the semantics associated to
any given system call number must remain fully backwards compatible.
What happens in practice is one of two things: either one gets a
new and improved system call with a new name and number, and the
libc routine that used to invoke the old call is changed to use
the new one, or the new call (with new number) gets the old name,
and the old call gets "old" prefixed to its name.
For example, long ago user IDs had 16 bits, today they have 32.
__NR_getuid is 24, and __NR_getuid32
is 199, and the former belongs to the 16-bit version of the call,
the latter to the 32-bit version.
Looking at the associated kernel routines, we find that these are
sys_getuid16 and sys_getuid, respectively.
(Thus, sys_getuid does not have number __NR_getuid.)
Looking at glibc, we find code somewhat like
int getuid32_available = UNKNOWN;
uid_t getuid(void) {
if (getuid32_available == TRUE)
return INLINE_SYSCALL(getuid32, 0);
if (getuid32_available == UNKNOWN) {
uid_t res = INLINE_SYSCALL(getuid32, 0);
if (res == 0 || errno != ENOSYS) {
getuid32_available = TRUE;
return res;
}
getuid32_available = FALSE;
}
return INLINE_SYSCALL(getuid, 0);
}
For an example where the name was moved and the old call got
a name prefixed by "old", see __NR_oldolduname,
__NR_olduname, __NR_uname, belonging to
sys_olduname, sys_uname, sys_newuname,
respectively.
One also has __NR_oldstat, __NR_stat,
__NR_stat64 belonging to sys_stat,
sys_newstat, sys_stat64, respectively.
And __NR_umount, __NR_umount2
belonging to sys_oldumount, sys_umount, respectively.
These moving names are confusing - now you have been warned:
the system call with number __NR_foo does not always
belong to the kernel routine sys_foo().
Thus, the basic ingredient is the assembler instruction INT 0x80.
This causes a programmed exception and calls the kernel
system_call routine. Some relevant code fragments:
We transfer execution to system_call, save the original
value of the EAX register (it is the number of the system call),
save all other registers, verify that we are not being traced
(otherwise the tracer must be informed and entirely different
things happen), make sure that the system call number is within
range, and call the appropriate kernel routine from the table
sys_call_table. Upon return we check a few things and
when all is well restore the registers and call IRET to return
from this INT.
(This was for the i386 architecture. All details differ on other
architectures, but the basic idea is the same: store the syscall
number and the syscall parameters somewhere the kernel can find them,
in registers, on the stack, or in a known place of memory,
do something that causes a transfer to kernel code, etc.)
On i386, the parameters of a system call are transported via
registers. The system call number goes into %eax,
the first parameter in %ebx, the second in %ecx,
the third in %edx, the fourth in %esi, the fifth
in %edi, the sixth in %ebp.
Ancient history
Earlier versions of Linux could handle only four or five system call
parameters, and therefore the system calls select() (5 parameters)
and mmap() (6 parameters) used to have a single parameter
that was a pointer to a parameter block in memory. Since Linux 1.3.0
five parameters are supported (and the earlier select with
memory block was renamed old_select), and since Linux 2.3.31
six parameters are supported (and the earlier mmap with
memory block was succeeded by the new mmap2).
Above we said: typically, the kernel returns a negative value to
indicate an error. But this would mean that any system call only
can return positive values. Since the negative error returns are
of the form -ESOMETHING, and the error numbers have small
positive values, there is only a small negative error range.
Thus
#define __syscall_return(type, res) \
do { \
if ((unsigned long)(res) >= (unsigned long)(-125)) { \
errno = -(res); \
res = -1; \
} \
return (type) (res); \
} while (0)
Here the range [-125,-1] is reserved for errors (the constant 125
is version and architecture dependent) and other values are OK.
What if a system call wants to return a small negative number
and it is not an error? The scheduling priority of a process
is set by setpriority() and read by getpriority(),
and this value ranges from -20 (top priority) to 19 (lowest priority
background job). The library routines with these names use these
numbers, but the system call getpriority() returns
20 - P instead of P, moving the output interval to positive numbers only.
Or, similarly, the subfunctions PEEK* of ptrace return
the contents of a memory word in the traced process, and any
value is possible. However, the system call returns this value in
the data argument, and glibc does something like
res = sys_ptrace(request, pid, addr, &data);
if (res >= 0) {
errno = 0;
res = data;
}
return res;
so that a user program has to do
errno = 0;
res = ptrace(PTRACE_PEEKDATA, pid, addr, NULL);
if (res == -1 && errno != 0)
/* error */
Above we saw in ret_from_sys_call the test on sigpending:
if a signal arrived while we were executing kernel code, then just
before returning from the system call we first call the user program's
signal handler, and when this finishes return from the system call.
When a system call is slow and a signal arrives while it was blocked,
waiting for something, the call is aborted and returns -EINTR,
so that the library function will return -1 and set errno
to EINTR. Just before the system call returns, the user program's
signal handler is called.
(So, what is "slow"? Mostly those calls that can block forever waiting
for external events; read and write to terminal devices, but not
read and write to disk devices, wait, pause.)
This means that a system call can return an error while nothing was
wrong. Usually one will want to redo the system call. That can be
automated by installing the signal handler using a call to
sigaction with the SA_RESTART flag set.
The effect is that upon an interrupt the system call is aborted,
the user program's signal handler is called, and afterwards
the system call is restarted from the beginning.
Why is this not the default? It was, for a while, but often it is
necessary to react to a signal while the reacting is not done by
the signal handler itself. It is difficult to do nontrivial things
in a signal handler since the rest of the program is in an unknown
state, and most signal handlers just set a flag that is tested
elsewhere.
A demo:
#include <stdio.h>
#include <errno.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
int got_interrupt;
void intrup(int dummy) {
got_interrupt = 1;
}
void die(char *s) {
printf("%s\n", s);
exit(1);
}
int main() {
struct sigaction sa;
int n;
char c;
sa.sa_handler = intrup;
sigemptyset(&sa.sa_mask);
sa.sa_flags = 0;
if (sigaction(SIGINT, &sa, NULL))
die("sigaction-SIGINT");
sa.sa_flags = SA_RESTART;
if (sigaction(SIGQUIT, &sa, NULL))
die("sigaction-SIGQUIT");
got_interrupt = 0;
n = read(0, &c, 1);
if (n == -1 && errno == EINTR)
printf("read call was interrupted\n");
else if (got_interrupt)
printf("read call was restarted\n");
return 0;
}
Here Ctrl-C will interrupt the read call, while after Ctrl-\
the read call is restarted.
It has been
observed
that a 2 GHz Pentium 4 was much slower than an 850 MHz Pentium III on
certain tasks, and that this slowness is caused by the very large overhead
of the traditional int 0x80 interrupt on a Pentium 4.
Some models of the i386 family do have faster ways to enter the kernel.
On Pentium II there is the sysenter instruction.
Also AMD has a syscall instruction.
It would be good if these could be used.
Something else is that in some applications gettimeofday()
is a done very often, for example for timestamping all transactions.
It would be nice if it could be implemented with very low overhead.
One way of obtaining a fast gettimeofday()
is by writing the current time in a fixed place, on a page mapped
into the memory of all applications, and updating this location on
each clock interrupt. These applications could then read this fixed
location with a single instruction - no system call required.
There might be other data that the kernel could make available
in a read-only way to the process, like perhaps the current process ID.
A vsyscall is a "system" call that avoids crossing
the userspace-kernel boundary.
Linux is in the process of implementing such ideas.
Since Linux 2.5.53 there is a fixed page, called the vsyscall page,
filled by the kernel. At kernel initialization time the routine
sysenter_setup() is called. It sets up a non-writable page
and writes code for the sysenter instruction if the CPU
supports that, and for the classical int 0x80 otherwise.
Thus, the C library can use the fastest type of system call
by jumping to a fixed address in the vsyscall page.
Concerning gettimeofday(), a vsyscall version for the x86-64
is already part of the vanilla kernel. Patches for i386 exist.
(An example of the kind of timing differences: John Stultz reports
on an experiment where he measures gettimeofday() and
finds 1.67 us for the int 0x80 way, 1.24 us for the
sysenter way, and 0.88 us for the vsyscall.)
Some details
The kernel maps a page (0xffffe000-0xffffefff) in the memory of
every process. (This is the one but last addressable page. The last
is not mapped - maybe to avoid bugs related to wraparound.)
We can read it:
% ./get_vsyscall_page > syspage
% file syspage
syspage: ELF 32-bit LSB shared object, Intel 80386, version 1 (SYSV), stripped
% objdump -h syspage
syspage: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .hash 00000050 ffffe094 ffffe094 00000094 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
1 .dynsym 000000f0 ffffe0e4 ffffe0e4 000000e4 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .dynstr 00000056 ffffe1d4 ffffe1d4 000001d4 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
3 .gnu.version 0000001e ffffe22a ffffe22a 0000022a 2**1
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .gnu.version_d 00000038 ffffe248 ffffe248 00000248 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
5 .text 00000047 ffffe400 ffffe400 00000400 2**5
CONTENTS, ALLOC, LOAD, READONLY, CODE
6 .eh_frame_hdr 00000024 ffffe448 ffffe448 00000448 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
7 .eh_frame 0000010c ffffe46c ffffe46c 0000046c 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
8 .dynamic 00000078 ffffe578 ffffe578 00000578 2**2
CONTENTS, ALLOC, LOAD, DATA
9 .useless 0000000c ffffe5f0 ffffe5f0 000005f0 2**2
CONTENTS, ALLOC, LOAD, DATA
% objdump -d syspage
syspage: file format elf32-i386
Disassembly of section .text:
ffffe400 <.text>:
ffffe400: 51 push %ecx
ffffe401: 52 push %edx
ffffe402: 55 push %ebp
ffffe403: 89 e5 mov %esp,%ebp
ffffe405: 0f 34 sysenter
ffffe407: 90 nop
ffffe408: 90 nop
... more nops ...
ffffe40d: 90 nop
ffffe40e: eb f3 jmp 0xffffe403
ffffe410: 5d pop %ebp
ffffe411: 5a pop %edx
ffffe412: 59 pop %ecx
ffffe413: c3 ret
... zero bytes ...
ffffe420: 58 pop %eax
ffffe421: b8 77 00 00 00 mov $0x77,%eax
ffffe426: cd 80 int $0x80
ffffe428: 90 nop
ffffe429: 90 nop
... more nops ...
ffffe43f: 90 nop
ffffe440: b8 ad 00 00 00 mov $0xad,%eax
ffffe445: cd 80 int $0x80
The interesting addresses here are found via
% grep ffffe System.map
ffffe000 A VSYSCALL_BASE
ffffe400 A __kernel_vsyscall
ffffe410 A SYSENTER_RETURN
ffffe420 A __kernel_sigreturn
ffffe440 A __kernel_rt_sigreturn
%
So __kernel_vsyscall pushes a few registers and does
a sysenter instruction. And SYSENTER_RETURN
pops the registers again and returns. And __kernel_sigreturn
and __kernel_rt_sigreturn do system calls 119 and 173,
that is, sigreturn and rt_sigreturn, respectively.
What about the jump just before SYSENTER_RETURN?
It is a trick to handle restarting of system calls with 6 parameters.
As Linus said:
I'm a disgusting pig, and proud of it to boot.
#include <stdio.h>
int pid;
int main() {
__asm__(
"movl $20, %eax \n"
"call 0xffffe400 \n"
"movl %eax, pid \n"
);
printf("pid is %d\n", pid);
return 0;
}
This does the getpid() system call (__NR_getpid is 20)
using call 0xffffe400 instead of int 0x80.
However, the proper thing to do is not call 0xffffe400
but call *%gs:0x18. If %gs has been set up so
that it addresses 0xffffe000, then at location 0xffffe018
we find the value of __kernel_vsyscall, the entry point of the
kernel vsyscalls. Such general setup requires the parsing of the
ELF headers of this vsyscall page, but then is future-proof.
The common communication channel between user space program and
kernel is given by the system calls. But there is a different channel,
that of the signals, used both between user processes
and from kernel to user process.
A program can signal a different program using the kill()
system call with prototype
int kill(pid_t pid, int sig);
This will send the signal with number sig to the process
with process ID pid. Signal numbers are small positive integers.
(For the definitions on your machine, try /usr/include/bits/signum.h.
Note that these definitions depend on OS and architecture.)
A user can send a signal from the command line using the kill
command. Common uses are kill -9N to kill the process
with pid N, or kill -1N
to force process N (maybe init or inetd)
to reread its configuration file.
Certain user actions will make the kernel send a signal to a process
or group of processes: typing the interrupt character (probably Ctrl-C)
causes SIGINT to be sent, typing the quit character (probably
Ctrl-\) sends SIGQUIT, hanging up the phone (modem) sends SIGHUP,
typing the stop character (probably Ctrl-Z) sends SIGSTOP.
Certain program actions will make the kernel send a signal to that process:
for an illegal instruction one gets SIGILL, for accessing nonexisting
memory one gets SIGSEGV, for writing to a pipe while nobody is listening
anymore on the other side one gets SIGPIPE, for reading from the termnal
while in the background one gets SIGTTIN, etc.
More interesting communication from the kernel is also possible.
One can ask the kernel to be notified when something happens
on a given file descriptor. See fcntl(2).
And then there is ptrace(2) - see below.
A whole group of signals is reserved for real-time use.
When a process receives a signal, a default action happens, unless
the process has arranged to handle the signal. For the list of
signals and the corresponding default actions, see signal(7).
For example, by default SIGHUP, SIGINT, SIGKILL will kill the process;
SIGQUIT will kill the process and force a core dump;
SIGSTOP, SIGTTIN will stop the process;
SIGCONT will continue a stopped process;
SIGCHLD will be ignored.
Traditionally, one sets up a handler for the signal using
the signal system call with prototype
This sets up the routine handler() as handler for signals
with number sig. The return value is (the address of)
the old handler. The special values SIG_DFL and SIG_IGN denote the
default action and ignoring, respectively.
When a signal arrives, the process is interrupted, the current
registers are saved, and the signal handler is invoked.
When the signal handler returns, the interrupted activity is
continued.
It is difficult to do interesting things in a signal handler,
because the process can be interrupted in an arbitrary place,
data structures can be in arbitrary state, etc.
The three most common things to do in a signal handler are
(i) set a flag variable and return immediately, and (ii) (messy)
throw away all the program was doing, and restart at some
convenient point, perhaps the main command loop or so, and (iii)
clean up and exit.
Setting up a handler for a signal is called "catching the signal".
The signals SIGKILL and SIGSTOP cannot be caught or blocked or ignored.
The traditional semantics was: reset signal behaviour to SIG_DFL upon
invocation of the signal handler. Possibly this was done to avoid
recursive invocations. The signal handler would do its job and
at the end call signal() to establish itself again as handler.
This is really unfortunate. When two signals arrive shortly after
each other, the second one will be lost if it arrives before
the signal handler is called - there is no counter.
And if it arrives after the signal handler is called, the
default action will happen - this may very well kill the process.
Even if the handler calls signal() again as the very first
thing it does, that may be too late.
Various Unix flavours played a bit with the semantics to improve
on this situation. Some block signals as long as the process has not
returned from the handler. The BSD solution was to invent a new
system call, sigaction() where one can precisely specify
the desired behaviour. Today signal() must be regarded
as deprecated - not to be used in serious applications.
Each process has a list (bitmask) of currently blocked signals.
When a signal is blocked, it is not delivered (that is,
no signal handling routine is called), but remains pending.
The sigprocmask() system call serves to change
the list of blocked signals. See sigprocmask(2).
The sigpending() system call reveals what signals
are (blocked and) pending.
The sigsuspend() system call suspends the calling process
until a specified signal is received.
When a signal is blocked, it remains pending, even when otherwise
the process would ignore it.
When a process forks off a child to perform some task, it is probably
interested in how things went. Upon exit, the child leaves an exit status
that should be returned to the parent.
So, when the child finishes it becomes
a zombie - a process that is dead already but does not disappear
yet because it has not yet reported its exit status.
Whenever something interesting happens to the child
(it exits, crashes, traps, stops, continues),
and in particular when it dies, the parent is sent a SIGCHLD signal.
The parent can use the system call wait() or waitpid()
or so, there are a few variations, to learn about the status of its
stopped or deceased children. In the case of a deceased child, as soon as
a status has been reported, the zombie vanishes.
If the parent is not interested it can say so explicitly (before the fork)
using
and as a result it will not hear about deceased children,
and children will not be transformed into zombies.
Note that the default action for SIGCHLD is to ignore this signal;
nevertheless signal(SIGCHLD, SIG_IGN) has effect, namely
that of preventing the transformation of children into zombies.
In this situation, if the parent does a wait(), this call
will return only when all children have exited, and then returns -1
with errno set to ECHILD.
It depends on the Unix flavor whether SIGCHLD is sent when
SA_NOCLDWAIT was set. After act.sa_flags = SA_NOCLDSTOP
no SIGCHLD is sent when children stop or stopped children continue.
If the parent exits before the child, then the child is reparented
to init, process 1, and this process will reap its status.
When the program was interrupted by a signal, its status (including
all integer and floating point registers) was saved, to be restored
just before execution continues at the point of interruption.
This means that the return from the signal handler is more complicated
than an arbitrary procedure return - the saved state must be restored.
To this end, the kernel arranges that the return from the signal handler
causes a jump to a short code sequence (sometimes called trampoline)
that executes a sigreturn() system call. This system call takes
care of everything.
In the old days the trampoline lived on the stack, but nowadays (since 2.5.69)
we have a trampoline in the
vsyscall page,
so that this trampoline no longer is an obstacle in case one wants a
non-executable stack.
For debugging purposes, the ptrace() system call was
introduced. A process can trace a different process, examine or
change its memory, see the system calls done or change them, etc.
The way this is implemented is that the tracing process is notified
each time the traced process does something interesting. Always
interesting is the reception of signals. When the tracing process
specifies this, also excution of system calls, or execution of any
instruction is interesting.
Thus, one has interactive debuggers like gdb, and tracers
like strace. This call is also very useful for hacking
purposes. One can make one's own program attach to some utility
and subtly change its workings, while the binary of the utility
is unchanged, still has the correct date stamps and md5sum.
ExerciseWrite a program that attaches itself to a
process with specified pid, and watches its read() calls;
whenever a specified string occurs, change it into something else.
Be otherwise invisible.
ExerciseWrite a program that attaches itself to a shell
and watches the commands given. Whenever a specified binary must
be executed, execute a different specified binary instead.
Be otherwise invisible.
Below a
baby example of the use
of ptrace. This program will list the system calls done by some
existing process (call ./ptrace -pN) or some
subprocess (call ./ptrace some_command, e.g.,
./ptrace /bin/ls -l).
The version below will work only on i386, and only for relatively
recent kernels.
/*
* ptrace a child - baby demo example - i386 only
*
* call: "ptrace command args" to trace command
* "ptrace -p N" to trace process with pid N
*/
#include <errno.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <sys/ptrace.h>
#include <linux/user.h> /* ORIG_EAX */
#include <linux/unistd.h> /* __NR_exit */
#include <linux/ptrace.h> /* EAX */
#define SIZE(a) (sizeof(a)/sizeof((a)[0]))
/*
* syscall names for i386 under 2.5.51, taken from <asm/unistd.h>
*/
char *(syscall_names[256]) = {
"exit", "fork", "read", "write", "open", "close", "waitpid", "creat",
"link", "unlink", "execve", "chdir", "time", "mknod", "chmod",
"lchown", "break", "oldstat", "lseek", "getpid", "mount", "umount",
"setuid", "getuid", "stime", "ptrace", "alarm", "oldfstat", "pause",
"utime", "stty", "gtty", "access", "nice", "ftime", "sync", "kill",
"rename", "mkdir", "rmdir", "dup", "pipe", "times", "prof", "brk",
"setgid", "getgid", "signal", "geteuid", "getegid", "acct", "umount2",
"lock", "ioctl", "fcntl", "mpx", "setpgid", "ulimit", "oldolduname",
"umask", "chroot", "ustat", "dup2", "getppid", "getpgrp", "setsid",
"sigaction", "sgetmask", "ssetmask", "setreuid", "setregid",
"sigsuspend", "sigpending", "sethostname", "setrlimit", "getrlimit",
"getrusage", "gettimeofday", "settimeofday", "getgroups", "setgroups",
"select", "symlink", "oldlstat", "readlink", "uselib", "swapon",
"reboot", "readdir", "mmap", "munmap", "truncate", "ftruncate",
"fchmod", "fchown", "getpriority", "setpriority", "profil", "statfs",
"fstatfs", "ioperm", "socketcall", "syslog", "setitimer", "getitimer",
"stat", "lstat", "fstat", "olduname", "iopl", "vhangup", "idle",
"vm86old", "wait4", "swapoff", "sysinfo", "ipc", "fsync", "sigreturn",
"clone", "setdomainname", "uname", "modify_ldt", "adjtimex",
"mprotect", "sigprocmask", "create_module", "init_module",
"delete_module", "get_kernel_syms", "quotactl", "getpgid", "fchdir",
"bdflush", "sysfs", "personality", "afs_syscall", "setfsuid",
"setfsgid", "_llseek", "getdents", "_newselect", "flock", "msync",
"readv", "writev", "getsid", "fdatasync", "_sysctl", "mlock",
"munlock", "mlockall", "munlockall", "sched_setparam",
"sched_getparam", "sched_setscheduler", "sched_getscheduler",
"sched_yield", "sched_get_priority_max", "sched_get_priority_min",
"sched_rr_get_interval", "nanosleep", "mremap", "setresuid",
"getresuid", "vm86", "query_module", "poll", "nfsservctl",
"setresgid", "getresgid", "prctl","rt_sigreturn","rt_sigaction",
"rt_sigprocmask", "rt_sigpending", "rt_sigtimedwait",
"rt_sigqueueinfo", "rt_sigsuspend", "pread", "pwrite", "chown",
"getcwd", "capget", "capset", "sigaltstack", "sendfile", "getpmsg",
"putpmsg", "vfork", "ugetrlimit", "mmap2", "truncate64",
"ftruncate64", "stat64", "lstat64", "fstat64", "lchown32", "getuid32",
"getgid32", "geteuid32", "getegid32", "setreuid32", "setregid32",
"getgroups32", "setgroups32", "fchown32", "setresuid32",
"getresuid32", "setresgid32", "getresgid32", "chown32", "setuid32",
"setgid32", "setfsuid32", "setfsgid32", "pivot_root", "mincore",
"madvise", "getdents64", "fcntl64", 0, "security", "gettid",
"readahead", "setxattr", "lsetxattr", "fsetxattr", "getxattr",
"lgetxattr", "fgetxattr", "listxattr", "llistxattr", "flistxattr",
"removexattr", "lremovexattr", "fremovexattr", "tkill", "sendfile64",
"futex", "sched_setaffinity", "sched_getaffinity",
};
void my_ptrace_void(int request, pid_t pid, void *addr, void *data) {
int i = ptrace(request, pid, addr, data);
if (i) {
perror("ptrace");
exit(1);
}
}
/*
* Since -1 may be valid data, we have to check errno.
