David A Rusling : Файловые системы
1999 г.
Одним из главных преимуществ линукса является поддержка различных типов файловых систем.
Эта гибкость позволяет линуксу мирно сосуществовать с другими операционными системами.
На момент написания этой статьи линукс поддерживал 15 типов файловых систем : ext, ext2, xia,
minix, umsdos, msdos, vfat, proc, smb, ncp, iso9660,
sysv, hpfs, affs и ufs.
В линуксе различные файловые системы обьединены в единую иерархическую древовидную структуру.
Линукс добавляет каждую новую файловую систему в единое дерево на этапе монтирования.
Каждая файловая система монтируется в точку , известную как mount directory.
Диск состоит из партиций.
Каждая партиция может хранить только одну файловую систему , например EXT2.
Файловые системы хранят файлы в иерархической структуре каталогов ,
все это лежит в виде блоков на физических носителях.
Устройства , которые хранят файловые системы , известны как блочные устройства.
Например , партиция /dev/hda1, первавя партиция на первом IDE диске ,
является блочным устройством.
Файловая система обращается с ними как с линейной коллекцией,
не догадываясь о физической геометрии диска.
Драйвер непосредственно обращается к треку , сектору , цилиндру жесткого диска.
Файловую систему не должно волновать , какая физическая природа у физического носителя.
Различные файловые системы при этом могут быть расположены вообще на различных
физических носителях и обслуживаться различными контролерами.
Файловая система вообще может быть не расположена локально на компьютере.
Рассмотрим пример , в котором рутовая файловая система расположена на SCSI диске :
A E boot etc lib opt tmp usr
C F cdrom fd proc root var sbin
D bin dev home mnt lost+found
/C - это файловая система VFAT , расположенная на первом IDE диске.
/E - мастер - IDE диск на second IDE .
Не имеет никакого значения , что первый IDE контроллер - это PCI контролер и что
второй контролер - ISA контролер , который также контролирует IDE CDROM.
Удаленно с помощью модема примонтирована Alpha AXP файловая система
как /mnt/remote.
Файлы - это колекция данных.
Файловая система хранит не только эти данные , но и собственную структуру ,
включая информацию о защите файла . Это должен быть абсолютно надежный
и прозрачный механизм .
Никому не нужна файловая система , которая будет терять данные и файлы.
Первой файловой системой в юниксе был Minix,
который был ограничен и непроизводителен.
Его файловые имена не могли быть длиннее 14 символов и максимальный размер файла был
64 метра.
Первая файловая система , разработанная специально под линукс , была
Extended File system, или EXT, она появилась в апреле 1992 ,
и имела массу проблем.
В 1993 появилась Second Extended File - EXT2.
Ее-то мы и рассмотрим.
EXT отделила сервисы файловой системы от собственно операционной системы ,
выделив их в отдельный слой - VFS - или Virtual File system.
VFS позволяет линуксу поддерживать множество различных файловых систем.
Благодаря чему они имеют одинаковое поведение в ядре и программном окружении.
VFS позволяет прозрачно монтировать различные типы файловых систем одновременно.
VFS реализована так , что доступ к файлам происходит максимально быстро и эффективно.
VFS кеширует информацию о файловой системе на этапе монтирования и в дальнейшем
использует этот кеш.
При создании , модификации и удалении каталогов и файлов этот кеш должен корректно обновляться.
Важнейшей частью этого кеша является буфер - Buffer Cache,
который обеспечивает доступ к соответствующим блочным устройствам.
Когда происходят операции с физическими блоками , информация об этом обновляется прежде всего
в этом кеше и хранится в кешовых очередях - queues - в зависимости от состояния блоков.
Кроме функции хранения информации , кеш помогает в управлении асинхронного механизма
блочных устройств.
The Second Extended File system (EXT2)
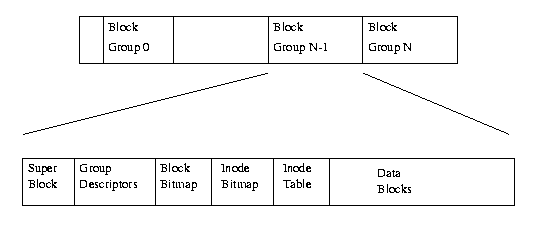
Figure 9.1: Physical Layout of the EXT2 File system
ext2 была разработана R.Card.