*/
int my_ptrace_read(int request, pid_t pid, void *addr, void *data) {
int i;
errno = 0;
i = ptrace(request, pid, addr, data);
if (i == -1 && errno) {
perror("ptrace");
exit(1);
}
return i;
}
pid_t pid; /* the traced program */
/* detach from traced program when interrupted */
void interrupt(int dummy) {
ptrace(PTRACE_DETACH, pid, 0, 0);
exit(-1);
}
int got_sig = 0;
void sigusr1(int dummy) {
got_sig = 1;
}
void my_kill(pid_t pid, int sig) {
int i = kill(pid, sig);
if (i) {
perror("kill");
exit(1);
}
}
/*
* A child stopped at a syscall has status as if it received SIGTRAP.
* In order to distinguish between SIGTRAP and syscall, some kernel
* versions have the PTRACE_O_TRACESYSGOOD option, that sets an extra
* bit 0x80 in the syscall case.
*/
#define SIGSYSTRAP (SIGTRAP | sysgood_bit)
int sysgood_bit = 0;
void set_sysgood(pid_t p) {
#ifdef PTRACE_O_TRACESYSGOOD
int i = ptrace(PTRACE_SETOPTIONS, p, 0, (void*) PTRACE_O_TRACESYSGOOD);
if (i == 0)
sysgood_bit = 0x80;
else
perror("PTRACE_O_TRACESYSGOOD");
#endif
}
#define EXPECT_EXITED 1
#define EXPECT_SIGNALED 2
#define EXPECT_STOPPED 4
void my_wait(pid_t p, int report, int stopsig) {
int status;
pid_t pw = wait(&status);
if (pw == (pid_t) -1) {
perror("wait");
exit(1);
}
/*
* Report only unexpected things.
*
* The conditions WIFEXITED, WIFSIGNALED, WIFSTOPPED
* are mutually exclusive:
* WIFEXITED: (status & 0x7f) == 0, WEXITSTATUS: top 8 bits
* and now WCOREDUMP: (status & 0x80) != 0
* WIFSTOPPED: (status & 0xff) == 0x7f, WSTOPSIG: top 8 bits
* WIFSIGNALED: all other cases, (status & 0x7f) is signal.
*/
if (WIFEXITED(status) && !(report & EXPECT_EXITED))
fprintf(stderr, "child exited%s with status %d\n",
WCOREDUMP(status) ? " and dumped core" : "",
WEXITSTATUS(status));
if (WIFSTOPPED(status) && !(report & EXPECT_STOPPED))
fprintf(stderr, "child stopped by signal %d\n",
WSTOPSIG(status));
if (WIFSIGNALED(status) && !(report & EXPECT_SIGNALED))
fprintf(stderr, "child signalled by signal %d\n",
WTERMSIG(status));
if (WIFSTOPPED(status) && WSTOPSIG(status) != stopsig) {
/* a different signal - send it on and wait */
fprintf(stderr, "Waited for signal %d, got %d\n",
stopsig, WSTOPSIG(status));
if ((WSTOPSIG(status) & 0x7f) == (stopsig & 0x7f))
return;
my_ptrace_void(PTRACE_SYSCALL, p, 0, (void*) WSTOPSIG(status));
return my_wait(p, report, stopsig);
}
if ((report & EXPECT_STOPPED) && !WIFSTOPPED(status)) {
fprintf(stderr, "Not stopped?\n");
exit(1);
}
}
/*
* print value when changed
*/
void outlonghex(unsigned long old, unsigned long new) {
if (old == new)
fprintf(stderr, " ");
else
fprintf(stderr, " %08lx", new);
}
int
main(int argc, char **argv, char **envp){
pid_t p0, p;
if (argc <= 1) {
fprintf(stderr, "Usage: %s command args -or- %s -p pid\n",
argv[0], argv[0]);
exit(1);
}
if (argc >= 3 && !strcmp(argv[1], "-p")) {
pid = p = atoi(argv[2]);
signal(SIGINT, interrupt);
/*
* attach to specified process
*/
my_ptrace_void(PTRACE_ATTACH, p, 0, 0);
my_wait(p, EXPECT_STOPPED, SIGSTOP);
set_sysgood(p);
/*
* we stopped the program in the middle of what it was doing
* continue it, and make it stop at the next syscall
*/
my_ptrace_void(PTRACE_SYSCALL, p, 0, 0);
} else {
void (*oldsig)(int);
/*
* fork off a child that executes the specified command
*/
/*
* The parent process will send a signal to the child
* and do a wait() to wait until the child stops.
* If the signal arrives before the child has said
* PTRACE_TRACEME, then maybe the child is killed, or
* maybe the signal is ignored and we wait forever, or
* maybe the child is stopped but we are not tracing.
* So, let us arrange for the child to signal the parent
* when it has done the PTRACE_TRACEME.
*/
/* prepare both parent and child for signal */
oldsig = signal(SIGUSR1, sigusr1);
if (oldsig == SIG_ERR) {
perror("signal");
exit(1);
}
/* child needs parent pid */
p0 = getpid();
p = fork();
if (p == (pid_t) -1) {
perror("fork");
exit(1);
}
if (p == 0) { /* child */
my_ptrace_void(PTRACE_TRACEME, 0, 0, 0);
/* tell parent that we are ready */
my_kill(p0, SIGUSR1);
/* wait for parent to start tracing us */
while (!got_sig) ;
/*
* the first thing the parent will see is
* 119: sigreturn - the return from the signal handler
*/
/* exec the given process */
argv[argc] = 0;
execve(argv[1], argv+1, envp);
exit(1);
}
/* wait for child to get ready */
while (!got_sig) ;
/*
* tell child that we got the signal
* this kill() will stop the child
*/
my_kill(p, SIGUSR1);
my_wait(p, EXPECT_STOPPED, SIGUSR1);
set_sysgood(p);
my_ptrace_void(PTRACE_SYSCALL, p, 0, (void *) SIGUSR1);
}
/*
* trace the victim's syscalls
*/
while (1) {
int syscall;
struct user_regs_struct u_in, u_out;
my_wait(p, EXPECT_STOPPED, SIGSYSTRAP);
my_ptrace_void(PTRACE_GETREGS, p, 0, &u_in);
syscall = u_in.orig_eax;
fprintf(stderr, "SYSCALL %3d:", syscall);
outlonghex(-38, u_in.eax); /* seems constant */
fprintf(stderr, " %08lx %08lx %08lx",
u_in.ebx, u_in.ecx, u_in.edx);
if (syscall-1 >= 0 && syscall-1 < SIZE(syscall_names) &&
syscall_names[syscall-1])
fprintf(stderr, " /%s", syscall_names[syscall-1]);
fprintf(stderr, "\n");
if (syscall == __NR_execve) {
long *regs = 0; /* relative address 0 in user area */
long eax;
my_ptrace_void(PTRACE_SYSCALL, p, 0, 0);
my_wait(p, EXPECT_STOPPED, SIGSYSTRAP);
/*
* For a successful execve we get one more trap
* But was this call successful?
*/
eax = my_ptrace_read(PTRACE_PEEKUSER, p, ®s[EAX],0);
if (eax == 0) {
fprintf(stderr, "SYSCALL execve, once more\n");
/* the syscall return - no "good" bit */
my_ptrace_void(PTRACE_SYSCALL, p, 0, 0);
my_wait(p, EXPECT_STOPPED, SIGTRAP);
}
} else {
/* wait for syscall return */
my_ptrace_void(PTRACE_SYSCALL, p, 0, 0);
if (syscall == __NR_exit ||
syscall == __NR_exit_group) {
my_wait(p, EXPECT_EXITED, 0);
exit(0);
}
my_wait(p, EXPECT_STOPPED, SIGSYSTRAP);
}
my_ptrace_void(PTRACE_GETREGS, p, 0, &u_out);
fprintf(stderr, " RETURN %3d:", syscall);
outlonghex(u_in.eax, u_out.eax);
outlonghex(u_in.ebx, u_out.ebx);
outlonghex(u_in.ecx, u_out.ecx);
outlonghex(u_in.edx, u_out.edx);
fprintf(stderr, "\n");
my_ptrace_void(PTRACE_SYSCALL, p, 0, 0);
}
return 0;
}
For each process there is a variable pdeath_signal,
that is initialized to 0 after fork() or clone().
It gives the signal that the process should get when its parent dies.
This variable can be set using
prctl(PR_SET_PDEATHSIG, sig);
and read out using
prctl(PR_GET_PDEATHSIG, &sig);
This construct can be used in thread libraries: when the
manager thread dies, all threads managed by it should
clean up and exit. E.g.:
prctl(PR_SET_PDEATHSIG, SIGHUP); /* set pdeath sig */
if (getppid() == 1) /* parent died already? */
kill(getpid(), SIGHUP);
File naming in a Unix-like system can be described from the user space
point of view and from the kernel point of view. On a Unix-like system,
a user or user program sees a single file hierarchy, rooted at /.
A full pathname of a file, like /usr/games/lib/hack/scores
describes the path from the root of the tree to the given file.
The current working directory is a marked node in the tree.
Pathnames not starting with / are relative with respect to the cwd.
(Thus, if the cwd is /home/aeb, then bin/findgr refers to
/home/aeb/bin/findgr and ../asm refers to
/home/asm.)
The name . (when initial in a pathname) refers to the cwd.
The names . and .. relative to some directory D
refer to D and the parent directory of D, respectively.
With the original Unix, the empty string was a name for the current
working directory. POSIX made this illegal.
That was the user picture. That files live in different filesystems
on different devices is to a first approximation invisible.
(If one looks more closely, then an NFS-mounted filesystem does not
quite have Unix semantics. FAT filesystems do not have Unix attributes
like owner and permissions. Etc.)
If she has the appropriate capabilities, the user can modify the big
file hierarchy by mounting or unmounting block devices. Given a
Zip disk or a compact flash card, or a floppy, or a CD or so, a command like
mount -t vfat /dev/sda4 /zip
will attach the file hierarchy found on /dev/sda4 to the node
named /zip, so that after this call /zip/a refers to
the file /a on this disk, and /zip itself refers to
/ on this disk. In particular, owner and permissions
of /zip will in general change. (Formulated differently:
no inodes change, but after the mount the name /zip names
a different inode.)
The directory /zip is called the mount point.
Note that if the mount point was a nonempty directory, the files below it
are no longer accessible using full pathnames through the mount point:
If there was a /zip/a before the mount command, then this file
can no longer be accessed by this name after the command. On the other hand,
if some user process had current working directory /zip or
/zip/b, this file will still be accessible using the name
./a (or just a) and ../a, respectively.
We see that the current working directory really is an inode, not a string.
Altogether, the interpretation of a filename depends on the root directory,
the current working directory, and the list of mounts.
The current working directory is private for each process, and a
process can change its current working directory using the chdir()
system call.
In ancient Unix, the root directory was the same for all processes.
However, 4.2 BSD made the root directory private for each process,
just like the current working directory, and introduced the chroot()
system call.
The chroot system call serves to specify which directory is pointed at
by the users' /. It is often used in security-conscious environments,
say by an ftp server, where the purpose is to keep anonymous users inside the
chroot jail.
This gives a new example of a name space with interesting topology:
the chroot() system call does not change the current working directory,
so . can now lie outside the tree rooted at /.
In all traditional Unix versions, the list of mounts is global.
Plan9
introduced the idea of namespaces where each process could
see an entirely different tree (or forest) because also the
mounts are private for each process. Linux is slowly following this
example. Currently a special version of the fork() system call
will fork off a child with a private copy of the name space of its parent,
so that subsequent chdir() or chroot() or mount() calls in one do not
influence the other. More details later.
Filesystem character set
So far we have not given any thoughts to the question how a filename
is coded. What sequence of bits or bytes is used for a file called
"/bin/ls"?
ASCII
The classical Unix answer is that filenames are in ASCII,
mostly because everything is in ASCII. The C statement
printf("Hello world!\n");
uses a string of which the first byte is 'H' with value
0110 (octal), that is, 72 (decimal), that is, 0x48 (hexadecimal),
that is 01001000 (binary). Inside the program it doesn't matter
what the corresponding glyph looks like, but as soon as this value
is printed we recognize the shape as that of an H.
If the string is used as a filename, it will be stored on disk
in some way, such that a later lookup finds the same string again.
ISO 8859-1
Bytes have 8 bits, and when there no longer was any need to use the
high order bit as (anti)parity bit, more code points became
available, and Western Europe started using ISO 8859-1 (also called Latin-1),
an extension of ASCII in which the high order half is used for national
characters, so that the Swedes can have
and the Danes
rdgrd med flde.
This is still the default character set on the WWW. But then in
Central Europe other symbols were needed and ISO 8859-2 was defined,
and the Russians invented KOI-8, and the Japanese Shift-JIS and the
Chinese GB5, and Western Europe needed the Euro, etc. etc.
The international situation became as bad as the situation in the
English speaking world had been before ASCII, with hundreds of
different codes.
ExerciseThe above recipe for "rdgrd med flde"
is in ISO 8859-1. What happens if you tell your browser that it
is ISO 8859-2? ISO 8859-15? What happens when you paste the text
into an xterm?
Unicode
For a global character set the situation in Japan and China is
worst. Both countries have a large number of characters - large
dictionaries may give 50000 or more. If one byte suffices for
28 = 256 symbols, two bytes suffice for
216 = 65536.
Enough for China, or for Japan, but not enough for both.
However, the Japanese character set is derived from the Chinese one,
and many characters are the same, or almost the same.
A committee did the "unification" of both alphabets,
and Unicode was born: a 16-bit character set with
symbols for every character used in any of the world's languages.
These days the whole world is slowly converting to Unicode.
RedHat 8.0 is the first Linux distribution that uses Unicode
by default.
UTF-8
The body of Unix programs is far too large to start rewriting
everything. But the 16-bit Unicode values do not fit well into
the traditional Unix scheme with strings terminated by a NUL-byte.
Indeed, in Unicode 'H' is coded U+0048, and at first sight that
consists of the two bytes 00 and 48 (hex).
To solve this problem the UTF-8 scheme of coding Unicode was
developed. The convention is this:
The x-es are the bits to be coded, and the code is shown.
Values in the range 0-127 are coded by a single byte.
Values below 211 are coded by two bytes.
Values below 216 are coded by three bytes. Etc.
Thus, hex ABCD, that is, binary 1010101111001101 is coded by the
three bytes 11101010 10101111 10001101.
The advantage of this code is that the only way bytes in the range
0-127 occur is as themselves. Never as part of a multi-byte code.
Very convenient for Americans: the conversion from ASCII to
Unicode coded in UTF-8 is trivial: do nothing.
This code is called FileSystem-Safe because NULs and /
and . characters, the only bytes the kernel looks at
when handling filenames, do not occur in unexpected ways.
In Western Europe one has a few accented letters and these now
require 2 bytes. That is not serious. In China and Japan everything
that used to take 2 bytes now takes 3 bytes, and people are unhappy.
So, UTF-16, the 16-bit encoding of Unicode is more popular there.
(Apart from the fact that some people in Japan are unhappy because
of the unification.)
Java uses Unicode internally and makes locale-dependent filenames.
% cat > pi.java
import java.io.*;
class Main {
public static void main(String[] args) {
String s = "\u03c0"; // pi
try {
FileWriter out = new FileWriter(s);
out.write(s);
out.flush();
out.close();
} catch (IOException ee) {
System.out.println("Error writing file "+s+": "+ee);
}
}
}
% javac pi.java
% java Main
% ls
? Main.class pi.java
% LC_ALL=nl_NL.utf8
% export LC_ALL
% java Main
% ls
? Main.class pi.java �
Here the letter pi was converted into a question mark in the C locale,
and into cf 80 (hex) in an utf8 locale. Note that cf 80 is binary
11001111 10000000 and hence codes for 01111000000, that is U+03c0.
On a uxterm the filename is shown with a nice Greek pi.
Many Microsoft filesystems encode information about the
character set the filenames are in. Unix does not do that,
and does not really view filenames as sequences of characters -
it views filenames as sequences of bytes.
A Unix filesystem has inodes as basic entities.
An inode (index node) contains information about the type, owner,
size, permissions and timestamps of the file, and points to
where on disk this file lives. The inode has room for a short
list of block numbers, so if the file is small this suffices,
but otherwise indirect blocks are used, that themselves
contain a list of block numbers. If this still does not suffice
doubly and triply indirect blocks are used.
A file is nothing but an inode. In particular, a file is not
characterized by a name. There are special files, called directories,
that contain names and the numbers of the corresponding inodes.
From a name one can find, by a lookup process, which inode number
belongs to that name. From an inode one cannot find a name.
There may be zero, one, two, or more names for the same file.
The filesystem keeps track of the number of names a file has,
and the system keeps track of the processes that currently have
an open file descriptor for the file. When the last name is
removed from the filesystem, and all file descriptors
for the file have been closed, the blocks that the file occupied
can be put onto the free list.
Links
Names of a file are also called links to that file.
Or hard links if it is necessary to distinguish them
from soft links. All hard links are equivalent.
A soft link, or symbolic link, symlink in short, is a very
different animal. It is a very small file that contains the
name of another file, and has the property that the system
name lookup process will usually automatically follow this redirection.
All hard links to a file live in the same filesystem.
Symlinks to the file can live in different filesystems.
The filesystem keeps track of the number of hard links
to a file, but not of the number of symlinks.
If you remove the file a symlink pointed to, the symlink
becomes a dangling symlink.
Since the Unix file hierarchy should be a tree, there should be
precisely one hard link to a directory.
Symlinks however can point at arbitrary path names.
A file tree walker should be careful not to follow symlinks
(or otherwise keep track of all files visited).
Device special files
The Unix philosophy is: "everything is a file". That makes life
easy, the same system calls are used to read from any device.
Special device nodes are inodes that refer to a device rather
than to a file. They come in two kinds: block special devices
are block-structured, allow random access, and, in case they
contain a filesystem, can be mounted. The typical example is a disk.
All (other) devices are character special devices.
One has tapes, scanners, modems, etc. Also block special devices
can be often accessed via a character special device node.
Device special files are very simple: the inode contains a pair
of small integers (the major and minor device numbers), and
these numbers are used by the system as index in some table
to find the driver for the device.
Other file types
Depending on the Unix version there may be other types of files
other than regular files, directories, and device special files.
Most versions know about fifos, symlinks and sockets.
Try man 2 stat on a Linux system for a list of types.
Sparse files
A Unix filesystem may have sparse files: files with holes.
The holes can be read, and then read as all zeroes.
They do not take (much) space: the actual data blocks are not written.
Sometimes this is important when space is scarce, like on a rescue floppy.
This will create a file with one byte 'A', then a hole, then
another byte 'B'. Look at the size of the resulting file
(measured in 512-byte sectors):
% ./mkhole 1
The file AB has size 2 and takes 2 sectors
% ./mkhole 1023
The file AB has size 1024 and takes 2 sectors
% ./mkhole 1024
The file AB has size 1025 and takes 4 sectors
% ./mkhole 12287
The file AB has size 12288 and takes 4 sectors
% ./mkhole 12288
The file AB has size 12289 and takes 6 sectors
% ./mkhole 274431
The file AB has size 274432 and takes 6 sectors
% ./mkhole 274432
The file AB has size 274433 and takes 8 sectors
% ./mkhole 67383295
The file AB has size 67383296 and takes 8 sectors
% ./mkhole 67383296
The file AB has size 67383297 and takes 10 sectors
% ./mkhole 2147483646
The file AB has size 2147483647 and takes 10 sectors
% ls -l AB
-rw-r--r-- 1 aeb users 2147483647 Sep 28 21:51 AB
% du AB
5 AB
% ./mkhole 2147483647
File size limit exceeded
Apparently this filesystem uses 1024-byte blocks, and has
a maximum file size 2147483647. The file of this maximum size,
but with a giant hole, takes 5 blocks.
Most of what was said earlier about the Unix filesystem holds for
the Linux situation. But there are two important differences.
On the one hand, there is a new kind of objects, dentries.
On the other hand the situation with one large file hierarchy is left.
Every process may see a different hierarchy.
Also, a single filesystem may be visible several places in the tree.
Dentries
The Unix name resolution process resolves a name into an inode,
and no trace of the name remains. In particular, a working directory
is known only as inode, and a command like pwd has to
go to great trouble (stat the current directory, find device and inode number,
then chdir(".."), stat all entries in that directory until
an entry with the same device and inode number is found; if found we know
the last component of the name; now repeat), and may not find the name,
for example because of problems with permissions.
Linux does things in two stages. First the name is resolved into a
dentry ("directory entry"). Then the dentry is resolved into
an inode. Some names are needed very frequently, such as the files used
by the C library. A dentry cache speeds things up.
Having dentries allows Linux to do what Unix could not,
namely implement a getcwd() system call.
Exercise
Play with pwd and getcwd() in several situations.
(i) Explain the following. (This is with bash.)
% pwd
/home/aeb
% ln -s /usr/bin ub
% cd ub
% echo $PWD
/home/aeb/ub
% pwd
/home/aeb/ub
% ls -ld ../bin
drwxr-xr-x 3 root root 44528 2002-10-27 18:56 ../bin
% cd ..
% ls -ld bin
drwxr-xr-x 3 aeb users 3072 2002-10-26 22:31 bin
% pwd
/home/aeb
How come that bin has different owner and size?
Try the same after first doing
% set -o physical
%
(ii) pwd may give the wrong answer, or no answer at all.
Try
% mkdir aa
% cd aa
% mv ../aa ../bb
% echo $PWD
/home/aeb/aa
% pwd
/home/aeb/aa
% /bin/pwd
/home/aeb/bb
Try the same after first doing
% set -o physical
%
and see that pwd is silent.
(iii) The above shows that there is a layer of user space software
between the kernel image of things and the user. For testing it may
be less confusing to write a small C program that more directly
(there is still the C library) reports what the kernel says.
% mkdir aa
% cd aa
% getcwd
/home/aeb/aa
% mv ../aa ../bb
% getcwd
/home/aeb/bb
% rmdir ../bb
% getcwd
getcwd: No such file or directory
This shows that the current working directory of a process
can be deleted (when it is empty). The inode still exists
as long as the process is there, but the name has gone away.
Mounts
Mounting a filesystem at a pathname means that that path
now points to the root of that filesystem, instead of at the
part of the tree it used to point at.
This is Unix semantics. It means that a new inode will be associated
with the path after the mount. In particular, the permissions of the
directory (it usually is a directory one mounts on) may well change.
It also means that part of the old tree may have become invisible
to everybody, except for processes that had their working directory
below the moint point.
This already shows that also classical Unix knows about the possibility
of a file hierarchy that is a forest instead of a tree, more or less
as an accident. Linux allows many things unknown in classical Unix.
A "bind" mount attaches an already mounted filesystem somewhere else,
so that a filesystem can be multiply mounted. (And in such a situation
multiple umount calls will be required.)
ExercisePlay withmountin several situations.
You may have to be root.
# mkdir tmp
# mount --bind /tmp ./tmp
Now ./tmp and /tmp are different names that refer
to the same subtree.
# cd tmp
# umount /home/aeb/tmp
umount: /home/aeb/tmp: device is busy
# cd /tmp
# umount /home/aeb/tmp
#
This shows that the current working directory is not just an inode.
Although tmp and /home/aeb/tmp are two names
for the same directory, using one keeps the mount busy,
using the other doesn't.
# cd /home/aeb/tmp
# mount --bind /tmp /home/aeb/tmp
# getcwd
/home/aeb/tmp
# ls
. ..
# ls /home/aeb/tmp
. .. .X0-lock .X11-unix
# umount /home/aeb/tmp
What happens here? The current working directory disappears from
view since it is overmounted. This shows that the current working directory
is not just a string: ls . and ls /home/aeb/tmp
give different results because . and /home/aeb/tmp
are different directories (hence have different inodes). One can check
the inode number of a file using ls -id file.
# mkdir /home/aeb/foo
# mount --bind /tmp /home/aeb/tmp
# mount --move /home/aeb/tmp /home/aeb/foo
# ls /home/aeb/foo
. .. .X0-lock .X11-unix
# umount /home/aeb/foo
This shows that it is possible to move mounted trees around.
Per-process namespaces
Since 2.4.19/2.5.2, the clone() system call, a generalization
of Unix fork() and BSD vfork(), may have the
CLONE_NEWNS flag, that says that all mount information must be copied.
Afterwards, mount, chroot, pivotroot and similar namespace changing
calls done by this new process do influence this process and its children,
but not other processes.
In particular, the virtual file /proc/mounts that lists
the mounted filesystems, is now a symlink to
/proc/self/mounts - different processes may live in
entirely different file hierarchies.
ExercisePlay with this in several situations. You may have to be root.
This program starts with a namespace that is a copy of the
global one, and then forks off a shell (/bin/ash,
a simple shell, easier to handle than /bin/sh)
and waits for it to finish. If this is under X, you can give
a few commands xterm & to ash so as to start some
shells in the new namespace. Check that mounts and umounts
done in the new namespace are invisible in the old namespace.
BUGS: The program mount does not know about this feature yet,
so updates /etc/mtab. Reality is visible in
/proc/mounts. Some kernel versions have a bug that
would cause the new process to have a strange working directory.
Probably that is avoided if this is started with a working directory
/ or so - not in some mounted filesystem.
In order to use a file (not just its name), one has to open it.
The result of the open() system call is a small integer,
called a file descriptor, index in a per-process table
of open files (also called file descriptions) and subsequent
read and write accesses will use this integer, often called fd.
A funny part of the socket API is that one can transmit file descriptions
over a socket, using the ancillary data part of the sendmsg()
and recvmsg() system calls. The sender opens a file, gets
file descriptor 5 referring to the corresponding open file description,
and sends the integer 5 using sendmsg(). The receiver already
had open files numbered 0-8, and when he does recvmsg(), he
gets the value 9 as file descriptor referring to the same open file.
Filesystems are containers of files, that are stored, probably in
a directory tree, together with attributes, like size, owner,
creation date and the like.
A filesystem has a type. It defines how things are arranged
on the disk. For example, one has the types minix, ext2, reiserfs,
iso9660, vfat, hfs.
The traditional DOS filesystem types are FAT12 and FAT16.
Here FAT stands for File Allocation Table: the disk is divided
into clusters, the unit used by the file allocation,
and the FAT describes which clusters are used by which files.
Let us describe the FAT filesystem in some detail.
The FAT12/16 type is important, not only because of
the traditional use, but also because it is useful for
data exchange between different operating systems, and
because it is the filesystem type used by all kinds of devices,
like digital cameras.
Layout
First the boot sector (at relative address 0),
and possibly other stuff. Together these are the Reserved Sectors.
Usually the boot sector is the only reserved sector.
Then the FATs (following the reserved sectors; the number of
reserved sectors is given in the boot sector, bytes 14-15;
the length of a sector is found in the boot sector, bytes 11-12).
Then the Root Directory (following the FATs; the number of FATs
is given in the boot sector, byte 16; each FAT has a number
of sectors given in the boot sector, bytes 22-23).
Finally the Data Area (following the root directory; the number
of root directory entries is given in the boot sector, bytes 17-18,
and each directory entry takes 32 bytes; space is rounded up to
entire sectors).
Boot sector
The first sector (512 bytes) of a FAT filesystem is the boot sector.
In Unix-like terminology this would be called the superblock. It contains
some general information.
First an explicit example (of the boot sector of a DRDOS boot floppy).
(See
here for the
complete sector. And also a
MSDOS example)
The 2-byte numbers are stored little endian (low order byte first).
Bytes Content
0-2 Jump to bootstrap (E.g. eb 3c 90; on i86: JMP 003E NOP.
One finds either eb xx 90, or e9 xx xx.
The position of the bootstrap varies.)
3-10 OEM name/version (E.g. "IBM 3.3", "MSDOS5.0", "MSWIN4.0".
Various format utilities leave their own name, like "CH-FOR18".
Sometimes just garbage. Microsoft recommends "MSWIN4.1".)
/* BIOS Parameter Block starts here */
11-12 Number of bytes per sector (512)
Must be one of 512, 1024, 2048, 4096.
13 Number of sectors per cluster (1)
Must be one of 1, 2, 4, 8, 16, 32, 64, 128.
A cluster should have at most 32768 bytes. In rare cases 65536 is OK.
14-15 Number of reserved sectors (1)
FAT12 and FAT16 use 1. FAT32 uses 32.
16 Number of FAT copies (2)
17-18 Number of root directory entries (224)
0 for FAT32. 512 is recommended for FAT16.
19-20 Total number of sectors in the filesystem (2880)
(in case the partition is not FAT32 and smaller than 32 MB)
21 Media descriptor type (f0: 1.4 MB floppy, f8: hard disk; see below)
22-23 Number of sectors per FAT (9)
0 for FAT32.
24-25 Number of sectors per track (12)
26-27 Number of heads (2, for a double-sided diskette)
28-29 Number of hidden sectors (0)
Hidden sectors are sectors preceding the partition.
/* BIOS Parameter Block ends here */
30-509 Bootstrap
510-511 Signature 55 aa
The signature is found at offset 510-511. This will be the end of
the sector only in case the sector size is 512.
The ancient media descriptor type codes are:
For 8" floppies:
fc, fd, fe - Various interesting formats
For 5.25" floppies:
Value DOS version Capacity sides tracks sectors/track
ff 1.1 320 KB 2 40 8
fe 1.0 160 KB 1 40 8
fd 2.0 360 KB 2 40 9
fc 2.0 180 KB 1 40 9
fb 640 KB 2 80 8
fa 320 KB 1 80 8
f9 3.0 1200 KB 2 80 15
For 3.5" floppies:
Value DOS version Capacity sides tracks sectors/track
fb 640 KB 2 80 8
fa 320 KB 1 80 8
f9 3.2 720 KB 2 80 9
f0 3.3 1440 KB 2 80 18
f0 2880 KB 2 80 36
For RAMdisks:
fa
For hard disks:
Value DOS version
f8 2.0
This code is also found in the first byte of the FAT.
IBM defined the media descriptor byte as 11111red, where r
is removable, e is eight sectors/track, d is double sided.
FAT16
FAT16 uses the above BIOS Parameter Block, with some extensions:
11-27 (as before)
28-31 Number of hidden sectors (0)
32-35 Total number of sectors in the filesystem
(in case the total was not given in bytes 19-20)
36 Logical Drive Number (for use with INT 13, e.g. 0 or 0x80)
37 Reserved (Earlier: Current Head, the track containing the Boot Record)
Used by Windows NT: bit 0: need disk check; bit 1: need surface scan
38 Extended signature (0x29)
Indicates that the three following fields are present.
39-42 Serial number of partition
43-53 Volume label or "NO NAME "
54-61 Filesystem type (E.g. "FAT12 ", "FAT16 ", "FAT ", or all zero.)
62-509 Bootstrap
510-511 Signature 55 aa
FAT32
FAT32 uses an extended BIOS Parameter Block:
11-27 (as before)
28-31 Number of hidden sectors (0)
32-35 Total number of sectors in the filesystem
36-39 Sectors per FAT
40-41 Mirror flags
Bits 0-3: number of active FAT (if bit 7 is 1)
Bits 4-6: reserved
Bit 7: one: single active FAT; zero: all FATs are updated at runtime
Bits 8-15: reserved
42-43 Filesystem version
44-47 First cluster of root directory (usually 2)
48-49 Filesystem information sector number in FAT32 reserved area (usually 1)
50-51 Backup boot sector location or 0xffff if none (usually 6)
52-63 Reserved
64 Logical Drive Number (for use with INT 13, e.g. 0 or 0x80)
65 Reserved (used by Windows NT)
66 Extended signature (0x29)
Indicates that the three following fields are present.
67-70 Serial number of partition
71-81 Volume label
82-89 Filesystem type ("FAT32 ")
The old 2-byte fields "total number of sectors" and
"number of sectors per FAT" are now zero; this information
is now found in the new 4-byte fields.
An important improvement is the "First cluster of root directory"
field. Earlier, the root directory was not part of the Data Area,
and was in a known place with a known size, and hence was unable to grow.
Now the root directory is just somewhere in the Data Area.
FAT
The disk is divided into clusters. The number of sectors per cluster
is given in the boot sector byte 13.
The File Allocation Table has one entry per cluster.
This entry uses 12, 16 or 28 bits for FAT12, FAT16 and FAT32.
The first two FAT entries
The first cluster of the data area is cluster #2.
That leaves the first two entries of the FAT unused.
In the first byte of the first entry a copy of the media descriptor is stored.
The remaining bits of this entry are 1.
In the second entry the end-of-file marker is stored.
The high order two bits of the second entry are sometimes,
in the case of FAT16 and FAT32, used for dirty volume management:
high order bit 1: last shutdown was clean;
next highest bit 1: during the previous mount no disk
I/O errors were detected.
(Historically this description has things backwards: DOS 1.0 did not have
a BIOS Parameter Block, and the distinction between single-sided and
double-sided 5.25" 360K floppies was indicated by the first byte in
the FAT. DOS 2.0 introduced the BPB with media descriptor byte.)
FAT12
Since 12 bits is not an integral number of bytes, we have to specify
how these are arranged. Two FAT12 entries are stored into three bytes;
if these bytes are uv,wx,yz then the entries are xuv and yzw.
Possible values for a FAT12 entry are:
000: free,
002-fef: cluster in use; the value given is the
number of the next cluster in the file,
ff0-ff6: reserved,
ff7: bad cluster,
ff8-fff: cluster in use, the last one in this file.
Since the first cluster in the data area is numbered 2,
the value 001 does not occur.
DOS 1.0 and 2.0 used FAT12. The maximum possible size of a FAT12
filesystem (volume) was 8 MB (4086 clusters of at most 4 sectors each).
FAT16
DOS 3.0 introduced FAT16. Everything very much like FAT12,
only the FAT entries are now 16 bit. Possible values for FAT16 are:
0000: free, 0002-ffef: cluster in use; the value given is the
number of the next cluster in the file, fff0-fff6: reserved,
fff7: bad cluster, fff8-ffff: cluster in use, the last one in this file.
Now the maximum volume size was 32 MB, mostly since DOS 3.0 used
16-bit sector numbers. This was fixed in DOS 4.0 that uses
32-bit sector numbers. Now the maximum possible size of a
FAT16 volume is 2 GB (65526 clusters of at most 64 sectors each).
FAT32
FAT32 was introduced in Windows 95 OSR 2.
Everything very much like FAT16, only the FAT entries are now 32 bits
of which the top 4 bits are reserved. The bottom 28 bits have meanings
similar to those for FAT12, FAT16.
For FAT32:
Cluster size used: 4096-32768 bytes.
Microsoft operating systems use the following rule to distinguish
between FAT12, FAT16 and FAT32. First, compute the number of clusters
in the data area (by taking the total number of sectors, subtracting
the space for reserved sectors, FATs and root directory, and dividing,
rounding down, by the number of sectors in a cluster).
If the result is less that 4085 we have FAT12. Otherwise, if it is
less than 65525 we have FAT16. Otherwise FAT32.
Microsoft operating systems use fff, ffff, xfffffff as end-of-clusterchain
markers, but various common utilities may use different values.
Bytes Content
0-10 File name (8 bytes) with extension (3 bytes)
11 Attribute - a bitvector. Bit 0: read only. Bit 1: hidden.
Bit 2: system file. Bit 3: volume label. Bit 4: subdirectory.
Bit 5: archive. Bits 6-7: unused.
12-21 Reserved (see below)
22-23 Time (5/6/5 bits, for hour/minutes/doubleseconds)
24-25 Date (7/4/5 bits, for year-since-1980/month/day)
26-27 Starting cluster (0 for an empty file)
28-31 Filesize in bytes
We see that the fifth entry in the example above is the volume label,
while the other entries are actual files.
The "archive" bit is set when the file is created or modified.
It is cleared by backup utilities. This allows one to do
incremental backups.
As a special kludge to allow undeleting files that were deleted
by mistake, the DEL command will replace the first byte of the
name by 0xe5 to signify "deleted".
As an extraspecial kludge, the first byte 0x05 in a directory entry
means that the real name starts with 0xe5.
The first byte of a name must not be 0x20 (space).
Short names or extensions are padded with spaces.
Special ASCII characters 0x22 ("), 0x2a (*), 0x2b (+), 0x2c (,),
0x2e (.), 0x2f (/), 0x3a (:), 0x3b (;), 0x3c (<), 0x3d (=),
0x3e (>), 0x3f (?), 0x5b ([), 0x5c (\), 0x5d (]), 0x7c (|)
are not allowed.
The first byte 0 in a directory entry means that the directory
ends here. (Now the Microsoft standard says that all following
directory entries should also have first byte 0, but the Psion's OS,
EPOC, works with a single terminating 0.)
Subdirectories start with entries for . and .., but the root directory
does not have those.
VFAT
In Windows 95 a variation was introduced: VFAT.
VFAT (Virtual FAT) is FAT together with long filenames (LFN),
that can be up to 255 bytes long. The implementation is an
ugly hack. These long filenames are stored in special directory entries.
A special entry looks like this:
Bytes Content
0 Bits 0-4: sequence number; bit 6: final part of name
1-10 Unicode characters 1-5
11 Attribute: 0xf
12 Type: 0
13 Checksum of short name
14-25 Unicode characters 6-11
26-27 Starting cluster: 0
28-31 Unicode characters 12-13
These special entries should not confuse old programs, since they
get the 0xf (read only / hidden / system / volume label) attribute
combination that should make sure that all old programs will ignore them.
The long name is stored in the special entries, starting with the tail end.
The Unicode characters are of course stored little endian.
The sequence numbers are ascending, starting with 1.
Now an ordinary directory entry follows these special entries,
and it has the usual info (file size, starting cluster, etc.),
and a short version of the long name.
Also the unused space in directory entries is used now:
bytes 13-17: creation date and time (byte 13: centiseconds 0-199,
bytes 14-15: time as above, bytes 16-17: date as above),
bytes 18-19: date of last access.
(And byte 12 is reserved for Windows NT - it indicates whether
the filename is in upper or in lower case; byte 20 is reserved for OS/2.)
Old programs might change directories in ways that can separate
the special entries from the ordinary one. To guard against that
the special entries have in byte 13 a checksum of the short name:
int i; unsigned char sum = 0;
for (i = 0; i < 11; i++) {
sum = (sum >> 1) + ((sum & 1) << 7); /* rotate */
sum += name[i]; /* add next name byte */
}
An additional check is given by the sequence number field.
It numbers the special entries belonging to a single LFN 1, 2, ...
where the last entry has bit 6 set.
The short name is derived from the long name as follows:
The extension is the extension of the long name, truncated to length
at most three. The first six bytes of the short name equal the first
six nonspace bytes of the long name, but bytes + , ; = [ ], that are
not allowed under DOS, are replaced by underscore. Lower case is
converted to upper case. The final two (or more, up to seven, if necessary)
bytes become ~1, or, if that exists already, ~2, etc.,
up to ~999999.
VFAT is used in the same way on each of FAT12, FAT16, FAT32.
FSInfo sector
FAT32 stores extra information in the FSInfo sector, usually sector 1.
Bytes Content
0-3 0x41615252 - the FSInfo signature
4-483 Reserved
484-487 0x61417272 - a second FSInfo signature
488-491 Free cluster count or 0xffffffff (may be incorrect)
492-495 Next free cluster or 0xffffffff (hint only)
496-507 Reserved
508-511 0xaa550000 - sector signature
Variations
One meets slight variations on the FAT filesystem in many places.
Here a description of the
version used for the Xbox.
The ext2 filesystem was developed by R�y Card and added to
Linux in version 0.99pl7 (March 1993). It was a greatly
improved version of his earlier ext filesystem (that again
was a small improvement on the minix filesystem), and uses
ideas from the Berkeley Fast Filesystem.
It is really fast and robust. The main reason people want
something else nowadays is that on the modern very large
disks an invocation of e2fsck (to check filesystem
integrity after a crash or power failure, or just after some
predetermined number of boots) takes a long time, like one hour.
Layout
First, space is reserved for a boot block (1024 bytes).
This is not part of the filesystem proper, and ext2 has no
opinion about what should be there.
This boot block is followed by a number of ext2 block groups.
Each block group starts with a copy of the superblock,
then a copy of the group descriptors (for the entire filesystem - ach),
then a block bitmap,
then an inode bitmap,
then an inode table,
then data blocks.
An attempt is made to have the data blocks of a file in the
same block group as its inode, and as much as possible
consecutively, thus minimizing the amount of seeking the disk has to do.
Having a copy of superblock and group descriptors
in each block group seemed reasonable when a filesystem
had only a few block groups. Later, with thousands of
block groups, it became clear that this redundancy was ridiculous
and meaningless. (And for a sufficiently large filesystem
the group descriptors alone would fill everything, leaving no
room for data blocks.) So, later versions of ext2 use a sparse
distribution of superblock and group descriptor copies.
The structure of ext2 can be read in the kernel source.
The data structures are defined in ext2_fs.h,
ext2_fs_i.h, ext2_fs_sb.h (in include/linux)
and the code is in fs/ext2.
ExerciseDocd /tmp; dd if=/dev/zero of=e2fs bs=1024 count=10000;
mke2fs -F e2fs; od -Ax -tx4 e2fs.
(This creates an empty ext2 filesystem
in the file /tmp/e2fs, and prints its contents.)
Compare the od output with the description below.
The superblock
First, the superblock (of the original ext2, later more fields were added).
struct ext2_super_block {
unsigned long s_inodes_count; /* Inodes count */
unsigned long s_blocks_count; /* Blocks count */
unsigned long s_r_blocks_count; /* Reserved blocks count */
unsigned long s_free_blocks_count;/* Free blocks count */
unsigned long s_free_inodes_count;/* Free inodes count */
unsigned long s_first_data_block; /* First Data Block */
unsigned long s_log_block_size; /* log(Block size) - 10 */
long s_log_frag_size; /* Fragment size */
unsigned long s_blocks_per_group; /* # Blocks per group */
unsigned long s_frags_per_group; /* # Fragments per group */
unsigned long s_inodes_per_group; /* # Inodes per group */
unsigned long s_mtime; /* Mount time */
unsigned long s_wtime; /* Write time */
unsigned long s_pad; /* Padding to get the magic signature*/
/* at the same offset as in the */
/* previous ext fs */
unsigned short s_magic; /* Magic signature */
unsigned short s_valid; /* Flag */
unsigned long s_reserved[243]; /* Padding to the end of the block */
};
The superblock contains information that is global to the
entire filesystem, such as the total number of blocks,
and the time of the last mount.
Some parameters, such as the number of blocks reserved for the
superuser, can be tuned using the tune2fs utility.