Она является базовой файловой системой для всех основных линуксовых дистрибутивов.
Данные хранятся в блоках.
Блоки имеют одинаковую длину , эта длина может задаваться во время создания файловой системы
с помощью утилиты mke2fs.
Каждый файл занимает целое число таких блоков.
Если например размер блока 1024 байт , а размер файла 1025 байт , то этот файл будет занимать 2 блока.
Это означает , что блоковая модель ведет к неизбежным потерям пространства на диске.
Но на это естественно все закрывают глаза.
Блоки заняты не только хранением данных , они также хранят информацию о структуре самой файловой системы.
Топология файловой системы EXT2 построена на основе ноды - inode.
Нода определяет блоки , которые отведены под хранение данного файла ,
а также его права , время модификации и тип файла.Каждый файл описывается одной нодой
и каждая нода имеет свой номер-идентификатор.Ноды хранятся в нодовых таблицах.
Директория - специальный файл , который включает указатели на ноды вложенных подкаталогов.
Рисунок 9.1
показывает EXT2 как последовательность блоков в устройстве.
Блочное устройство - последовательность блоков , которые могут быть прочитаны и перезаписаны.
Файловая система ничего не знает о физическом блочном слое , это работа драйвера.
Когда файловой системе нужно прочитать данные , она делает запрос драйверу ,
и тот считывает n-ное количество блоков.
EXT2 разбивает партицию на группы блоков.
Каждая группа дублирует информацию , критическую для целостности файловой системы.
Это дублирование необходимо в случае аварии и последующего восстановления.
Нода в EXT2
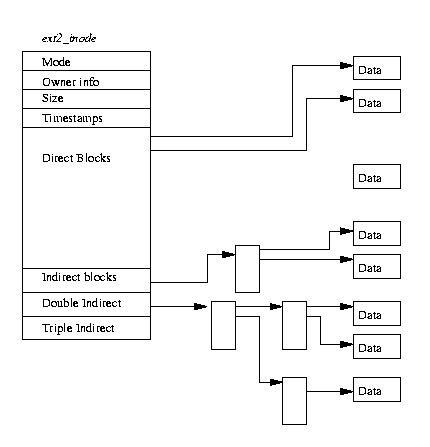
Figure 9.2: EXT2 нода
В EXT2 нода является кирпичиком всего и вся : каждый файл и каждая директория
описываются одной и только одной нодой.
Ноды каждой группы блоков хранятся в своей таблице вместе с битмапом ,
битмап хранит список выделенных и свободных нод.
Рисунок 9.2 показывает формат ноды,
в ней имеются следующие поля:
- mode
-
В этом поле хранится тип ноды и права.
Под типом понимается : файл , директория , линк , блочное устройство , символьное устройство , FIFO.
- Информация о хозяине
-
Это пользователь и группа , они необходимы файловой системе для раздачи прав доступа.
- Размер
- Размер файла в байтах,
- Время
-
Время создания и время последней модификации.
- Datablocks
-
Указатели на блоки данных. Первые 12 указывают на блоки данных напрямую ,
последние три являются более сложными указателями на указатели.
Это значит , что если файл имеет размер в блоках <= 12 , то доступ к этому файлу
и его данным будет быстрее , чем к файлам бОльшего размера.
Обратите внимание , что ноды могут описывать специальные файлы устройств.
Это не реальные файлы , а хэндлы , которые программы могут использовать
для доступа к устройствам. Речь , как вы уже поняли , идет о каталоге /dev .
Например утилита mount
в качестве аргумента имеет файл именно такого типа.
В суперблоке хранится информация о размере файловой системы.
В каждой группе блоков имеется дубликат супер-блока - на всякий пожарный ,
но при монтировании считывается только один суперблок ,
который лежит в группе с индексом 0.