Having reserved blocks makes the system more stable. It means
that if a user program gets out of control and fills the entire
disk, the next boot will not fail because of lack of space
when utilities at boot time want to write to disk.
The magic signature is 0xef53. The signature is too small:
with random data one in every 2^16 blocks will have this value
at this offset, so that several hundred blocks will have the
ext2 superblock signature without being a superblock.
Modern filesystems use a 32-bit or 64-bit signature.
The group descriptors
Then, the group descriptors. Each block group has a
group descriptor, and all group descriptors for all block groups
are repeated in each group. All copies except the first (in
block group 0) of superblock and group descriptors are never used
or updated. They are just there to help recovering from a crash
or power failure.
The size of a block group depends on the chosen block size for the
ext2 filesystem. Allowed block sizes are 1024, 2048 and 4096.
The blocks of a block group are represented by bits in a bitmap
that fills one block, so with 1024-byte blocks a block group
spans 8192 blocks (8 MiB), while with 4096-byte blocks
a block group spans 32768 blocks (128 MiB).
When disks were small, small blocks were used to minimize the loss
in space due to rounding up filesizes to entire blocks. These days
the default is to use larger blocks, for faster I/O.
QuestionWhat percentage of the disk space is used (wasted)
by copies of superblock and group descriptors on a 128 GiB filesystem
with 1024-byte blocks? How large is the filesystem when all available
space is taken by the group descriptors?
struct ext2_group_desc
{
unsigned long bg_block_bitmap; /* Blocks bitmap block */
unsigned long bg_inode_bitmap; /* Inodes bitmap block */
unsigned long bg_inode_table; /* Inodes table block */
unsigned short bg_free_blocks_count; /* Free blocks count */
unsigned short bg_free_inodes_count; /* Free inodes count */
unsigned short bg_used_dirs_count; /* Directories count */
unsigned short bg_pad;
unsigned long bg_reserved[3];
};
Thus, a group descriptor takes 32 bytes, 18 of which are used.
The field bg_block_bitmap gives the block number of the
block allocation bitmap block. In that block the free blocks in the
block group are indicated by 1 bits.
Similarly, the field bg_inode_bitmap gives the block number
of the inode allocation bitmap.
The field bg_inode_table gives the starting block number
of the inode table for this block group.
These three fields are potentially useful at recovery time.
Unfortunately, there is almost no redundancy in a bitmap, so if
either a block with group descriptors or a block with a bitmap
is damaged, e2fsck will happily go on and destroy the
entire filesystem.
ProjectInvestigate how the redundancy present in an
ext2 filesystem could be used. Is it possible to detect that a
block bitmap or inode bitmap is damaged? Presently, the redundancy
present in the repeated superblocks and group descriptors is used
only when the user explicitly invokese2fsckwith parameter-bN, where N is the block number
of the superblock copy. (Now superblock N and group descriptor blocks
N+1.. are used.) How cane2fsckdetect automatically
that something is wrong, and select and switch to a copy that is better?
The inode table
Each inode takes 128 bytes:
struct ext2_inode {
unsigned short i_mode; /* File mode */
unsigned short i_uid; /* Owner Uid */
unsigned long i_size; /* Size in bytes */
unsigned long i_atime; /* Access time */
unsigned long i_ctime; /* Creation time */
unsigned long i_mtime; /* Modification time */
unsigned long i_dtime; /* Deletion Time */
unsigned short i_gid; /* Group Id */
unsigned short i_links_count; /* Links count, max 32000 */
unsigned long i_blocks; /* Blocks count */
unsigned long i_flags; /* File flags */
unsigned long i_reserved1;
unsigned long i_block[15]; /* Pointers to blocks */
unsigned long i_version; /* File version (for NFS) */
unsigned long i_file_acl; /* File ACL */
unsigned long i_dir_acl; /* Directory ACL */
unsigned long i_faddr; /* Fragment address */
unsigned char i_frag; /* Fragment number */
unsigned char i_fsize; /* Fragment size */
unsigned short i_pad1;
unsigned long i_reserved2[2];
};
History
When 16-bit uid's no longer sufficed (a PC, and more than one user?
yes, university machines handling the mail for more than 65000 people),
the part
unsigned long i_reserved2[2];
was replaced by
__u16 l_i_uid_high; /* High order part of uid */
__u16 l_i_gid_high; /* High order part of gid */
__u32 l_i_reserved2;
Also, i_version was renamed into i_generation.
This is for use with NFS. If a file is deleted, and later the
inode is reused, then a client on another machine, that still had
an open filehandle for the old file, must get an error return
upon access. This is achieved by changing i_generation.
The i_generation field of a file can be read and set using
the EXT2_IOC_GETVERSION and EXT2_IOC_SETVERSION ioctls.
ExerciseWrite the tiny program that can read and change
the ext2 version field of an inode. Get the ioctl definitions
from<linux/ext2_fs.h>.
File sizes
Look at a filesystem with block size B (e.g., 1024 or 4096).
The inode contains 12 pointers to direct blocks: the block numbers
of the first 12 data blocks. Files of size not more than 12*B bytes
(e.g., 12288 or 49152), do not need more.
The 13th element of the array i_block is a pointer to
an indirect block. That indirect block contains the
block numbers of B/4 data blocks. That suffices for files
of size not more than (B/4)*B + 12*B bytes (e.g., 274432 or 4243456).
The 14th element of the array i_block is a pointer to
a doubly indirect block. It contains the block numbers of
B/4 indirect blocks. That suffices for size not more than
(B/4)*(B/4)*B + (B/4)*B + 12*B bytes (e.g., 67383296 or 4299210752).
The 15th and last element of the array i_block is a pointer to
a triply indirect block. It contains the block numbers of B/4
doubly indirect blocks. That suffices up to
(B/4)*(B/4)*(B/4)*B + (B/4)*(B/4)*B + (B/4)*B + 12*B bytes
(e.g., 17247252480 or 4402345721856). Thus, this design allows for
files not larger than about 4 TB.
Other conditions may impose a lower limit on the maximum file size.
Sparse files are represented by having block numbers 0
represent holes.
ExerciseExplain the sizes given earlier for sparse
files in some ext2 filesystem.
Ext2 has fast symbolic links: if the file is a symlink
(which is seen from its i_mode field), and the length
of the pathname contained in the symlink is less than 60 bytes,
then the actual file contents is stored in the i_block[]
array, and the fact that this happened is visible from the fact
that i_blocks is zero.
As an aside: how large are files in reality? That is of great
interest to a filesystem designer. Things of course depend
strongly on the type of use, but let me make the statistics
on one of my machines.
I see here 27635 empty files. The most common size is 12 bits:
2048-4095 bytes. Clearly, in this filesystem the majority
of the files only need direct blocks. The fact that many files
are small also means that a lot of space is wasted by going to
a larger block size.
Other people will have a different distribution. Google
developed
their own filesystem GFS,
a large scale distributed fault-tolerant file system, designed
for an environment where one has "a few million files, each typically
100 MB or larger in size. Multi-GB files are the common case".
Reserved inodes
Inode 1 is reserved for a list of bad blocks on the device.
The root directory has inode number 2. This number must be fixed
in advance, since the mount() system call must be able
to find the root directory.
A few other inode numbers have a special meaning. Inode 11 is the
first one for ordinary use.
Directories
Files have pathnames, paths from the root / of the tree
to the file. The last element of the path is the file name.
Directories are files that give the correspondence between
file names and inodes. For the filesystem examined above:
Max level: 18
118355 directories
2176875 regular files
24407 other
A directory entry
struct ext2_dir_entry {
unsigned long inode; /* Inode number */
unsigned short rec_len; /* Directory entry length */
unsigned short name_len; /* Name length */
char name[up to 255]; /* File name */
};
does not have a fixed length. It gives the inode number
and the name. There are two lengths: the length of the name,
and after how many bytes the next directory entry starts.
These may differ - on the one hand because entries are aligned
to start at an address that is a multiple of 4. On the other
hand, the presence of a rec_len field allows efficient
file deletion: it is not necessary to shift all names in a directory
when a file is deleted; instead only the rec_len of
the preceding entry is adapted,
so that a directory search automatically skips over deleted entries.
QuestionAnd what if the entry was the first in the directory?
Read the answer infs/ext2/namei.c.
While names in a symlink are NUL-terminated, names in a directory
entry are not.
These days the directory struct is slightly different:
Since name_len cannot be larger than 255, a single byte
suffices, and the other byte, that used to be zero, is now
a file type: unknown (0), regular (1), directory (2),
character special device (3), block special device (4),
fifo (5), socket (6), symlink (7).
Some applications are sped up considerably by the presence
of this file type, since they now can walk a tree without doing
a stat() call on every file encountered.
Limits and efficiency
The macro EXT2_LINK_MAX, defined in ext2_fs.h
to the value 32000, makes sure that a directory cannot contain
more than 32000 subdirectories. That sometimes causes problems.
(I ran into this when trying to extract the about 60000 different
files from a collection of about 150000 similar files. Comparing
pairwise would take too long, so I decided to move each file to a
directory that had its md5sum as name. Now files in the same
directory would be almost certainly identical, and a few diffs should
remove the duplicates. The script failed after creating 31998
subdirectories.)
Something else is that ext2 does linear searches in its directories,
and things get really slow with large directories. Timing on some
machine here: create 10000 files in an empty directory: 98 sec;
create 10000 files more: 142 sec; create 10000 files more: 191 sec;
create 10000 files more: 242 sec. Clear quadratic behaviour.
This means that it is a bad idea to store many files in one
directory on an ext2 system. Try the same on a reiserfs system:
80 sec, 81 sec, 81 sec, 80 sec. No increase in running time.
Fragments
Fragments have not been implemented.
Attributes
Files on an ext2 filesystem can have various attributes.
There are
A
Atime
Linux 2.0
EXT2_NOATIME_FL
Don't update the atime field upon access.
S
Sync
Linux 1.0
EXT2_SYNC_FL
Perform synchronous writes - do not buffer.
D
Dirsync
Linux 2.6
EXT2_DIRSYNC_FL
If this is a directory: sync.
a
Append Only
Linux 1.2
EXT2_APPEND_FL
Only allow opening of this file for appending.For directories: disallow file deletion.
i
Immutable
Linux 1.2
EXT2_IMMUTABLE_FL
Disallow all changes to this file (data and inode).
j
Journalling
none
EXT2_JOURNAL_DATA_FL
(ext3 only) Upon a write, first write to the journal.
d
No Dump
Linux 1.2
EXT2_NODUMP_FL
The dump(8) program should ignore this file.
c
Compress
none
EXT2_COMPR_FL
Transparently compress this file upon write, uncompress upon read.
s
Secure Deletion
Linux 1.0-1.2 only
EXT2_SECRM
When this file is deleted, zero its data blocks.
u
Undelete
none
EXT2_UNRM_FL
When this file is deleted, preserve its data blocks,so that later undeletion is possible.
T
Topdir
Linux 2.6
EXT2_TOPDIR_FL
Consider this directory a top directory for the Orlov allocator.
Attributes can be viewed with lsattr and changed using
chattr.
'A' makes the system a bit faster since it saves some disk I/O.
'a' and 'i' are useful as a defense against hackers, even when they got root.
(These bits are read and set using the EXT2_IOC_GETFLAGS and
EXT2_IOC_SETFLAGS ioctls.)
Before Linux 2.1 there was a securelevel variable,
so that the 'a' and 'i' bits could not be changed by root
when it was larger than zero. Moreover, this variable could
never be decreased, other than by rebooting. Or at least, that was
the idea. However, with memory access one can do anything:
# cat /proc/sys/kernel/securelevel
1
# cat /proc/ksyms | grep securelevel
001a8f64 securelevel
# echo "ibase=16; 001A8F64" | bc
1740644
# dd if=/dev/zero of=/dev/kmem seek=1740644 bs=1 count=1
1+0 records in
1+0 records out
# cat /proc/sys/kernel/securelevel
0
#
Nowadays there is the capability system, see lcap(8), if you have
that installed.
Using
# lcap CAP_LINUX_IMMUTABLE
# lcap CAP_SYS_RAWIO
one disallows root to change the 'a' and 'i' bits,
and disallows root to write to the raw disk or raw memory.
Without this last restriction, root can do anything, since
it can patch the running kernel code.
More
The above mostly describes an early version of ext2, and there
are many details that were skipped. But this should suffice
for our purposes.
A crash caused by power failure or hardware failure or software bug
may leave the filesystem in an inconsistent state. The traditional
solution is the use of the utilities icheck, dcheck,
ncheck, clri. However, with several hundred thousand
files and a several GB filesystem checking the filesystem for consistency
may take a long time, more than one is prepared to wait.
A journaling filesystem has a journal (or log)
that records all transactions before they are actually done on the filesystem.
After a crash one finds in the journal what data was being modified
at the moment of the crash, and bringing the filesystem in a consistent
state is now very fast.
(If the crash happens during a write to the journal, we notice and
need not do anything: the filesystem is OK and the journal can be erased.
If the crash happens during a write to the filesystem, we replay
the transactions listed in the journal.)
Of course there is a price: the amount of I/O is doubled.
In cases where data integrity is less important but filesystem integrity
is essential, one only journals metadata (inode and directory contents,
not regular file contents).
There is a different price as well: the old check gave an absolute guarantee
that after the, say, e2fsck the filesystem was clean. The check
of a journaling filesystem only gives a conditional guarantee:
if the power failure or hardware failure or software bug
that caused the crash only affected the disk blocks currently being
written to according to the journal, then all is well.
Especially in the case of kernel bugs this assumption may be wrong.
And then a third price: code complexity.
Linux Journaling Filesystems
Currently, Linux supports four journaling filesystem types:
ext3, jfs, reiserfs, xfs. Several other log-structured filesystems are
under development.
(Ext3 is a journaling version of ext2, written by Stephen Tweedie.
JFS is from
IBM.
Reiserfs is from Hans Reiser's
Namesys.
XFS is from
SGI,
and was ported from IRIX to Linux.)
Each has its strengths and weaknesses, but reiserfs seems the most
popular. It is the default filesystem type used by SuSE
(who employ reiserfs developer Chris Mason).
RedHat (employs Stephen Tweedie and) uses ext3.
Linux has a Journaling Block Device layer intended to handle the journaling
for all journaling filesystem types. (See fs/jbd.) However,
it is used by ext3 only.
NFS is a network filesystem. (It is the Network File System.)
NFS v2 was released in 1985 by Sun.
It allows you to mount filesystems of one computer
on the file hierarchy of another computer.
Other network filesystem types are smb (Samba, used for file-sharing
with Windows machines), ncp (that provides access to Netware server
volumes and print queues), Coda and the Andrew filesystem.
Setup
Let us first actually use it, and then look at the theory.
On a modern distribution one just clicks "start NFS".
Let us go the old-fashioned way and do the setup by hand.
Ingredients: two computers with ethernet connection.
Make sure they see each other (ping works).
Make sure both machines are running portmap (on each machine
rpcinfo -p shows that portmap is running locally
and rpcinfo -p othermachine shows that portmap is running
remotely). If there are problems, check /etc/hosts.allow,
/etc/hosts.deny and the firewall rules.
Is the intended server running NFS?
# rpcinfo -p knuth
program vers proto port
100000 2 tcp 111 portmapper
100000 2 udp 111 portmapper
#
Hmm. It isn't. Then let us first setup and start NFS on the server.
We need to tell what is exported and to whom:
knuth# cat /etc/exports
/ 192.168.1.12(ro)
This says: Export /, that is, everything on the filesystem
rooted at /. Export it to 192.168.1.12, read-only.
Several daemons (especially tcpd) use the files
/etc/hosts.allow and /etc/hosts.deny
(first checking the first to see whether access is allowed,
then checking the second to see whether access is denied,
finally allowing access). Just to be sure, add
(Of course, once all is well one wants such commands in one of the
startup scripts, but as said, we do things here by hand.)
Check that all is well and mount the remote filesystem:
A portmapper may not be absolutely required - old versions of mount
know that the port should be 635 - but in most setups both local
and remote machine must have one.
There are other parts to NFS, e.g. the locking daemon.
What is exported is (part of) a filesystem on the server:
the exported tree does not cross mount points. Thus, in the
above example, if the server has the proc filesystem mounted
at /proc, the client will see an empty directory there.
On some systems the file /etc/exports is not used directly.
Instead, a file like /var/lib/nfs/xtab is used, and a
utility exportfs(8) is used to initialize and maintain it.
Now it is this utility that reads /etc/exports.
The most important property of NFS v2/v3 is that it is
stateless. The server does not keep state for the client.
Each request is self-contained. After a timeout, the request is repeated.
As a consequence, the system is robust in the face of server or
client crashes. If the client crashes the server never notices.
If the server crashes the client keeps repeating the request until
the server is up and running again and answers the request.
(This is the default, also called "hard" mounting. "Soft" mounting
is when the client gives up after a while and returns an error to
the user. "Spongy" mounting is hard for data transfers and soft for
status requests: stat, lookup, fsstat, readlink, and readdir.)
Thus, it is expected that retransmissions of requests may occur.
And since the server is stateless, it probably has not remembered
what requests were served earlier. It follows that one would like
to have idempotent requests, where it does not matter whether we
do them once or twice. Fortunately, most requests (read, write, chmod)
are naturally idempotent. An example of a non-idempotent request is
delete. A repetition would get an error return.
Due to the fact that NFS is stateless, it cannot quite reproduce
Unix semantics.
For example, the old Unix trick: create a temporary file, and delete it
immediately, retaining an open file descriptor, doesn't work.
The open descriptor lives on the client, and the server doesn't
know anything about it. Consequently the file would be removed,
data and everything.
As a partial workaround, the client, who knows that the file is open,
does not transmit the delete command to the server, but sends a
"silly rename" command instead, renaming the file to some unlikely
name that hopefully won't conflict with anything else, like
.nfs7200205400000001, and waits until the file has been
closed before actually removing this file.
This helps, but is less than perfect. It does not protect against
other clients that remove the file. If the client crashes, garbage
is left on the server.
Somewhat similarly, protection is handled a bit differently.
Under Unix, the protection is checked when the file is opened,
and once a file has been opened successfully, a subsequent chmod
has no influence. The NFS server does not have the concept of open file
and checks permissions for each read or write.
As a partial workaround, the NFS server always allows the owner
of a file read and write permission. (He could have given himself
permission anyway.) Approximate Unix semantics is preserved by the client
who can return "access denied" at open time.
A problem on larger networks is that read and write atomicity is lost.
On a local machine "simultaneous" reads and writes to a file are
serialized, and appear as if done in a well-defined order.
Over the network, a read or write request can span many packets,
and clients can see a partly old partly new situation.
Thus, locking is important. But of course locking cannot work
in a stateless setup. NFS comes with lockd (and statd).
It supplies lockf-style advisory locking.
NFS v3
(
RFC 1813)
was released in 1993. It contains 64-bit extensions,
and efficiency improvements. Only a small step from NFS v2.
NFS v4
(
RFC 3010)
became a proposed standard in 2000.
It is stateful, allows strong security, has file locking, uses UTF8.
Rather different from earlier NFS.
The protocol
XDR
One part of the protocol is the data representation.
If the communication channel is a byte stream, and the transmitted
data contains 32-bit integers, then an agreement is required in
which order one transmits the four bytes making up an integer.
And similar questions occur for other data types.
Sun defined the Extended Data Representation (XDR) that specifies
the representation of the transmitted data. For example, 32-bit
integers are transmitted with high-order byte first.
All objects and fields of structures are NUL-padded to make their length
a multiple of 4. Strings are represented by an integer giving the length
followed by the bytes of the string. More generally, variable-sized data
is preceded by an integer giving the length.
For more details, see
RFC 1014.
RPC
Communication is done via Remote Procedure Calls (RPCs).
Usually these are sent via (unreliable) UDP, and retransmitted
after a timeout. One can also use NFS over TCP.
RPC uses XDR. As a consequence, all small integers
take four bytes. Some detail of the protocol is given below.
NFS
NFS uses RPC.
All procedures are synchronous: when the (successful) reply is received,
the client knows that the operation has been done.
(This makes NFS slow: writes have to be committed to stable storage
immediately. NFS v3 introduces caching and the COMMIT request
to make things more efficient.)
The NFS requests:
0
NFSPROC_NULL
Do nothing
1
NFSPROC_GETATTR
Get File Attributes
2
NFSPROC_SETATTR
Set File Attributes
3
NFSPROC_ROOT
Get Filesystem Root
4
NFSPROC_LOOKUP
Look Up File Name
5
NFSPROC_READLINK
Read From Symbolic Link
6
NFSPROC_READ
Read From File
7
NFSPROC_WRITECACHE
Write to Cache
8
NFSPROC_WRITE
Write to File
9
NFSPROC_CREATE
Create File
10
NFSPROC_REMOVE
Remove File
11
NFSPROC_RENAME
Rename File
12
NFSPROC_LINK
Create Link to File
13
NFSPROC_SYMLINK
Create Symbolic Link
14
NFSPROC_MKDIR
Create Directory
15
NFSPROC_RMDIR
Remove Directory
16
NFSPROC_READDIR
Read From Directory
17
NFSPROC_STATFS
Get Filesystem Attributes
Packets on the wire
On the wire, we find ethernet packets. Unpacking these,
we find IP packets inside. The IP packets contain UDP packets.
The UDP packets contain RPC packets. It is the RPC (remote
procedure call) mechanism that implements NFS.
Ethernet
Just for fun, let us look at an actual packet on the wire: 170 bytes.
An 8-byte preamble (consisting of 62 alternating bits 1 and 0
followed by two bits 1) used for synchronization (not shown here),
The 6-byte destination MAC [Medium Access Control] address
(here 00:10:a4:f1:3c:d7),
The 6-byte source MAC address (here 00:e0:4c:39:1b:c2),
A 2-byte frame type (here 08 00, indicating an IP datagram),
The actual data,
A 4-byte CRC (not shown here).
The specification requires the total length (including CRC, excluding
preamble) to be at least 64 and at most 1518 bytes long.
For the data that means that it must have length in 46..1500.