В суперблоке хранится следующее :
- Magic Number
-
Специальное число , именно для EXT2 на момент написания оно было равно
0xEF53.
- Revision Level
-
Указывает на дополнительные фичи файловой системы ,
которые могут быть использованы на этапе ее монтирования.
- Mount Count или Maximum Mount Count
-
Контрольное число , необходимое для проверки.
Каждый раз при монтировании это число увеличивается и когда оно становится максимальным ,
запускается либо предлагается запустить e2fsck,
- Block Group Number
-
Номер группы блока , в которой хранится данный суперблок
- Block Size
-
Размер блока файловой системы , например 1024 байта,
- Blocks per Group
-
Число блоков в группе , фиксируется в момент создания файловой системы.
- Free Blocks
-
Число свободных блоков
- Free Inodes
-
Число свободных нод
- First Inode
-
Номер первой ноды в файловой системе.
Например , номер ноды , соответсвующей корневому каталогу '/' .
EXT2 Group Descriptor
Каждая группа блоков имеет специальную структуру.
Подобно суперблоку , все групповые дескрипторы дублируются в каждой группе блоков.
В таком дескрипторе хранится следующая информация :
- Blocks Bitmap
-
Номер блока , в котором лежит битмап.
Битмап используется при выделении блоков.
- Inode Bitmap
-
У нод , как и у блоков , имеется свой собственный битмап.
тут хранится номер блока , в котором хранится этот битмап.
- Inode Table
-
Номер блока , в котором начинается таблица нод.
- Free blocks count, Free Inodes count, Used directory count
-
Групповые дескрипторы размещены в конце каждой группы блоков в таблице дескрипторов -
опять же это пример избыточности во имя надежности.
Эта таблица лежит после копии суперблока.
А фактически же используется только копия этой таблицы в группе блоков с индексом 0.
EXT2 Directories
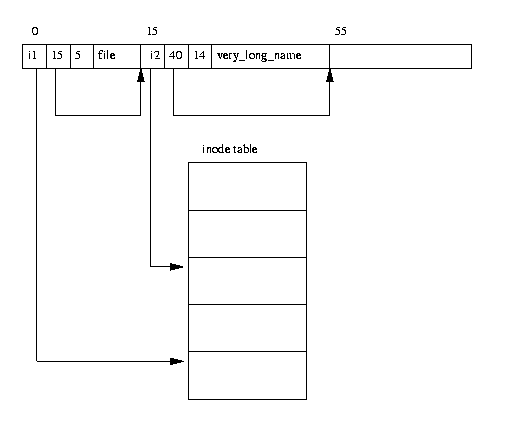
Figure 9.3: EXT2 Directory
Директория - это специальный файл , который используется для создания пути к файлу.
Рисунок 9.3 показывает директорию в памяти.
Директория включает следующую информацию :
- inode
-
Индекс ноды в нодовой таблице данной группы блоков.
На рисунке 9.3,
директория file имеет ссылку на нодовый номер i1,
- name length
-
Длина имени директории в байтах,
- name
- Имя директории.
Первые две строчки для любой директории всегда стандартные
``.'' и ``..'' , которые означают - текущий каталог и родительский каталог.
Поиск файла в EXT2
Имя файла в линуксе имеет такой же формат , как и юникс TM .
Это набор каталогов , разделенных слешом - ``/'') - и в конце
собственно само имя.
Например /home/rusling/.cshrc где /home и /rusling
- каталоги плюс имя файла .cshrc.
Длина имени может быть произвольной .
Для нахождения ноды , представляющей данный файл , файловая система должна отпарсить
его директорию .
Первая нода , которая нам понадобится - это рутовая нода ,
ее номер можно найти в суперблоке.
Для чтения ноды понадобится нодовая таблица соответствующей группы блоков.
Например , если рутовая нода имеет номер 42,
то нам понадобится 42-я нода из нодовой таблицы группы блоков с номером 0.
Рутовая нода включает всю необходимую информацию о рутовом каталоге.
home - еще один каталог внутри рутового каталога ,
который дает номер ноды для каталога /home.