Frames that are too short ("runts"), or too long ("jabbers"),
or have a non-integral number of bytes,
or have an incorrect checksum, are discarded.
IEEE 802.3 uses a 2-byte length field instead of the type field.
IP
After peeling off this outer MAC layer containing the ethernet transport
information, 156 data bytes are left, and we know that we have an IP datagram.
IP is described in
RFC 791.
An IP datagram consists of a header followed by data.
The header consists of:
A byte giving a 4-bit version
(here 4: IPv4) and a 4-bit header length measured in 32-bit words
(here 5). Thus, the header is
A byte giving a service type (here 0: nothing special),
Two bytes giving the total length of the datagram
(here 00 9c, that is, 156),
Two bytes identification, 3 bits flags,
13 bits fragment offset (measured in multiples of 8 bytes),
all related to fragmentation, but this packet was not fragmented -
indeed, the flag set is the DF [Don't Fragment] bit,
A byte giving the TTL (time to live, here hex 40, that is, 64),
A byte giving the protocol (here hex 11, that is, UDP),
Two bytes giving a header checksum,
The source IP address (here c0 a8 01 0c, that is, 192.168.1.12),
The destination IP address (here c0 a8 01 08, that is, 192.168.1.8)
Optional IP options, and padding to make the header length a multiple of 4.
UDP
After peeling off the IP layer containing the internet transport information,
136 data bytes are left, and we know we have a UDP datagram:
UDP (User Datagram Protocol) is described in
RFC 768.
A UDP datagram consists of
a 2-byte source port (here 03 20, that is, 800),
a 2-byte destination port (here 08 01, that is, 2049),
a 2-byte length (here 00 88, that is 136),
a 2-byte checksum, and data. So we have 128 bytes of data.
On port 2049 the NFS server is running. It gets these 128 bytes,
and sees a Remote Procedure Call.
RPC
RPC is described in RFCs
1050,
1057,
1831.
An RPC request consists of
A 4-byte xid, the transmission ID. The client
generates a unique xid for each request, and the server reply
contains this same xid. (Here xid is e2 c0 87 0b.)
The client may, but need not, use the same xid upon
retransmission after a timeout. The server may, but need not,
discard requests with an xid it already has replied to.
A 4-byte direction (0: call, 1: reply). (Here we have a call.)
In the case of a call, the fields following xid and direction are:
A 4-byte RPC version. (Here we have RPC v2.)
A 4-byte program number and a 4-byte version
of the program or service called. (Here we have 00 01 86 a3,
that is, 100003, the NFS protocol, and 00 00 00 02, that is NFS v2.)
A 4-byte procedure call number. (Here we have
00 00 00 04, procedure 4 of the NFS specification, that is,
NFSPROC_LOOKUP.)
Authentication info (see below).
Verification info (see below).
Procedure-specific parameters.
In the case of a reply, the field following xid and direction is:
A 4-byte status (0: accepted, 1: denied)
In the case of a reply with status "accepted", the fields following are:
Verification info (see below), that may allow the client
to verify that this reply is really from the server.
A 4-byte result status (0: call executed successfully,
1: program unavailable, 2: version unavailable, 3: procedure unavailable,
4: bad parameters).
In case of a successfully executed call, the results are here.
In case of failure because of unavailable version, two 4-byte
fields giving the lowest and highest versions supported. In case of
other failures, no further data.
In the case of a reply with status "denied", the fields following are:
A 4-byte rejection reason (0: RPC version not 2,
1: authentication error).
In case of RPC version mismatch, two 4-byte fields giving
the lowest and highest versions supported.
In case of an authentication error a 4-byte reason (1: bad credentials,
2: client must begin new session, 3: bad verifier,
4: verifier expired or replayed, 5: rejected for security reasons).
The three occurrences of "authentication/verification info" above
each are structured as follows: first a 4-byte field giving a type
(0: AUTH_NULL, 1: AUTH_UNIX, 2: AUTH_SHORT, 3: AUTH_DES, ...),
then the length of the authentication data, then the authentication data.
In the case of the packet we are looking at the authentication info is
00 00 00 01 (AUTH_UNIX) 00 00 00 30 (48 bytes)
00 04 99 cd (stamp)
00 00 00 05 (length of machine name: 5 bytes)
6d 65 74 74 65 00 00 00 ("mette" with three bytes padding)
00 00 03 e8 (user id 1000) 00 00 00 64 (group id 100)
00 00 00 05 (5 auxiliary group ids)
00 00 00 64 00 00 00 0e 00 00 00 10 00 00 00 11 00 00 00 21
(100, 14, 16, 17, 33).
The verification info is
00 00 00 00 00 00 00 00 (AUTH_NULL, length 0).
NFS
After peeling off the RPC parts of the packet we are left with
the knowledge: this is for NFS, procedure NFSPROC_LOOKUP, and the
parameters for this procedure are
Examining the NFS specification, we see that a lookup has
as parameter a struct diropargs, with two fields,
fhandle dir and filename name.
A fhandle is an opaque structure of size FHSIZE,
where FHSIZE=32, created by the server to represent a file
(given a lookup from the client). A filename is a
string of length at most MAXNAMLEN=255. Here we see length 3,
and string "aeb".
Altogether, this packet asked for a lookup of the name "aeb"
in a directory with specified fhandle.
ExerciseInterpret this packet. Verify that this is a reply,
and that thexidof the reply equals thexidof the request. By some coincidence request and reply have the same
length.
The result of a lookup is a status (here NFS_OK=0),
in case NFS_OK followed by the servers fhandle for the file
and a fattr giving the file attributes. It is defined by
struct fattr {
ftype type;
unsigned int mode;
unsigned int nlink;
unsigned int uid;
unsigned int gid;
unsigned int size;
unsigned int blocksize;
unsigned int rdev;
unsigned int blocks;
unsigned int fsid;
unsigned int fileid;
timeval atime;
timeval mtime;
timeval ctime;
};
Here the file type is 2 (directory), the mode is hex 000041ed,
that is octal 40755, a directory with permissions rwxr-xr-x,
etc.
Security
NFS is very insecure and can be used only in non-hostile environments.
The AUTH_UNIX authentication uses user id and group id.
This is inconvenient: both machines must use the same IDs,
and a security problem: someone who has root on his client laptop
can give himself any uid and gid desired, and can subsequently
access other people's files on the server.
Doing root stuff on the server may be more difficult.
Typically user id root on the client is mapped to
user id nobody on the server.
The proc filesystem is an example of a virtual filesystem.
It does not live on disk. Instead the contents are generated
dynamically when its files are read.
Sometimes users are worried that space on their disk is wasted by
some huge core file
but this only says something about the amount of memory of the machine.
Many of the files in the proc filesystem have unknown size,
since they first get a size when they are generated. Thus,
a ls -l will show size 0, while cat will
show nonempty contents. Some programs are confused by this.
% ls -l /proc/version
-r--r--r-- 1 root root 0 Sep 30 12:31 /proc/version
% cat /proc/version
Linux version 2.5.39 (aeb@mette) (gcc version 2.96) #14 Mon Sep 30 03:13:05 CEST 2002
The proc filesystem was designed to hold information about processes,
but in the course of time a lot of other cruft was added. Most files
are read-only, but some variables can be used to tune kernel behaviour
(using echo something > /proc/somefile).
An example
It is easy to add an entry to the proc tree.
Let us make /proc/arith/sum that keeps track of
the sum of all numbers echoed to this file.
/*
* sum-module.c
*/
#include <linux/module.h>
#include <linux/init.h>
#include <linux/proc_fs.h>
#include <asm/uaccess.h>
static unsigned long long sum;
static int show_sum(char *buffer, char **start, off_t offset, int length) {
int size;
size = sprintf(buffer, "%lld\n", sum);
*start = buffer + offset;
size -= offset;
return (size > length) ? length : (size > 0) ? size : 0;
}
/* Expect decimal number of at most 9 digits followed by '\n' */
static int add_to_sum(struct file *file, const char *buffer,
unsigned long count, void *data) {
unsigned long val = 0;
char buf[10];
char *endp;
if (count > sizeof(buf))
return -EINVAL;
if (copy_from_user(buf, buffer, count))
return -EFAULT;
val = simple_strtoul(buf, &endp, 10);
if (*endp != '\n')
return -EINVAL;
sum += val; /* mod 2^64 */
return count;
}
static int __init sum_init(void) {
struct proc_dir_entry *proc_arith;
struct proc_dir_entry *proc_arith_sum;
proc_arith = proc_mkdir("arith", 0);
if (!proc_arith) {
printk (KERN_ERR "cannot create /proc/arith\n");
return -ENOMEM;
}
proc_arith_sum = create_proc_info_entry("arith/sum", 0, 0, show_sum);
if (!proc_arith_sum) {
printk (KERN_ERR "cannot create /proc/arith/sum\n");
remove_proc_entry("arith", 0);
return -ENOMEM;
}
proc_arith_sum->write_proc = add_to_sum;
return 0;
}
static void __exit sum_exit(void) {
remove_proc_entry("arith/sum", 0);
remove_proc_entry("arith", 0);
}
module_init(sum_init);
module_exit(sum_exit);
MODULE_LICENSE("GPL");
seqfiles
In the old days routines generating a proc file would allocate a page
and write their output there. A read call would then copy the appropriate
part to user space. Typical code was something like
and clearly this works only when the entire content of a proc file
fits within a single page. There were other problems as well.
For example, when output is generated using sprintf(),
it is messy to protect against buffer overflow.
Since 2.5.1 (and 2.4.15) some infrastructure exists for producing
generated proc files that are larger than a single page. For an example
of use, see the
Fibonacci module.
The code
f = create_proc_entry("foo", mode, NULL);
if (f)
f->proc_fops = &proc_foo_operations;
will create a file /proc/foo with given mode
such that opening it yields a file that has proc_foo_operations
as struct file_operations. Typically one has something like
To make the proc file work, the foo module has to define the four
routines start(), stop(), next(), show().
Each time some amount of data is to be read from the proc file,
first start(); show() is done, then a number of times
next(); show(), as long as more items fit in the user-supplied
buffer, and finally stop().
The start routine can allocate memory, or get locks or down semaphores,
and the stop routine can free or unlock or up them again.
The values returned by start() and next() are cookies
fed to show(), and this latter routine generates the actual output
using the specially provided output routines seq_putc(),
seq_puts(), seq_printf().
The routines seq_open() etc. are defined in seq_file.c.
Here seq_open() initializes a struct seq_file and
attaches it to the private_data field of the file structure:
(Use a buffer buf of size size. It still contains
count unread bytes, starting from buf offset from.
We return a sequence of items, and index is the current
serial number. The private pointer can be used to point
at private data, if desired.)
As an example, look at /proc/mounts, defined in proc/base.c.
The open routine here is slightly more complicated, basically something like
static int mounts_open(struct inode *inode, struct file *file)
{
int ret = seq_open(file, &mounts_op);
if (!ret) {
struct seq_file *m = file->private_data;
m->private = proc_task(inode)->namespace;
}
}
and the start, next, stop, show routines live in namespace.c.
Let us write a baby filesystem, as an example of how the
Virtual File System works. It allows one to mount a block device
and then shows the partition table as a file hierarchy, with
partitions as files, and links in a chain of logical partitions
as directories.
(It helps to know how partition tables work. Very briefly:
Start at sector 0, the Master Boot Record.
Each partition sector contains 4 descriptors, that
either describe a partition, or point at the next
partition sector. The partitions described in the MBR
are called primary. The others are called logical.
The box containing all logical partitions is called the
extended partition.)
We see a disk with four partition sectors. There are four actual
partitions, and three links in the chain of logical partitions,
and a lot of empty slots.
Below
the code that does this.
I wrote it this evening under 2.5.52 - correctness not guaranteed.
Don't try it on a disk that is in use - obscure errors may result.
ExerciseChange in the code below the regular files into block device nodes
giving access to the partition described by the partition descriptor.
The Linux kernel implements the concept of Virtual File System
(VFS, originally Virtual Filesystem Switch), so that it is
(to a large degree) possible to separate actual "low-level"
filesystem code from the rest of the kernel.
The API of a filesystem is described below.
This API was designed with things closely related to the ext2
filesystem in mind. For very different filesystems, like NFS,
there are all kinds of problems.
Four main objects: superblock, dentries, inodes, files
The kernel keeps track of files using in-core inodes
("index nodes"), usually derived by the low-level filesystem
from on-disk inodes.
A file may have several names, and there is a layer of dentries
("directory entries") that represent pathnames, speeding up the
lookup operation.
Several processes may have the same file open for reading or writing,
and file structures contain the required information
such as the current file position.
Access to a filesystem starts by mounting it. This operation
takes a filesystem type (like ext2, vfat, iso9660, nfs) and a device
and produces the in-core superblock that contains the information
required for operations on the filesystem; a third ingredient,
the mount point, specifies what pathname refers to the root
of the filesystem.
Auxiliary objects
We have filesystem types, used to connect the name of
the filesystem to the routines for setting it up (at mount time)
or tearing it down (at umount time).
A struct vfsmount represents a subtree in the big file
hierarchy - basically a pair (device, mountpoint).
A struct nameidata represents the result of a lookup.
A struct address_space gives the mapping between
the blocks in a file and blocks on disk. It is needed for I/O.
Various objects play a role here. There are file systems,
organized collections of files, usually on some disk partition.
And there are filesystem types, abstract descriptions
of the way data is organized in a filesystem of that type,
like FAT16 or ext2. And there is code, perhaps a module,
that implements the handling of file systems of a given type.
Sometimes this code is called a low-level filesystem,
low-level since it sits below the VFS just like low-level SCSI drivers
sit below the higher SCSI layers.
A module implementing a filesystem type must announce its presence
so that it can be used. Its task is (i) to have a name,
(ii) to know how it is mounted, (iii) to know how to lookup files,
(iv) to know how to find (read, write) file contents.
This announcing is done using the call register_filesystem(),
either at kernel initialization time or when the module is inserted.
There is a single argument, a struct that contains the name of the
filesystem type (so that the kernel knows when to invoke it) and a
routine that can produce a superblock.
The struct is of type struct file_system_type.
Here the 2.2.17 version:
The call register_filesystem() hangs this struct in the chain
with head file_systems, and
unregister_filesystem() removes it again.
Accesses to this chain are protected by the spinlock
file_systems_lock. There are no other writers.
The main reader is of course the mount() system call
(via get_fs_type()).
Other readers are get_filesystem_list() used
for /proc/filesystems, and the
sysfs
system call.
(In 2.4 there was no kill_sb(), and the role of
get_sb() was taken by read_super().
The final parameter of get_sb() and the
lock_class_key fields are present since 2.6.18.)
Let us look at the fields of the struct file_system_type.
name
Here the filesystem type gives its name ("tue"), so that the kernel
can find it when someone does mount -t tue /dev/foo /dir.
(The name is the third parameter of the mount system call.)
It must be non-NULL. The name string lives in module space.
Access must be protected either by a reference to the module,
or by the file_systems_lock.
get_sb
At mount time the kernel calls the fstype->get_sb() routine
that initializes things and sets up a superblock.
It must be non-NULL. Typically this is a 1-line routine that calls
one of get_sb_bdev, get_sb_single, get_sb_nodev,
get_sb_pseudo.
kill_sb
At umount time the kernel calls the fstype->kill_sb() routine
to clean up. It must be non-NULL. Typically one of
kill_block_super, kill_anon_super,
kill_litter_super.
fs_flags
The fs_flags field of a struct file_system_type
is a bitmap, an OR of several possible flags with mostly obscure uses only.
The flags are defined in fs.h.
This field was introduced in 2.1.43. The number of flags, are their
meanings, varies. In 2.6.19 there are the four flags
FS_REQUIRES_DEV, FS_BINARY_MOUNTDATA,
FS_REVAL_DOT, FS_RENAME_DOES_D_MOVE.
FS_REQUIRES_DEV
The FS_REQUIRES_DEV flag (since 2.1.43) says that this is not
a virtual filesystem - an actual underlying block device is required.
It is used in only two places: when /proc/filesystems
is generated, its absence causes the filesystem type name to be prefixed
by "nodev". And in fs/nfsd/export.c this flag is tested
in the process of determining whether the filesystem can be exported
via NFS. Earlier there were more uses.
FS_BINARY_MOUNTDATA
The FS_BINARY_MOUNTDATA flag (since 2.6.5) is set to tell
the selinux code that the mount data is binary, and cannot be
handled by the standard option parser. (This flag is set for
afs, coda, nfs, smbfs.)
FS_REVAL_DOT
The FS_REVAL_DOT flag (since 2.6.0test4) is set to tell
the VFS code (in namei.c) to revalidate the paths "/", ".", ".."
since they might have gone stale. (This flag is set for NFS.)
FS_RENAME_DOES_D_MOVE
The FS_RENAME_DOES_D_MOVE flag (since 2.6.19) says that
the low-level filesystem will handle d_move() during
a rename(). Earlier (2.4.0test6-2.6.19) this was called
FS_ODD_RENAME and was used for NFS only, but
now this is also useful for ocfs2.
See also the discussion of
silly rename.
FS_NOMOUNT (gone)
The FS_NOMOUNT flag (2.3.99pre7-2.5.22) says that this filesystem
must never be mounted from userland, but is used only kernel-internally.
This was used, for example, for pipefs, the implementation of Unix pipes
using a kernel-internal filesystem (see fs/pipe.c).
Even though the flag has disappeared, the concept remains,
and is now represented by the MS_NOUSER flag.
FS_LITTER (gone)
The FS_LITTER flag (2.4.0test3-2.5.7) says that after umount
a d_genocide() is needed. This will remove one reference
from all dentries in that tree, probably killing all of them, which is
necessary in case at creation time the dentries already got reference
count 1. (This is typically done for an in-core filesystem where dentries
cannot be recreated when needed.) This flag disappeared in Linux 2.5.7
when the explicit kill_super method kill_litter_super
was introduced.
FS_SINGLE (gone)
The FS_SINGLE flag (2.3.99pre7-2.5.4) says that there is
only a single superblock for this filesystem type, so that
only a single instance of this filesystem may exist,
possibly mounted in several places.
FS_IBASKET and FS_NO_DCACHE and FS_NO_PRELIM (gone)
The FS_IBASKET was defined in 2.1.43 but never used, and
the definition disappeared in 2.3.99pre4.
The FS_NO_DCACHE and FS_NO_PRELIM flags were introduced
in 2.1.43, but were a mistake and disappeared again in 2.1.44. However,
the definitions survived until Linux 2.5.22.
For the purposes of these flags, see the comment in 2.1.43:dcache.c.
owner
The owner field of a struct file_system_type
points at the module that owns this struct. When doing things that
might sleep, we must make sure that the module is not unloaded
while we are using its data, and do this with
try_inc_mod_count(owner). If this fails then the module
was just unloaded. If it succeeds we have incremented a reference
count so that the module will not go away before we are done.
This field is NULL for filesystems compiled into the kernel.
Example of the use of owner - sysfs
There exists a strange SYSV system call sysfs
that will return (i) a sequence number given a filesystem type,
and (ii) a filesystem type given a sequence number, and
(iii) the total number of filesystem types registered now.
This call is not supported by libc or glibc.
These sequence numbers are rather meaningless since they may change
any moment. But this means that one can get a snapshot of the
list of filesystem types without looking at /proc/filesystems.
For example, the program
#include <stdio.h>
#include <linux/unistd.h>
/* define the 3-arg version of sysfs() */
static _syscall3(int,sysfs,int,option,unsigned int,fsindex,char *,buf);
/* define the 1-arg version of sysfs() */
static int sysfs1(int i) {
return sysfs(i,0,NULL);
}
main(){
int i, tot;
char buf[100]; /* how long is a filesystem type name?? */
tot = sysfs1(3);
if (tot == -1) {
perror("sysfs(3)");
exit(1);
}
for (i=0; i<tot; i++) {
if (sysfs(2, i, buf)) {
perror("sysfs(2)");
exit(1);
}
printf("%2d: %s\n", i, buf);
}
return 0;
}
The kernel code for copying the names to user space is instructive:
static int fs_name(unsigned int index, char * buf)
{
struct file_system_type * tmp;
int len, res;
read_lock(&file_systems_lock);
for (tmp = file_systems; tmp; tmp = tmp->next, index--)
if (index <= 0 && try_inc_mod_count(tmp->owner))
break;
read_unlock(&file_systems_lock);
if (!tmp)
return -EINVAL;
/* OK, we got the reference, so we can safely block */
len = strlen(tmp->name) + 1;
res = copy_to_user(buf, tmp->name, len) ? -EFAULT : 0;
put_filesystem(tmp);
return res;
}
In order to walk safely along a linked list we need the read lock.
The routines that change links (like register_filesystem)
need a write lock. Once the filesystem name with the desired
index is found we cannot just copy this name to user space.
Maybe the page we want to copy to was swapped out, and getting it
back in core takes some time, and maybe the module is unloaded just
at that point, and then, when we want to read the name we reference
memory that is no longer present. The routine try_inc_mod_count()
first gets the module unload lock, then looks whether the module still
is present; if so it increases the module's refcount and returns 1
(after releasing the unload lock), otherwise it returns 0.
After a successful return of try_inc_mod_count() we own
a reference to the module, so that it cannot disappear while we
are doing copy_to_user(). The put_filesystem()
decreases the module's refcount again.
So this is how the owner field is used: it tells which
module must be pinned when we do something with this struct.
A module stays as long as its refcount is positive, but can
disappear any moment when the refcount becomes zero.
next
In fs/filesystems.c there is a global variable
static struct file_system_type *file_systems;
that is the head of the list of known filesystem types.
A register_filesystem adds the filesystem to the linked list,
an unregister_filesystem removes it again.
The field next is the link in this simply linked list.
It must be NULL when register_filesystem is called,
and is reset to NULL by unregister_filesystem.
The list is protected by the file_systems_lock.
fs_supers
The fs_supers field of a struct file_system_type
is the head of a list of all superblocks of this type.
In each superblock the corresponding link is called s_instances.
This list is protected by the spinlock sb_lock.
This list is used in sget() for filesystems like NFS
where we get a filehandle and must check each superblock of
the given type whether it is the right one.
s_lock_key, s_umount_key
These are fields used when CONFIG_LOCKDEP is defined, and take
no space otherwise. Used for lock validation.
The mount system call attaches a filesystem to the big file
hierarchy at some indicated point. Ingredients needed:
(i) a device that carries the filesystem (disk, partition,
floppy, CDROM, SmartMedia card, ...), (ii) a directory
where the filesystem on that device must be attached,
(iii) a filesystem type.
In many cases it is possible to guess (iii) given the bits
on the device, but heuristics fail in rare cases. Moreover,
sometimes there is no difference on the device, as for example
in the case where a FAT filesystem without long filenames
must be mounted. Is it msdos? or vfat? That information is only
in the user's head. If it must be used later in an environment
that cannot handle long filenames it should be mounted as msdos;
if files with long names are going to be copied to it, as vfat.
The kernel does not guess (except perhaps at boot time, when the
root device has to be found), and requires the three ingredients.
In fact the mount system call has five parameters:
there are also mount flags (like "read-only") and options, like
for ext2 the choice between errors=continue and
errors=remount-ro and errors=panic.
The code for sys_mount() is found in fs/namespace.c
and fs/super.c. The connection with the filesystem type name
is made in do_kern_mount():
The superblock gives global information on a filesystem:
the device on which it lives, its block size,
its type, the dentry of the root of the filesystem,
the methods it has, etc., etc.
This is enough to get started:
the dentry of the root directory tells us the inode of this root directory
(and in particular its i_ino),
and sb->s_op->read_inode(inode) will read this inode from disk.
Now inode->i_op->lookup() allows us to find names in the
root directory, etc.
Each superblock is on six lists, with links through the fields
s_list, s_dirty, s_io, s_anon,
s_files, s_instances, respectively.
The super_blocks list
All superblocks are collected in a list super_blocks
with links in the fields s_list.
This list is protected by the spinlock sb_lock.
The main use is in super.c:get_super() or user_get_super()
to find the superblock for a given block device.
(Both routines are identical, except that one takes a bdev,
the other a dev_t.)
This list is also used various places where all superblocks must be sync'ed
or all dirty inodes must be written out.
The fs_supers list
All superblocks of a given type are collected in a list headed by the
fs_supers field of the struct filesystem_type,
with links in the fields s_instances.
Also this list is protected by the spinlock sb_lock.
See
above.
The file list
All open files belonging to a given superblock are chained in
a list headed by the s_files field of the superblock,
with links in the fields f_list of the files.
These lists are protected by the spinlock files_lock.
This list is used for example in fs_may_remount_ro()
to check that there are no files currently open for writing.
See also
below.
The list of anonymous dentries
Normally, all dentries are connected to root. However, when
NFS filehandles are used this need not be the case.
Dentries that are roots of subtrees potentially unconnected
to root are chained in a list headed by the s_anon
field of the superblock, with links in the fields d_hash.
These lists are protected by the spinlock dcache_lock.
They are grown in dcache.c:d_alloc_anon() and shrunk
in super.c:generic_shutdown_super().
See the discussion in Documentation/filesystems/Exporting.
The inode lists s_dirty, s_io
Lists of inodes to be written out.
These lists are headed at the s_dirty (resp. s_io)
field of the superblock, with links in the fields i_list.
These lists are protected by the spinlock inode_lock.
See fs/fs-writeback.c.
An (in-core) inode contains the metadata of a file:
its serial number, its protection (mode), its owner, its size,
the dates of last access, creation and last modification, etc.
It also points to the superblock of the filesystem the file is in,
the methods for this file, and the dentries (names) for this file.
to store the filesystemtype specific stuff.
One could go from inode to e.g. struct ext3_inode_info
via inode->u.ext3_i.
This setup was rather dissatisfactory, since it meant that
a core data structure had to know about all possible
filesystem types (even possible out-of-tree ones)
and reserve enough room for the largest one among the
struct foofs_inode_info. It also wasted memory.
In Linux 2.5.3 this system was changed, and instead of
a big struct inode having a filesystemtype dependent part,
we now have big filesystemtype dependent inodes, with a VFS part.
Thus, struct ext3_inode_info has as its last field
struct inode vfs_inode;, and given the VFS inode inode
one finds the ext3 information via EXT3_I(inode), defined as
container_of(inode, struct ext3_inode_info, vfs_inode).
The methods of an inode are given in the struct inode_operations.
Each inode is on four lists, with links through the fields
i_hash, i_list, i_dentry,
i_devices.
The dentry list
All dentries belonging to this inode (names for this file)
are collected in a list headed by the inode field i_dentry
with links in the dentry fields d_alias.
This list is protected by the spinlock dcache_lock.
The hash list
All inodes live in a hash table, with hash collision chains
through the field i_hash of the inode.
These lists are protected by the spinlock inode_lock.
The appropriate head is found by a hash function; it will be
an element of the inode_hashtable[] array when the
inode belongs to a superblock, or anon_hash_chain
if not.
i_list
Inodes are collected into lists that use the i_list
field as link field. The lists are protected by the spinlock
inode_lock. An inode is either unused, and then on
the chain with head inode_unused, or in use but not
dirty, and then on the chain with head inode_in_use,
or dirty, and then on one of the per-superblock lists with heads
s_dirty or s_io, see
above.
i_devices
Inodes belonging to a given block device are collected into
a list headed by the bd_inodes field of the block device,
with links in the inode i_devices fields.
The list is protected by the bdev_lock spinlock.
It is used to set the i_bdev field to NULL and to reset
i_mapping when the block device goes away.
The dentries encode the filesystem tree structure, the names
of the files. Thus, the main parts of a dentry are the inode
(if any) that belongs to it, the name (the final part of the pathname),
and the parent (the name of the containing directory).
There are also the superblocks, the methods, a list of subdirectories,
etc.
struct qstr {
const unsigned char *name;
unsigned int len;
unsigned int hash;
};
Each dentry is on five lists, with links through the fields
d_hash, d_lru, d_child, d_subdirs,
d_alias.
Naming flaw
Some of these names were badly chosen, and lead to confusion.
We should do a global replace changing d_subdirs into
d_children and d_child into d_sibling.
Value of a dentry
The pathname represented by a dentry, is the concatenation of
the name of its parent d_parent, a slash character,
and its own name d_name.
However, if the dentry is the root of a mounted filesystem
(i.e., if dentry->d_covers != dentry), then its pathname
is the pathname of the mount point d_covers.
Finally, the pathname of the root of the filesystem
(with dentry->d_parent == dentry) is "/",
and this is also its d_name.
The d_mounts and d_covers fields of a dentry
point back to the dentry itself, except that the d_covers field
of the dentry for the root of a mounted filesystem points back to
the dentry for the mount point, while the d_mounts field
of the dentry for the mount point points at the dentry for the root of a
mounted filesystem.
The d_parent field of a dentry points back to the
dentry for the directory in which it lives. It points back
to the dentry itself in case of the root of a filesystem.
A dentry is called negative if it does not have an
associated inode, i.e., if it is a name only.
We see that although a dentry represents a pathname, there
may be several dentries for the same pathname, namely when
overmounting has taken place. Such dentries have different inodes.
Of course the converse, an inode with several dentries, can also occur.
The above description, with d_mounts and d_covers,
was for 2.4. In 2.5 these fields have disappeared, and we only
have the integer d_mounted that indicates how many
filesystems have been mounted at that point. In case it is
nonzero (this is what d_mountpoint() tests), a hash
table lookup can find the actual mounted filesystem.
d_hash
Dentries are used to speed up the lookup operation.
A hash table dentry_hashtable is used, with an index
that is a hash of the name and the parent. The hash collision
chain has links through the dentry fields d_hash.
This chain is protected by the spinlock dcache_lock.
d_lru
All unused dentries are collected in a list dentry_unused
with links in the dentry fields d_lru.
This list is protected by the spinlock dcache_lock.
d_child, d_subdirs
All subdirectories of a given directory are collected in a list
headed by the dentry field d_subdirs with links
in the dentry fields d_child.
These lists are protected by the spinlock dcache_lock.
d_alias
All dentries belonging to the same inode are collected in a list
headed by the inode field i_dentry
with links in the dentry fields d_alias.
This list is protected by the spinlock dcache_lock.
File structures represent open files, that is, an inode together
with a current (reading/writing) offset. The offset can be set
by the lseek() system call. Note that instead of a
pointer to the inode we have a pointer to the dentry - that
means that the name used to open a file is known. In particular
system calls like getcwd() are possible.
Each file is in two lists, with links through the fields
f_list, f_ep_links.
f_list
The list with links through f_list was discussed
above. It is the list of all files
belonging to a given superblock. There is a second use:
the tty driver collects all files that are opened instances
of a tty in a list headed by tty->tty_files with
links through the file field f_list. Conversely,
these files point back at the tty via their field
private_data.
(This field private_data is also used elsewhere.
For example, the proc code uses it to attach a struct seq_file
to a file.)
The event poll list
All event poll items belonging to a given file are collected
in a list with head f_ep_links,
protected by the file field f_ep_lock.
(For event poll stuff, see epoll_ctl(2).)
A struct vfsmount describes a mount.
The definition lives in mount.h:
struct vfsmount {
struct list_head mnt_hash;
struct vfsmount *mnt_parent; /* fs we are mounted on */
struct dentry *mnt_mountpoint; /* dentry of mountpoint */
struct dentry *mnt_root; /* root of the mounted tree */
struct super_block *mnt_sb; /* pointer to superblock */
struct list_head mnt_mounts; /* list of children, anchored here */
struct list_head mnt_child; /* and going through their mnt_child */
atomic_t mnt_count;
int mnt_flags;
char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
struct list_head mnt_list;
};
Long ago (1.3.46) it was introduced as part of the quota code.
There was a linked list of struct vfsmounts that
contained a device number, device name, mount point name,
mount flags, superblock pointer, semaphore, file pointers
to quota files and time limits for how long an over-quota situation
would be allowed. Nowadays quota have independent bookkeeping,
and a struct vfsmount only describes a mount.
These stucts are allocated by alloc_vfsmnt() and
released by free_vfsmnt() in namespace.c.
mnt_hash
Vfsmounts live in a hash headed by mount_hashtable[].
The field mnt_hash is the link in the collision chain.
This list does not seem to be protected by a lock.
They are put into the hash by attach_mnt(), found there
by lookup_mnt(), and removed again by detach_mnt(),
all from namespace.c.
mnt_parent
Vfsmount for parent.
mnt_mountpoint
Dentry for the mountpoint. The pair (mnt_mountpoint, mnt_parent)
(returned by follow_up()) will be the dentry and vfsmount
for the parent.
Used e.g. in d_path to return the pathname of a dentry.
mnt_root
Dentry for the root of the mounted tree.
mnt_sb
Superblock of the mounted filesystem.
mnt_mounts, mnt_child
The field mnt_mounts of a struct vfsmount is the head of
a cyclic list of all submounts (mounts on top of some path
relative to the present mount). The remaining links of this cyclic
list are stored in the mnt_child fields of its submounting
vfsmounts. (And each of these points back at us with its
mnt_parent field.)
Used in autofs4/expire.c and namespace.c (and nowhere else).
mnt_count
Keep track of users of this structure.
Incremented by mntget, decremented by mntput.
Initially 1. It will be 2 for a mount that may be unmounted.
(Autofs also uses this to test whether a tree is busy.)
mnt_flags
The mount flags, like MNT_NODEV, MNT_NOEXEC, MNT_NOSUID.
Earlier also MS_RDONLY (that now is stored in sb->s_flags)
and MNT_VISIBLE (came in 2.4.0-test5, went in 2.4.5)
that told whether this entry should be visible in /proc/mounts.
mnt_devname
Name used in /proc/mounts.
mnt_list
There was a global cyclic list vfsmntlist
containing all mounts, used only to create the contents of
/proc/mounts. These days we have per-process namespaces,
and the global vfsmntlist has been replaced by
current->namespace->list. This list is ordered
by the order in which the mounts were done, so that one can do
the umounts in reverse order.
The field mnt_list contains the pointers for this cyclic list.
A struct fs_struct determines the interpretation
of pathnames referred to by a process (and also, somewhat
illogically, contains the umask). The typical reference
is current->fs. The definition lives in fs_struct.h:
Semantics of root and pwd are clear.
Remains to discuss altroot.
altroot
In order to support emulation of different operating systems
like BSD and SunOS and Solaris, a small wart has been added
to the walk_init_root code that finds the root directory
for a name lookup.
The altroot field of an fs_struct
is usually NULL. It is a function of the personality
and the current root, and the sys_personality
and sys_chroot system calls call set_fs_altroot().
The effect is determined at kernel compile time.
One can define __emul_prefix() in <asm/namei.h>
as some pathname, say "usr/gnemul/myOS/".
The default is NULL, but some architectures have a
definition depending on current->personality.
If this prefix is non-NULL, and the corresponding file is found,
then set_fs_altroot() will set the altroot
and altrootmnt fields of current->fs
to dentry and vfsmnt of that file.
A subsequent lookup of a pathname starting with '/' will now
first try to use the altroot. If that fails the usual root is used.
A struct nameidata represents the result of a lookup.
The definition lives in fs.h:
struct nameidata {
struct dentry *dentry;
struct vfsmount *mnt;
struct qstr last;
unsigned int flags;
int last_type;
};
The typical use is:
struct nameidata nd;
error = user_path_walk(filename, &nd);
if (!error)
path_release(&nd);
where path_release() does
dput(nd->dentry);
mntput(nd->mnt);
The core of the routines user_path_walk_link
and user_path_walk (which call __user_walk
without or with the LOOKUP_FOLLOW flag) is the
fragment
if (path_init(name, flags, nd))
error = path_walk(name, nd);
So the basic routines handling nameidata are path_init
and path_walk. The former finds the start of the walk,
the latter does the walking. (However, the former returns
0 in case it did the walking itself already.)
path_init
The routine path_init initialises the four fields
dentry, mnt, flags, last_type.
The flags field was given as an argument, and
dentry and mnt are initialised to those
of the current directory or those of the root directory
depending on whether name starts with a '/' or not.
It will always return 1 except in a certain obscure case
discussed below, where the return 0 means that the complete
lookup was done already. (And this case cannot occur for
sys_chroot, that is why the code there needs not check
the return value.)
A wart
(path_init will always return 1, except when name starts
with a '/', in which case it returns whatever walk_init_root
returns.
walk_init_root will always return 1, except when
current->fs->altroot is non-NULL and nd->flags
does not contain LOOKUP_NOALT (for sys_chroot it does)
and __emul_lookup_dentry succeeds, which it does when
pathwalk succeeds - in this case no path_walk is
required anymore)
Traditionally, one has physical memory, that is, memory that
is actually present in the machine, and virtual memory, that is,
address space. Usually the virtual memory is much larger than
the physical memory, and some hardware or software mechanism
makes sure that a program can transparently use this much larger
virtual space while in fact only the physical memory is available.
Nowadays things are reversed: on a Pentium II one can have 64 GB
physical memory, while addresses have 32 bits, so that the virtual
memory has a size of 4 GB. We'll have to wait for a 64-bit
architecture to get large amounts of virtual memory again.
The present situation on a Pentium with more than 4 GB is
that using the PAE (Physical Address Extension) it is possible
to place the addressable 4 GB anywhere in the available memory,
but it is impossible to have access to more than 4 GB at once.
Kernel and user space work with virtual addresses (also called
linear addresses) that are mapped to physical addresses by the
memory management hardware. This mapping is defined by page
tables, set up by the operating system.
DMA devices use bus addresses. On an i386 PC, bus addresses
are the same as physical addresses, but other architectures
may have special address mapping hardware to convert bus addresses
to physical addresses.
All this is about accessing ordinary memory. There is also
"shared memory" on the PCI or ISA bus. It can be mapped
inside a 32-bit address space using ioremap(),
and then used via the readb(), writeb() (etc.)
functions.
Life is complicated by the fact that there are various caches around,
so that different ways to access the same physical address need not
give the same result.
See asm/io.h and
Documentation/{IO-mapping.txt,DMA-mapping.txt,DMA-API.txt}.
The basic unit of memory is the page.
Nobody knows how large a page is (that is why the Linux swapspace
structure, with a signature at the end of a page, is so unfortunate),
this is architecture-dependent, but typically PAGE_SIZE = 4096.
(PAGE_SIZE equals 1 << PAGE_SHIFT, and PAGE_SHIFT is 12, 13, 14, 15, 16
on the various architectures). If one is lucky, the getpagesize()
system call returns the page size.
Usually, the page size is determined by the hardware: the relation
between virtual addresses and physical addresses is given by page
tables, and when a virtual address is referenced that does not (yet)
correspond to a physical address, a page fault occurs,
and the operating system can take appropriate action.
Most hardware allows a very limited choice of page sizes.
(For example, a Pentium II knows about 4KiB and 4MiB pages.)
Kernel memory allocation
Buddy system
The kernel uses a buddy system with power-of-two sizes. For order
0, 1, 2, ..., 9 it has lists of areas containing 2^order pages.
If a small area is needed and only a larger area is available,
the larger area is split into two halves (buddies), possibly repeatedly.
In this way the waste is at most 50%.
Since 2.5.40, the number of free areas of each order can be seen in
/proc/buddyinfo.
When an area is freed, it is checked whether its buddy is free as well,
and if so they are merged.
Read the code in mm/page_alloc.c.
get_free_page
The routine __get_free_page() will give us a page.
The routine __get_free_pages() will give a number of
consecutive pages. (A power of two, from 1 to 512 or so.
The above buddy system is used.)
kmalloc
The routine kmalloc() is good for an area of unknown, arbitrary,
smallish length, in the range 32-131072 (more precisely: 1/128 of a page
up to 32 pages), preferably below 4096. For the sizes, see
<linux/kmalloc_sizes.h>.
Because of fragmentation, it will be difficult
to get large consecutive areas from kmalloc().
These days kmalloc() returns memory from one of a series
of slab caches (see below) with names like "size-32", ..., "size-131072".
Priority
Each of the above routines has a flags parameter (a bit mask)
indicating what behaviour is allowed.
Deadlock is possible when, in order to free memory, some pages
must be swapped out, or some I/O must be completed, and the driver
needs memory for that. This parameter also indicated where we want
the memory (below 16M for ISA DMA, or ordinary memory, or high memory).
Finally, there is a bit specifying whether we would like a hot or a cold
page (that is, a page likely to be in the CPU cache, or a page not likely
to be there). If the page will be used by the CPU, a hot page will be
faster. If the page will be used for device DMA the CPU cache would be
invalidated anyway, and a cold page does not waste precious cache
contents.
Some common flag values (see linux/gfp.h):
/* Zone modifiers in GFP_ZONEMASK (see linux/mmzone.h - low four bits) */
#define __GFP_DMA 0x01
/* Action modifiers - doesn't change the zoning */
#define __GFP_WAIT 0x10 /* Can wait and reschedule? */
#define __GFP_HIGH 0x20 /* Should access emergency pools? */
#define __GFP_IO 0x40 /* Can start low memory physical IO? */
#define __GFP_FS 0x100 /* Can call down to low-level FS? */
#define __GFP_COLD 0x200 /* Cache-cold page required */
#define GFP_NOIO (__GFP_WAIT)
#define GFP_NOFS (__GFP_WAIT | __GFP_IO )
#define GFP_ATOMIC (__GFP_HIGH)
#define GFP_USER (__GFP_WAIT | __GFP_IO | __GFP_FS)
#define GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS)
Uses:
GFP_KERNEL is the default flag. Sleeping is allowed.
GFP_ATOMIC is used in interrupt handlers. Never sleeps.
GFP_USER for user mode allocations. Low priority, and may sleep.
(Today equal to GFP_KERNEL.)
GFP_NOIO must not call down to drivers (since it is used from
drivers).
GFP_NOFS must not call down to filesystems (since it is used
from filesystems -- see, e.g., dcache.c:shrink_dcache_memory
and inode.c:shrink_icache_memory).
vmalloc
The routine vmalloc() has a similar purpose, but has a better
chance of being able to return larger consecutive areas, and is more
expensive. It uses page table manipulation to create an area of
memory that is consecutive in virtual memory, but not necessarily
in physical memory. Device I/O to such an area is a bad idea.
It uses the above calls with GFP_KERNEL to get its memory, so
cannot be used in interrupt context.
bigphysarea
There is a patch around, the "
bigphysarea patch",
allowing one to reserve a large area at boot time.
Some devices need a lot of room (for video frame grabbing,
scanned images, wavetable synthesis, etc.). See, e.g.,
video/zr36067.c.
The slab cache
The routine kmalloc is general purpose, and may waste
up to 50% space. If certain size areas are needed very frequently,
it makes sense to have separate pools for them.
For example, Linux has separate pools for inodes, dentries, buffer heads.
The pool is created using kmem_cache_create(),
and allocation is by kmem_cache_alloc().
The number of special purpose caches is increasing quickly.
I have here a 2.4.18 system with 63 slab caches, and a 2.5.56 one
with 149 slab caches. Probably this number should be reduced a bit again.
Statistics is found in /proc/slabinfo (and here also statistics
on the kmalloc caches is given). From the man page:
% man 5 slabinfo
...
Frequently used objects in the Linux kernel (buffer heads,
inodes, dentries, etc.) have their own cache. The file
/proc/slabinfo gives statistics. For example:
% cat /proc/slabinfo
slabinfo - version: 1.1
kmem_cache 60 78 100 2 2 1
blkdev_requests 5120 5120 96 128 128 1
mnt_cache 20 40 96 1 1 1
inode_cache 7005 14792 480 1598 1849 1
dentry_cache 5469 5880 128 183 196 1
filp 726 760 96 19 19 1
buffer_head 67131 71240 96 1776 1781 1
vm_area_struct 1204 1652 64 23 28 1
...
size-8192 1 17 8192 1 17 2
size-4096 41 73 4096 41 73 1
...