С помощью этой ноды мы находим другой каталог -
rusling , который дает нам ноду , описывающую каталог /home/rusling.
И наконец в ноде , описывающей каталог /home/rusling ,
мы находим нодовый номер файла .cshrc и из этой ноды
получаем блоки , включающие информацию об этом файле.
Изменение размера файла в EXT2
Одна из основных проблем файловой системы - фрагментация.
Блоки , которые хранят данные файла , имеют тенденцию расползаться по всей файловой системе ,
что снижает эффективность доступа к файлу.
EXT2 борется с этим путем выделения новых блоков для файла физически непосредственно
за текущими в той же самой группе блоков.
Выделение блоков в другой блоковой группе делается в крайнем случае.
При записи в файл файловая система всегда пытается это сделать в выделенную область ,
близлежащую к концу файла.
Первая вещь , которая делается при этом - блокируется суперблок.
Любое изменение любого файла изменяет структуру суперблока ,
и одновременно может быть только один такой процесс.
Другому процессу прийдется подождать.
При этом всегда происходит проверка на достаточное количество свободных блоков
в файловой системе , в противном случае сработает исключение.
Если блоков достаточно , происходит их выделение.
При этом EXT2 проверяет - есть ли свободные блоки - preallocate data blocks - в битмапе.
В файловой ноде EXT2 имеются специальные поля :
prealloc_block и prealloc_count,
первое поле является первым свободным -preallocated- номером блока ,
второе поле показывает число таких блоков в битмапе.
Если в битмапе таких блоков нет , EXT2 должна выделить новый блок.
EXT2 первым делом смотрит в конец модифицируемого файла и ищет там свободные блоки.
Если первый же блок после окончания этого файла несвободен ,
проверяются следующие 64 блока.
Если и эти блоки заняты , поиски продолжаются в других блоковых группах.
Ищутся группы по 8 блоков.Если не находит , ищутся еще более маленькие группы.
После нахождения поля prealloc_block и prealloc_count модифицируются .
При нахождении свободных блоков битмап данной группы блоков будет модифицирован ,
а также выделен буфер в кеше.
Данные в буфере обнуляются и буфер маркируется как ``dirty''
для того , чтобы показать , что его содержимое еще не записано на диск.
Суперблок маркируется как ``dirty'' и разблокируется.
Если в это время сформировалась очередь запросов к суперблоку ,
первому будет позволено работать с суперблоком.
Выделяются новые блоки и т.д.
Virtual File System (VFS)
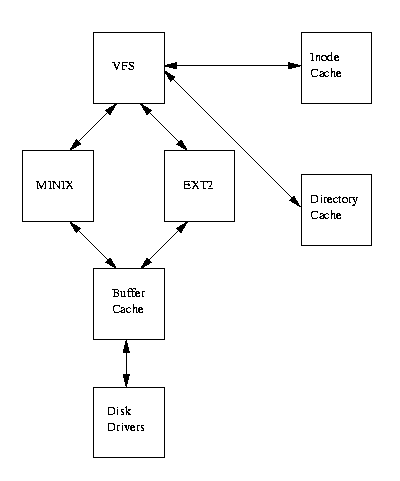
Figure 9.4: Логическая диаграмма Virtual File System
Рисунок 9.4
показывает связь между Virtual File System ядра и реальной файловой системой.
VFS должна управлять всеми типами файловых систем , которые примонтированы в данное время.
VFS оперирует теми же обьектами , что и EXT2.
Ноды в VFS описывают файлы и каталоги.
Далее мы будем оперировать суперблоками и нодами применительно к VFS.
Каждая файловая система при инициализации регистрирует себя с помощью VFS.
Это происходит во время загрузки операционной системы.
Файловая система может быть встроенной в ядро либо находиться в загружаемом модуле.
Если файловая система находится в модуле , этот модуль подгружается в момент ее монтирования.
При монтировании файловой системы VFS должна прочитать ее суперблок.
VFS хранит список примонтированных файловых систем вместе с их суперблоками.