For each slab cache, the cache name, the number of cur
rently active objects, the total number of available
objects, the size of each object in bytes, the number of
pages with at least one active object, the total number of
allocated pages, and the number of pages per slab are
given.
QuestionOne of the reasons given for a slab cache
is that it will give areas of the precise required size, and thus
reduce memory waste. In the man page example above, look at how many
pages are used for each slab cache, and how much space it would have cost
to kmalloc() everything. Does the slab cache do better?
Having a slab cache has some other advantages besides reducing waste.
Allocation and freeing is faster than with the buddy system.
There is an attempt at doing some cache colouring.
Let us look at an explicit machine to see how addressing is done.
This is only a very brief description. For all details, see some
Intel manual. (I have here 24547209.pdf, entitled
IA-32 Intel Architecture Software Developer's Manual Volume 3,
with Chapter 3: Protected Mode Memory Management.
It can be downloaded from
developer.intel.com.)
Addressing goes in two stages: a logical address determined by
segment and offset is translated into a linear address, and next
the linear address is translated into a physical address.
Real mode assembler programmers may be familiar with the first stage:
one has a 16-bit segment register with value S and 16- or 32-bit offset O,
that produce a 20- or 32-bit linear address A = 16*S + O, and this
is also the physical address.
There are six segment registers: CS, SS, DS, ES, FS, GS.
The first is used when instructions are fetched, the second for
stack access, the third for data access, and override prefixes
allow one to specify any of the six.
Segmentation
In protected mode one still has segmentation (although most systems
do not use it - the corresponding hardware is just wasted and present
only for compatibility reasons), but one also has paging.
The paging is optional (it can be enabled/disabled), but this unused
segmentation is always present, and much more complicated than in real mode.
Instead of a single 16-bit value, the segmentation register S is now a
13-bit index I followed by the single bit value TI (Table Index) and
the 2-bit value RPL (Requested Protection Level). The bit TI selects
one of two tables: the GDT (Global Descriptor Table) or the LDT
(Local Descriptor Table). Each can have up to 8192 entries, and the
13-bit index I selects an entry in one of these tables.
Such an entry is an 8-byte struct that has a 32-byte field base,
and a 20-byte field limit and several small fields.
Here base gives the start of the segment, and limit
its length minus one. One of the small fields is a 1-bit value G (Granularity).
If this is zero then limit is measured in bytes,
if it is one then limit is measured in 4 KiB units.
Now that we have the base address B of the segment, add the 32-bit offset O
to obtain the linear address.
Paging
When paging is enabled (as it is under Linux) we are only halfway,
and this useless segmentation stuff is followed by the extremely useful
paging. The linear address A is divided into three parts:
a 10-bit directory AD, a 10-bit table AT and a
12-bit offset AO. The corresponding physical address is now
found in four stages.
(i) The CR3 processor register points at the page directory.
(ii) Index the page directory with AD to find a page table.
(iii) Index the page table with AT to find the page.
(iv) Index the page with AO to find the physical address.
Thus, the page directory is a table with up to 1024 entries.
Each of these entries points to a page table that itself has
up to 1024 entries. Each of these point to a page.
The entries in page directory and page table have 32 bits,
but only the first 20 are needed for the address since by convention
pages and page tables start at a 4 KiB boundary so that the last
12 address bits are zero. In page directory and page table these
last bits are used for bookkeeping purposes. By far the most
important bit is the "present" bit. If the user program refers
to a page that is not actually present (according to this bit
in the page table) a page fault is generated, and the
operating system might fetch the page, map it somewhere in memory,
and continue the user program.
Apart from the "present" bit there is the "dirty" bit, that indicates
whether the page was modified, the "accessed" bit, that indicates that
the page was read, and permission bits.
The above was for 4 KiB pages. There are also 4 MiB pages,
where one indexing stage is absent and the offset part has 22 bits.
(With PAE one also has 2 MiB pages.)
Normally, a user-space program reserves (virtual) memory by calling
malloc().
If the return value is NULL, the program knows that no more memory is
available, and can do something appropriate. Most programs will print
an error message and exit, some first need to clean up lockfiles or so,
and some smarter programs can do garbage collection, or adapt the computation
to the amount of available memory. This is life under Unix, and all is well.
Linux on the other hand is seriously broken.
It will by default answer "yes" to most requests for memory, in the hope
that programs ask for more than they actually need. If the hope is fulfilled
Linux can run more programs in the same memory, or can run a program that
requires more virtual memory than is available.
And if not then very bad things happen.
What happens is that the OOM killer (OOM = out-of-memory)
is invoked, and it will select some process and kill it.
One holds long discussions about the choice of the victim.
Maybe not a root process, maybe not a process doing raw I/O,
maybe not a process that has already spent weeks doing some computation.
And thus it can happen that one's emacs is killed when someone else
starts more stuff than the kernel can handle. Ach.
Very, very primitive.
Of course, the very existence of an OOM killer is a bug.
A typical case: I do umount -a in a situation where 30000
filesystems are mounted. Now umount runs out of memory and
the kernel log reports
Sep 19 00:33:10 mette kernel: Out of Memory: Killed process 8631 (xterm).
Sep 19 00:33:34 mette kernel: Out of Memory: Killed process 9154 (xterm).
Sep 19 00:34:05 mette kernel: Out of Memory: Killed process 6840 (xterm).
Sep 19 00:34:42 mette kernel: Out of Memory: Killed process 9066 (xterm).
Sep 19 00:35:15 mette kernel: Out of Memory: Killed process 9269 (xterm).
Sep 19 00:35:43 mette kernel: Out of Memory: Killed process 9351 (xterm).
Sep 19 00:36:05 mette kernel: Out of Memory: Killed process 6752 (xterm).
Randomly xterm windows are killed, until the xterm window
that was X's console is killed. Then X exits and all
user processes die, including the umount process that caused all this.
OK. This is very bad. People lose long-running processes, lose weeks
of computation, just because the kernel is an optimist.
Demo program 1: allocate memory without using it.
#include <stdio.h>
#include <stdlib.h>
int main (void) {
int n = 0;
while (1) {
if (malloc(1<<20) == NULL) {
printf("malloc failure after %d MiB\n", n);
return 0;
}
printf ("got %d MiB\n", ++n);
}
}
Demo program 2: allocate memory and actually touch it all.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main (void) {
int n = 0;
char *p;
while (1) {
if ((p = malloc(1<<20)) == NULL) {
printf("malloc failure after %d MiB\n", n);
return 0;
}
memset (p, 0, (1<<20));
printf ("got %d MiB\n", ++n);
}
}
Demo program 3: first allocate, and use later.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define N 10000
int main (void) {
int i, n = 0;
char *pp[N];
for (n = 0; n < N; n++) {
pp[n] = malloc(1<<20);
if (pp[n] == NULL)
break;
}
printf("malloc failure after %d MiB\n", n);
for (i = 0; i < n; i++) {
memset (pp[i], 0, (1<<20));
printf("%d\n", i+1);
}
return 0;
}
Typically, the first demo program will get a very large amount of memory
before malloc() returns NULL. The second demo program
will get a much smaller amount of memory, now that earlier obtained memory
is actually used. The third program will get the same large amount as
the first program, and then is killed when it wants to use its memory.
(On a well-functioning system, like Solaris, the three demo programs
obtain the same amount of memory and do not crash but see malloc()
return NULL.)
For example:
On an 8 MiB machine without swap running 1.2.11:
demo1: 274 MiB,
demo2: 4 MiB,
demo3: 270 / oom after 1 MiB: Killed.
Idem, with 32 MiB swap:
demo1: 1528 MiB,
demo2: 36 MiB,
demo3: 1528 / oom after 23 MiB: Killed.
On a 32 MiB machine without swap running 2.0.34:
demo1: 1919 MiB,
demo2: 11 MiB,
demo3: 1919 / oom after 4 MiB: Bus error.
Idem, with 62 MiB swap:
demo1: 1919 MiB,
demo2: 81 MiB, demo3: 1919 / oom after 74 MiB:
The machine hangs. After several seconds: Out of memory for bash.Out of memory for crond. Bus error.
On a 256 MiB machine without swap running 2.6.8.1:
demo1: 2933 MiB,
demo2: after 98 MiB: Killed.
Also: Out of Memory: Killed process 17384 (java_vm).
demo3: 2933 / oom after 135 MiB: Killed.
Idem, with 539 MiB swap:
demo1: 2933 MiB,
demo2: after 635 MiB: Killed.
demo3: oom after 624 MiB: Killed.
Other kernels have other strategies. Sometimes processes get a
segfault when accessing memory that the kernel is unable to provide,
sometimes they are killed, sometimes other processes are killed,
sometimes the kernel hangs.
Turning off overcommit
Going in the wrong direction
Since 2.1.27 there are a sysctl VM_OVERCOMMIT_MEMORY
and proc file /proc/sys/vm/overcommit_memory with values
1: do overcommit, and 0 (default): don't.
Unfortunately, this does not allow you to tell the kernel to be
more careful, it only allows you to tell the kernel to be less careful.
With overcommit_memory set to 1 every malloc() will succeed.
When set to 0 the old heuristics are used, the kernel still overcommits.
Going in the right direction
Since 2.5.30 the values are:
0 (default): as before: guess about how much overcommitment is reasonable,
1: never refuse any malloc(),
2: be precise about the overcommit - never commit a virtual address space
larger than swap space plus a fraction overcommit_ratio
of the physical memory. Here /proc/sys/vm/overcommit_ratio
(by default 50) is another user-settable parameter. It is possible to
set overcommit_ratio to values larger than 100.
(See also Documentation/vm/overcommit-accounting.)
After
# echo 2 > /proc/sys/vm/overcommit_memory
all three demo programs were able to obtain 498 MiB on this 2.6.8.1
machine (256 MiB, 539 MiB swap, lots of other active processes),
very satisfactory.
However, without swap, no more processes could be started - already
more than half of the memory was committed. After
# echo 80 > /proc/sys/vm/overcommit_ratio
all three demo programs were able to obtain 34 MiB.
(Exercise: solve two equations with two unknowns and conclude
that main memory was 250 MiB, and the other processes took 166 MiB.)
One can view the currently committed amount of memory in
/proc/meminfo, in the field Committed_AS.
Before looking at the Linux implementation, first a general Unix
description of threads, processes, process groups and sessions.
A session contains a number of process groups, and a process group
contains a number of processes, and a process contains a number
of threads.
A session can have a controlling tty.
At most one process group in a session can be a foreground process group.
An interrupt character typed on a tty ("Teletype", i.e., terminal)
causes a signal to be sent to all members of the foreground process group
in the session (if any) that has that tty as controlling tty.
All these objects have numbers, and we have thread IDs, process IDs,
process group IDs and session IDs.
A new process is traditionally started using the fork()
system call:
pid_t p;
p = fork();
if (p == (pid_t) -1)
/* ERROR */
else if (p == 0)
/* CHILD */
else
/* PARENT */
This creates a child as a duplicate of its parent.
Parent and child are identical in almost all respects.
In the code they are distinguished by the fact that the parent
learns the process ID of its child, while fork()
returns 0 in the child. (It can find the process ID of its
parent using the getppid() system call.)
Termination
Normal termination is when the process does
exit(n);
or
return n;
from its main() procedure. It returns the single byte n
to its parent.
Abnormal termination is usually caused by a signal.
Collecting the exit code. Zombies
The parent does
pid_t p;
int status;
p = wait(&status);
and collects two bytes:
A process that has terminated but has not yet been waited for
is a zombie. It need only store these two bytes:
exit code and reason for termination.
On the other hand, if the parent dies first, init (process 1)
inherits the child and becomes its parent.
Signals
Stopping
Some signals cause a process to stop:
SIGSTOP (stop!),
SIGTSTP (stop from tty: probably ^Z was typed),
SIGTTIN (tty input asked by background process),
SIGTTOU (tty output sent by background process, and this was
disallowed by stty tostop).
Apart from ^Z there also is ^Y. The former stops the process
when it is typed, the latter stops it when it is read.
Signals generated by typing the corresponding character on some tty
are sent to all processes that are in the foreground process group
of the session that has that tty as controlling tty. (Details below.)
If a process is being traced, every signal will stop it.
Continuing
SIGCONT: continue a stopped process.
Terminating
SIGKILL (die! now!),
SIGTERM (please, go away),
SIGHUP (modem hangup),
SIGINT (^C),
SIGQUIT (^\), etc.
Many signals have as default action to kill the target.
(Sometimes with an additional core dump, when such is
allowed by rlimit.)
The signals SIGCHLD and SIGWINCH
are ignored by default.
All except SIGKILL and SIGSTOP can be
caught or ignored or blocked.
For details, see signal(7).
Every process is member of a unique process group,
identified by its process group ID.
(When the process is created, it becomes a member of the process group
of its parent.)
By convention, the process group ID of a process group
equals the process ID of the first member of the process group,
called the process group leader.
A process finds the ID of its process group using the system call
getpgrp(), or, equivalently, getpgid(0).
One finds the process group ID of process p using
getpgid(p).
One may use the command ps j to see PPID (parent process ID),
PID (process ID), PGID (process group ID) and SID (session ID)
of processes. With a shell that does not know about job control,
like ash, each of its children will be in the same session
and have the same process group as the shell. With a shell that knows
about job control, like bash, the processes of one pipeline. like
% cat paper | ideal | pic | tbl | eqn | ditroff > out
form a single process group.
Creation
A process pid is put into the process group pgid by
setpgid(pid, pgid);
If pgid == pid or pgid == 0 then this creates
a new process group with process group leader pid.
Otherwise, this puts pid into the already existing
process group pgid.
A zero pid refers to the current process.
The call setpgrp() is equivalent to setpgid(0,0).
Restrictions on setpgid()
The calling process must be pid itself, or its parent,
and the parent can only do this before pid has done
exec(), and only when both belong to the same session.
It is an error if process pid is a session leader
(and this call would change its pgid).
This ensures that regardless of whether parent or child is scheduled
first, the process group setting is as expected by both.
Signalling and waiting
One can signal all members of a process group:
killpg(pgrp, sig);
One can wait for children in ones own process group:
waitpid(0, &status, ...);
or in a specified process group:
waitpid(-pgrp, &status, ...);
Foreground process group
Among the process groups in a session at most one can be
the foreground process group of that session.
The tty input and tty signals (signals generated by ^C, ^Z, etc.)
go to processes in this foreground process group.
A process can determine the foreground process group in its session
using tcgetpgrp(fd), where fd refers to its
controlling tty. If there is none, this returns a random value
larger than 1 that is not a process group ID.
A process can set the foreground process group in its session
using tcsetpgrp(fd,pgrp), where fd refers to its
controlling tty, and pgrp is a process group in the
its session, and this session still is associated to the controlling
tty of the calling process.
How does one get fd? By definition, /dev/tty
refers to the controlling tty, entirely independent of redirects
of standard input and output. (There is also the function
ctermid() to get the name of the controlling terminal.
On a POSIX standard system it will return /dev/tty.)
Opening the name of the
controlling tty gives a file descriptor fd.
Background process groups
All process groups in a session that are not foreground
process group are background process groups.
Since the user at the keyboard is interacting with foreground
processes, background processes should stay away from it.
When a background process reads from the terminal it gets
a SIGTTIN signal. Normally, that will stop it, the job control shell
notices and tells the user, who can say fg to continue
this background process as a foreground process, and then this
process can read from the terminal. But if the background process
ignores or blocks the SIGTTIN signal, or if its process group
is orphaned (see below), then the read() returns an EIO error,
and no signal is sent. (Indeed, the idea is to tell the process
that reading from the terminal is not allowed right now.
If it wouldn't see the signal, then it will see the error return.)
When a background process writes to the terminal, it may get
a SIGTTOU signal. May: namely, when the flag that this must happen
is set (it is off by default). One can set the flag by
% stty tostop
and clear it again by
% stty -tostop
and inspect it by
% stty -a
Again, if TOSTOP is set but the background process ignores or blocks
the SIGTTOU signal, or if its process group is orphaned (see below),
then the write() returns an EIO error, and no signal is sent.
Orphaned process groups
The process group leader is the first member of the process group.
It may terminate before the others, and then the process group is
without leader.
A process group is called orphaned when the
parent of every member is either in the process group
or outside the session.
In particular, the process group of the session leader
is always orphaned.
If termination of a process causes a process group to become
orphaned, and some member is stopped, then all are sent first SIGHUP
and then SIGCONT.
The idea is that perhaps the parent of the process group leader
is a job control shell. (In the same session but a different
process group.) As long as this parent is alive, it can
handle the stopping and starting of members in the process group.
When it dies, there may be nobody to continue stopped processes.
Therefore, these stopped processes are sent SIGHUP, so that they
die unless they catch or ignore it, and then SIGCONT to continue them.
Note that the process group of the session leader is already
orphaned, so no signals are sent when the session leader dies.
Note also that a process group can become orphaned in two ways
by termination of a process: either it was a parent and not itself
in the process group, or it was the last element of the process group
with a parent outside but in the same session.
Furthermore, that a process group can become orphaned
other than by termination of a process, namely when some
member is moved to a different process group.
Every process group is in a unique session.
(When the process is created, it becomes a member of the session
of its parent.)
By convention, the session ID of a session
equals the process ID of the first member of the session,
called the session leader.
A process finds the ID of its session using the system call
getsid().
Every session may have a controlling tty,
that then also is called the controlling tty of each of
its member processes.
A file descriptor for the controlling tty is obtained by
opening /dev/tty. (And when that fails, there was no
controlling tty.) Given a file descriptor for the controlling tty,
one may obtain the SID using tcgetsid(fd).
A session is often set up by a login process. The terminal
on which one is logged in then becomes the controlling tty
of the session. All processes that are descendants of the
login process will in general be members of the session.
Creation
A new session is created by
pid = setsid();
This is allowed only when the current process is not a process group leader.
In order to be sure of that we fork first:
p = fork();
if (p) exit(0);
pid = setsid();
The result is that the current process (with process ID pid)
becomes session leader of a new session with session ID pid.
Moreover, it becomes process group leader of a new process group.
Both session and process group contain only the single process pid.
Furthermore, this process has no controlling tty.
The restriction that the current process must not be a process group leader
is needed: otherwise its PID serves as PGID of some existing process group
and cannot be used as the PGID of a new process group.
Getting a controlling tty
How does one get a controlling terminal? Nobody knows,
this is a great mystery.
The System V approach is that the first tty opened by the process
becomes its controlling tty.
The BSD approach is that one has to explicitly call
ioctl(fd, TIOCSCTTY, ...);
to get a controlling tty.
Linux tries to be compatible with both, as always, and this
results in a very obscure complex of conditions. Roughly:
The TIOCSCTTY ioctl will give us a controlling tty,
provided that (i) the current process is a session leader,
and (ii) it does not yet have a controlling tty, and
(iii) maybe the tty should not already control some other session;
if it does it is an error if we aren't root, or we steal the tty
if we are all-powerful.
Opening some terminal will give us a controlling tty,
provided that (i) the current process is a session leader, and
(ii) it does not yet have a controlling tty, and
(iii) the tty does not already control some other session, and
(iv) the open did not have the O_NOCTTY flag, and
(v) the tty is not the foreground VT, and
(vi) the tty is not the console, and
(vii) maybe the tty should not be master or slave pty.
Getting rid of a controlling tty
If a process wants to continue as a daemon, it must detach itself
from its controlling tty. Above we saw that setsid()
will remove the controlling tty. Also the ioctl TIOCNOTTY does this.
Moreover, in order not to get a controlling tty again as soon as it
opens a tty, the process has to fork once more, to assure that it
is not a session leader. Typical code fragment:
if ((fork()) != 0)
exit(0);
setsid();
if ((fork()) != 0)
exit(0);
See also daemon(3).
Disconnect
If the terminal goes away by modem hangup, and the line was not local,
then a SIGHUP is sent to the session leader.
Any further reads from the gone terminal return EOF.
(Or possibly -1 with errno set to EIO.)
If the terminal is the slave side of a pseudotty, and the master side
is closed (for the last time), then a SIGHUP is sent to the foreground
process group of the slave side.
When the session leader dies, a SIGHUP is sent to all processes
in the foreground process group. Moreover, the terminal stops being
the controlling terminal of this session (so that it can become
the controlling terminal of another session).
Thus, if the terminal goes away and the session leader is
a job control shell, then it can handle things for its descendants,
e.g. by sending them again a SIGHUP.
If on the other hand the session leader is an innocent process
that does not catch SIGHUP, it will die, and all foreground processes
get a SIGHUP.
A process can have several threads. New threads (with the same PID
as the parent thread) are started using the clone system
call using the CLONE_THREAD flag. Threads are distinguished
by a thread ID (TID). An ordinary process has a single thread
with TID equal to PID. The system call gettid() returns the
TID. The system call tkill() sends a signal to a single thread.
Example: a process with two threads. Both only print PID and TID and exit.
(Linux 2.4.19 or later.)
An ASR33 Teletype - origin of the abbreviation tty.
We meet several kinds of objects (character devices, tty drivers,
line disciplines). Each registers itself at kernel initialization
time (or module insertion time), and can afterwards be found
when an open() is done.
A character device announces its existence by calling
register_chrdev(). The call
register_chrdev(major, name, fops);
stores the given name (a string) and fops
(a struct file_operations *) in the entry of the array
chrdevs[] indexed by the integer major,
the major device number of the device.
(Devices have a number, the device number,
a combination of major and minor device number.
Traditionally, the major device number gives the kind of device,
and the minor device number is some kind of unit number.
However, there are no rules - it is best to consider a device
number a cookie, without known structure.)
This stored entry is used again when the device is opened:
The filesystem recognizes that the file that is being opened
is a special device file, and invokes
init_special_inode().
This routine does
Here to_kdev_t() converts the user mode version of the
device number to the kernel version of the device number.
The cdget() returns the struct char_device for this
major number. It finds it using a hash table, and if we did not
have it already, a new one is allocated. In all cases, the
reference count of this struct is increased by one.
The struct looks like
Here hash is a link in the chain of devices with the same hash,
count is the number of references - each cdget()
increases and each cdput() decreases this by one,
and if it becomes zero, the struct is removed from the hash chain
and freed. The field dev stores the device number, the
only thing we know about this device.
The fields openers and sem are unused.
Access to the hash table is protected by the cdev_lock
spinlock.
That is, we cannot do anything with the character device except
opening it, and when we do chrdev_open() is called.
On struct char_device
What is the use of this struct? After removing the unused fields
openers and sem we see that we just have a struct
in a hash chain and a reference count. It has no function at all,
and all related code can be deleted (from 2.5.59).
The system call routine sys_open()
calls filp_open(), and that calls dentry_open(),
which does
f->f_op = fops_get(inode->i_fop);
In other words, the file f_op is a copy of the inode
i_fop. (This fops_get() returns its argument,
but increments a reference count in case these file operations
live in a module.)
Finally, dentry_open() calls the inode open routine if
there is one:
if (f->f_op && f->f_op->open)
f->f_op->open(inode,f);
Thus, it is here that chrdev_open() is called.
int chrdev_open(struct inode *inode, struct file *filp) {
int ret = -ENODEV;
filp->f_op = get_chrfops(major(inode->i_rdev), minor(inode->i_rdev));
if (filp->f_op) {
ret = 0;
if (filp->f_op->open)
ret = ret = filp->f_op->open(inode,filp);
}
return ret;
}
And the routine get_chrfops() retrieves the
struct file operations * that was registered:
struct file_operations *get_chrfops(unsigned int major, unsigned int minor) {
return fops_get(chrdevs[major].fops);
}
(The actual routine checks whether the device did register already,
and if not does a request_module("char-major-N") first,
where N is the major number.)
We see that the inode fops remains unchanged, so that its open
still points to chrdev_open(), but the file fops is changed
and now points to what the device registered.
Let us focus on /dev/tty1, the first virtual console.
Most code lives in drivers/char, in the files
tty_io.c and n_tty.c and vt.c.
Registration
A tty driver announces its existence by calling tty_register_driver().
This call does a register_chrdev() (with tty_fops)
and hangs the driver in the chain tty_drivers.
That chain is used by get_tty_driver(), a routine that
given a device number finds the tty driver that handles the device
with that number.
get_tty_driver
This routine is used in two places: in fs/char_dev.c:get_chrfops()
and in tty_io.c:init_dev(), called from tty_open.
The latter use was expected, but what is this strange first use?
#define is_a_tty_dev(ma) (ma == TTY_MAJOR || ma == TTYAUX_MAJOR)
#define need_serial(ma,mi) (get_tty_driver(mk_kdev(ma,mi)) == NULL)
static struct file_operations *
get_chrfops(unsigned int major, unsigned int minor) {
...
ret = fops_get(chrdevs[major].fops);
if (ret && is_a_tty_dev(major) && need_serial(major,minor)) {
fops_put(ret);
ret = NULL;
}
if (!ret) {
char name[20];
sprintf(name, "char-major-%d", major);
request_module(name);
ret = fops_get(chrdevs[major].fops);
}
return ret;
}
The idea here is that majors 4 and 5 (TTY_MAJOR and TTYAUX_MAJOR)
may be served by several modules.
Indeed, /dev/tty1 has major,minor 4,1 and is a virtual
console, while /dev/ttyS1 has major,minor 4,65 and is
a serial line. Thus, in drivers/serial/core.c:uart_register_driver()
we see a call of tty_register_driver(), and this former routine
is called, e.g., to register serial8250_reg, defined as
while vt.c:vty_init() calls tty_register_driver()
to register console_driver with major = TTY_MAJOR
and minor_start = 1.
Opening
As we saw above, opening a character device ends up with calling
the open routine from the struct file_operations registered by the
device. In the case of a tty, the open routine in tty_fops
is tty_open.
The routine tty_open is long and messy, with a lot of
special purpose code for controlling ttys, for pseudottys, etc.
In the ordinary case the essential part is
Thus, first of all, we create a tty_struct.
Next, a pointer to this tty_struct is stored in the
private_data field of the file struct, so that we
can find it later, for example in tty_read():
Note that the entire struct tty_driver is copied in the assignment,
so that individual fields can be changed without damaging the struct
that was registered. However, this is never done, so having a copy
is a waste of memory.
Line disciplines
The line discipline gives the protocol on the serial line.
Each line discipline has a number, and the normal one is called
N_TTY (0).
Line disciplines are registered by tty_register_ldisc(),
by storing a struct tty_ldisc in the array ldiscs[]
(where the index is the line discipline number).
The normal discipline is registered by console_init(),
as first among the registered disciplines:
Thus, when tty->ldisc.open is called, it is the open field
of the struct tty_ldisc_N_TTY. This struct lives in
n_tty.c and its open field is n_tty_open.
More opening
After this preparation, finally tty->driver.open(tty,file)
is called. Now that we had /dev/tty1 in mind, that is, one of
the virtual consoles, let us see what routine this is.
In vt.c:vty_init() we see
So, our open routine is con_open(), an amusing open routine.
It creates a virtual console if there wasn't one. So, if you have
8 virtual consoles but open /dev/tty23 then you have 9.
If you have lots of unused consoles and want to free the memory
they take, use the command deallocvt.
ExerciseWhich keystroke changes to console 23?
Reading
The system call sys_read() is found in fs/read_write.c.
It calls vfs_read(), and this calls file->f_op->read().
In our case, this is the read routine of tty_fops, which
unsurprisingly is tty_read. And above we saw that this
calls tty->ldisc.read, which is the read field of
tty_ldisc_N_TTY, called read_chan.
The code is in n_tty.c. It downs the semaphore
tty->atomic_read, hangs itself in the wait queue
tty->read_wait of waiters for input, goes to sleep
if no input is available, copies input to the user buffer,
ups the semaphore tty->atomic_read and returns.
(Reality is much more complicated. Try to read the code.)
So, hopefully, somebody will fill the input buffer. Who?
Keyboard interrupts arrive at
input/keyboard/atkbd.c:atkbd_interrupt().
It handles the keyboard protocol and converts scancode to
keycode. Then input_report_key() is called, a define
for input_event(), and this routine offers the event
to all registered handlers.
Now keyboard.c:kbd_init() registers kbd_handler,
and the result is that keyboard keystrokes will be handled by
keyboard.c:kbd_event(), which calls kbd_keycode().
Here keyboard raw, mediumraw, xlate and unicode modes are handled,
as is the magic sysrequest key. Scancodes have already been converted
to keycodes, here we convert back (yecch) for raw mode, leave things
for mediumraw mode, or further convert keycodes to characters using
the keymap (set by the utility loadkeys). Finally we call
put_queue(vc, byte);
with the resulting bytes. Here vc is the foreground virtual console.
that is, put_queue() retrieves vc->vc_tty
that was set by con_open(), and puts its stuff in the
flip buffer. Then the work of transporting this to the read_buffer
is scheduled. (In tty raw mode that is a plain copy, but in canonical
mode we must react to special characters: the erase character erases,
the interrupt character sends an interrupt, etc.)
And when the transporting has been done, the bytes are ready to
be read by a read() call.
Writing
Here things are entirely analogous. The system call sys_write()
calls vfs_write(), and this calls file->f_op->write().
In our case, this is the write routine of tty_fops, which
is tty_write.
It does do_tty_write(tty->ldisc.write, ...) which downs
the semaphore tty->atomic_write, possibly splits up the write
into smaller chunks, calls its first argument and ups the semaphore again.
The write routine here is the write field of tty_ldisc_N_TTY,
called write_chan. The code is in n_tty.c.
It hangs itself in the wait queue tty->write_wait
of waiters for room for output, tries to write by calling
tty->driver.write, and if that fails to write everything
goes to sleep.
Now our driver was console_driver with write routine
con_write that calls do_con_write.
Here very obscure things are done to handle escape sequences
(cursor movement, screen colours, scrolling, etc. etc.),
but in the normal case we see
scr_writew((attr << 8) + byte, screenpos);
that actually writes the character and the (foreground / background /
intensity) attributes. All very messy code - not a joy to behold.
Raw devices are character devices that can be bound to block devices.
I/O from/to raw devices bypasses the block caches.
Whether that is desirable depends on the application.
Usually it is undesirable - there are all kinds of issues
with raw devices. A main problem is that of coherency -
the block device should not also be accessed directly.
An annoyance is that I/O buffers must be aligned.
Very few standard programs do this.
The code for the raw device does set_blocksize(),
so that bad things happen if the device was open already
and using a different blocksize. Really, if raw is used
it must be the only access path to the block device.
private_data
The block device belonging to a raw device is noted down in
the private_data field of the file struct.
ioctls
There are two ioctls: RAW_SETBIND and RAW_GETBIND.
The former connects a given raw device to a block device specified
by major, minor. The latter reports on a connection.
The file descriptor needed for the ioctl is that of the control raw
device, with minor number zero.
Unbinding is done by binding to major,minor = 0,0.
Binding is done by setting the i_mapping field of the raw device
inode to the i_mapping field of the block device. After rebinding
this will crash certain kernels because the inode for the block device
may have gone away.
For security purposes Linux has the devices /dev/random
and /dev/urandom. The former produces cryptographically
strong bits, but may block when no entropy is available.
The latter uses bits from the former when available, and
a strong random generator otherwise, and does not block.
ExerciseTrydd if=/dev/urandom of=/dev/null bs=1024 count=1000and immediately afterwardsdd if=/dev/random of=/dev/null bs=1024 count=1.
The former produces (more than) a megabyte of pseudorandom bits
in less than a second. Probably this will have exhausted
the entropy pool, and the latter will block until some randomness
arrives. Move the mouse a little.
Randomness is needed in-kernel, e.g. for TCP sequence numbers - these
must be hard to predict by an attacker to prevent spoofing -, and in
user space for passwords or secret keys used to protect something -
say the key for the .Xauthority file to protect access to
the X server. The random character device is a standard part of
the kernel, not something one selects with a config option.
The random device is a subdevice of the mem (for memory) device.
The character device major 1 has subdevices mem, kmem,
null, port, zero, full,
random, urandom, kmsg
(for minors 1,2,3,4,5,7,8,9,11 - long ago minor 6 was /dev/core,
while minor 10 was reserved for /dev/aio but when aio was
implemented it was done differently).
Thus, the registration is found in drivers/char/mem.c
Randomness is stored in the entropy_store, which has
an associated variable entropy_count counting available
random bits. The routine random_read() sees whether we
have some bits, and if so returns them, and otherwise sleeps.
The routine urandom_read() just extracts some bits.
So the question is how to obtain randomness. Something nobody
can predict even when all running software is known.
The random device uses four sources, namely the routines
add_X_randomness, for
X = keyboard, mouse, disk,
interrupt. The keyboard, and the mouse, and each IRQ,
and each disk have an associated structure
struct timer_rand_state {
__u32 last_time;
__s32 last_delta,last_delta2;
int dont_count_entropy:1;
};
that remembers when we last did something, and the first and second order
differences in the sequence of points in time. The routines
add_keyboard_randomness() etc. call
add_timer_randomness(), and the current time and the
value contributed by the routine (keyboard scancode, mouse data, etc.)
are mixed into the pool. In order to estimate the amount of entropy
added, only the time is used, not the scancode (etc.) data.
Sysfs is a virtual filesystem that describes the devices known to the
system from various viewpoints. By default it is mounted on /sys.
The basic building blocks of the hierarchy are kobjects.
The entire setup is strange and messy and will cause lots of bugs.
Let us start looking at the reference counting part (nothing wrong
with that).
An atomic_t is an integer variable that can be inspected and changed
atomically. It is mostly used for reference counting and semaphores.
On i386 it is defined as
typedef struct { volatile int cnt; } atomic_t;
and available methods (with int i and atomic_t *v) are
Here the right hand sides define the intended effect,
but the code must be written in assembler to guarantee atomicity.
The definitions can be found in <asm/atomic.h>.
E.g. for i386:
where the LOCK becomes a lock prefix 0xf0
on an SMP machine. For the i386 a simple aligned read is atomic:
#define atomic_read(v) ((v)->cnt)
The contents used to be a 24-bit counter, because sparc used
the low byte as a spinlock, e.g.,
static inline int atomic24_read(const atomic24_t *v) {
int ret = v->cnt;
while(ret & 0xff)
ret = v->cnt;
return ret >> 8;
}
but since Linux 2.6.3 also sparc has a 32-bit counter.
(The reason the Sparc is troublesome is that its 32-bit memory writes
are not atomic: it is possible for another CPU to come and read memory
and find some old and some new bytes, a partly written result.)
Thus, today a struct kref is just an atomic_t.
Still, it is a useful abstraction: it has far fewer methods,
so reasoning about it is simpler.
Earlier the struct kref had a release field,
but all uses turned out to be such that the caller knew the appropriate
release function, so that it could be a parameter of kref_put(),
saving memory.
Releasing just the struct kref would not be very meaningful.
The typical use is shown by
Every struct kobject has a name, which must not be NULL.
The name is kobj->k_name, and this pointer points
either to the internal array, if the name is short, or to an
external string obtained from kmalloc() and to be kfree()d
when the kobject dies. However, we are not supposed to know this -
the name is returned by kobject_name(kobj) and set by
kobject_set_name(kobj, format, ...). (But that latter routine
cannot fail in case the name we use has length less than 20.)
The name is set independently of other initialization.
A struct kobject may be member of a set, given by the
kset field. Otherwise, this field is NULL.
The kset field must be set before calling kobject_init().
The entry field is either empty or part of the circularly
linked list containing members of the kset.
A struct kobject is reference counted.
The routines kobject_get() and kobject_put()
do get/put on the kref field. When the reference count
drops to zero, a kobject_cleanup() is done.
A struct kobject must be initialized by kobject_init().
This does the kref_init that sets the refcount to 1,
initializes the entry field to an empty circular list,
and does
kobj->kset = kset_get(kobj->kset);
which does not change kobj->kset but increments its
refcount: one more element of the set.
Note that most fields are not touched by kobject_init().
One should memset it to zero and possibly assign kset
before calling kobject_init().
One of the main purposes of a struct kobject is to appear
in the sysfs tree. It is added in the tree by kobject_add()
and deleted again by kobject_del().
The former calls kobject_hotplug("add",kobj), the latter
kobject_hotplug("remove", kobj).
The sysfs dentry is given by the field dentry.
The parent directory in the tree is represented by the
kobject parent.
The routine sysfs_create_dir() will hang a new directory
directly below the root /sys when no parent is given.
Let us list the kobject methods (with struct kobject *ko)
int kobject_set_name(ko, char *, ...)
char *kobject_name(ko)
void kobject_init(ko)
struct kobject *kobject_get(ko)
void kobject_put(ko)
void kobject_cleanup(ko)
int kobject_add(ko)
void kobject_del(ko)
int kobject_register(ko)
void kobject_unregister(ko)
int kobject_rename(ko, char *new_name)
void kobject_hotplug(const char *action, ko)
char *kobject_get_path(struct kset *, ko, int)
Most of these were mentioned above. The routine kobject_register()
does kobject_init(); kobject_add(), and kobject_unregister()
does kobject_del(); kobject_put(). This is the preferred way of
handling kobjects that are represented in the sysfs tree.
The field list provides a circularly linked list
of the kobjects that are members of the kset.
All kobjects on the list have a kset field that
points back to us. In order to examine or manipulate the list,
one needs to hold the kset->subsys->rwsem semaphore.
The set is also itself a kobject, given by the field kobj.
The routine to_kset() converts a pointer to the kobject
field of a kset into a pointer to the kset itself.
The routine kset_init() initializes the fields list
and kobj. The routine kset_get() does
to_kset(kobject_get(&ks->kobj))
a rather complicated way of doing kobject_get(&ks->kobj)
and returning ks again. The routine kset_put()
does kobject_put(&ks->kobj).
The routine kset_add() does a kobject_add() of
its kobject. If that kobject did not yet have a parent or kset
and we have a subsys, set the kobject's parent to the kobject of
the kset of the subsys. On the other hand, if that kobject has
a kset but no parent, then kobject_add() will set the
parent to the kset itself.
Just like for kobjects, we have kset_register()
that does kset_init(); kset_add(), and kset_unregister()
that just does kobject_unregister().
Finally, there is kset_find_obj() that given a name and
a kset returns the kobject in the kset with that name.
Both a kobject and a kset have a field of type struct kobj_type.
Such a struct represents a type of objects, and will hold the methods
used to operate on them. The definition is
Here the release function is what is called by kobject_cleanup().
It uses the ktype of the kset of the kobject, or, there is none,
the ktype of the kobject itself - this is what is returned by the method
get_ktype().
Method:
struct kobj_type *get_ktype(ko)
The attributes describe the ordinary files in the sysfs tree.
It is a NULL-terminated list of
A kset belongs to a subsystem, and the rwsem of the subsystem is
used to protect its list.
Subsystems tend to correspond to toplevel directories in the sysfs
hierarchy. Their names in the source tend to end in _subsys
(produced by the macro decl_subsys()).
I see
% ls /sys
block bus class devices firmware module
%
and find in the source system_subsys, block_subsys,
bus_subsys, class_subsys, devices_subsys,
firmware_subsys, class_obj_subsys, acpi_subsys,
edd_subsys, vars_subsys, efi_subsys,
cdev_subsys, module_subsys, power_subsys,
pci_hotplug_slots_subsys.
Here edd lives below firmware, and system
below devices.
Some are not visible in sysfs. We'll look at some of these below.
int kobj_map(struct kobj_map *domain, dev_t dev, unsigned long range,
struct module *owner, kobj_probe_t *get,
int (*lock)(dev_t, void *), void *data);
void kobj_unmap(struct kobj_map *domain, dev_t dev, unsigned long range);
struct kobject *kobj_lookup(struct kobj_map *domain, dev_t dev, int *index);
struct kobj_map *kobj_map_init(kobj_probe_t *base_probe, struct subsystem *s);
Each struct probe describes a device number interval
starting at dev and with length range.
With lots of devices one would need some fast data structure
to find stuff, but for the time being the current version suffices.
It uses the major device number mod 255 as index in the array,
where each entry is head in a linked list of such structs.
Handling the linked lists is protected by the semaphore *sem,
set to the subsystem semaphore at init time.
The call kobj_lookup() finds the given device number dev
on the given map domain (there are two: device numbers for
block devices and device numbers for character devices).
If the lock function is present it will be called,
and the present probe skipped if it returns an error.
Then the get function is called to get the kobject
for the given device number.
If the owner field is set, we take a reference on the
corresponding module via try_module_get(owner)
in order to protect the lock and get calls.
The resulting kobject is returned as value, and the offset in the
interval of device numbers is returned via index.
It is possible to have several nested intervals of device numbers,
and the lists are sorted such that smaller intervals come first
in the linked lists, so that the most specific entry overrides other entries.
The final entry is the interval [1,~0] covering all
device numbers.
The call kobj_map() adds an entry with the given data.
The call kobj_unmap() removes it again.
The call kobj_map_init() initializes the map.
The subsystem argument provides the semaphore.
The base_probe() parameter is the get function
for the interval covering all device numbers.
struct kobject *bbase_probe(dev_t dev, int *part, void *data) {
if (request_module("block-major-%d-%d", MAJOR(dev), MINOR(dev)) > 0)
request_module("block-major-%d", MAJOR(dev));
return NULL;
}
and
struct kobject *cbase_probe(dev_t dev, int *part, void *data) {
if (request_module("char-major-%d-%d", MAJOR(dev), MINOR(dev)) > 0)
request_module("char-major-%d", MAJOR(dev));
return NULL;
}
The existence of bdev_map is hidden
by the helper functions blk_register_region(),
blk_unregister_region(), get_gendisk()
that do a kobj_map(), kobj_unmap() and
kobj_lookup(), respectively.
Here disks[] is an array of struct gendisks,
one for each device. The alloc_disk() routine allocates one
and initializes some things. In particular, it sets the kset of the
embedded kobject to block_subsys.kset. Next,
Here exact_lock() takes a reference on disk, and
exact_match returns the kobject embedded in disk.
See how the data field is used here to store the disk
pointer.
The register_disk() copies the disk name disk->disk_name
(set above to e.g. "fd0") to disk->kobj.name,
replacing embedded slashes by exclamation marks, so that the name
is suitable as a file name. Then kobject_add() puts the
thing in the sysfs tree. Where? Below the subsys, that is, as
/sys/block/fd0, because that is where alloc_disk()
pointed us.
The blk_register_queue adds a subdirectory queue below
/sys/block/fd0.
One of the fields of a kset is a struct kset_hotplug_ops
defined by (in abbreviated notation)
struct kset_hotplug_ops {
int (*filter)(kset, kobj);
char *(*name)(kset, kobj);
int (*hotplug)(kset, kobj, char **envp, int num_envp, char *buf, int bufsz);
};
The routine kobject_hotplug() is called by
kobject_add() when the kobject is added to the
hierarchy. It needs a kset in order to call one of the
kset_hotplug_ops functions, and to this end walks up
the hierarchy along the parent pointers until a kobj is
found with a non-NULL kset. Then it calls
kset_hotplug(action, kset, orig_kobj).
Now kset_hotplug() first calls the filter function
if there is one, and does not do anything if that returns false.
It doesn't do anything either when hotplug_path is
the empty string.
(You can set hotplug_path by echoing to
/proc/sys/kernel/hotplug. The default value
is "/sbin/hotplug".)
Now the executable with pathname found in hotplug_path
is called with a single parameter, found by calling the name()
function, and if that doesnt yield a name, taking the name of the
(kobject of the) kset. The process gets an environment with
HOME=/, PATH=/sbin:/bin:/usr/sbin:/usr/bin,
ACTION=..., SEQNUM=..., DEVPATH=...,
where the path given by kobject_get_path() is the
path in the sysfs hierarchy to the kobj. Finally, the hotplug()
function may add some more environment parameters. Then the executable
is launched.

 LINUX
LINUX 
 Kernels
Kernels