В каждом таком суперблоке , который хранится внутри VFS , находятся указатели на различные функции.
Например , суперблок EXT2 включает указатель на процедуру чтения нод.
Эта процедура будет заполнять поля уже в ноде , которая принадлежит VFS.
В каждом суперблоке VFS есть указатель на первую ноду VFS для файловой системы.
Для рута эта нода представлена каталогом ``/''.
Набирая ls для каталога или cat ,
будет спровоцирован поиск среди нод VFS .
Каждый файл представлен нодой в VFS , которая имеет свой номер.
Эти ноды хранятся в кеше , что ускоряет поиск.
Если ноды в кеше нет , вызывается процедура для ее чтения.
Прочитанная нода ложится в кеш
Неиспользуемые ноды из кеша удаляются.
Все файловые системы используют кеш для ускорения доступа к физической файловой системе.
Этот кеш независим от типа файловой системы и интегрирован в механизм ядра.
Поэтому файловая система не зависит от драйвера , который ее поддерживает.
Блочные устройства регистрируются в ядре и имеют асинхронный интерфейс ,
в том числе такие как SCSI драйвера.
Когда файловая система читает данные ,
она посылает запрос блочным устройствам для чтения физических блоков на диске.
Интеграция с блочным устройством происходит через кеш.
Прочитанные блоки записываются в глобальный кеш , расшареный между всеми файловыми системами.
Идентификация происходит с помощью номера блока и идентификатора устройства.
Часто используемые данные будут браться из кеша , а не с диска.
VFS хранит также кеш каталогов для работы с наиболее часто используемыми директориями.
В качестве эксперимента попробуйте пролистать директорию , которую вы еще не листали.
Последующий листинг будет происходить намного быстрее первого.
VFS Superblock
Каждая примонтированная файловая система представлена в VFS суперблоком,
который хранит следующую информацию :
- Device
-
Идентификатор блочного устройства , например /dev/hda1, или
первый IDE hard disk , имеет идентификатор 0x301,
- Inode pointers
-
Указывает на первую ноду файловой системы .
Суперблок рутовой файловой системы не имеет такого указателя.
- Blocksize
-
Размер блока в байтах например 1024 байт,
- Superblock operations
-
Указатель на функции суперблока , такие , как чтение и запись нод и суперблока.
- File System type
-
Указатель на структуру file_system_type
- File System specific
-
Указатель на специфическую информацию
Нода VFS
Аналогично EXT2 , каждый файл и каталог в VFS представлен одной и только одной нодой.
VFS нода берет свою информацию из файловых систем с помощью специальных функций.
Нода VFS существует только в памяти ядра и хранится в кеше VFS столько , сколько нужно.
Нода VFS включает следующие поля :
- device
-
Идентификатор устройства
- inode number
-
Уникальный номер ноды
Комбинация device и inode number уникальна внутри Virtual File System,
- mode
-
права доступа
- user ids
- идентификатор собственника,
- times
- время создания , модификации,
- block size
- размер блока в байтах,
- inode operations
-
указатель на блоковые функции
- count
-
Чило компонентов системы , которые используют данную ноду в данный момент.
Число ноль означает . что нода свободна.
- lock
-
Блокирует ноду , например при ее чтении
- dirty
-
пометка на ноде при ее модификации
- file system specific information
-
Регистрация файловой системы
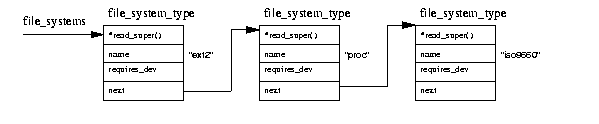
Figure 9.5: Registered File Systems
When you build the Linux kernel you are asked if you want each of the supported
file systems.
When the kernel is built, the file system startup code contains calls to
the initialisation routines of all of the built in file systems.
Linux file systems may also be built as modules and, in this case, they may
be demand loaded as they are needed or loaded by hand using insmod.
Whenever a file system module is loaded it registers itself with the kernel and unregisters
itself when it is unloaded.
Each file system's initialisation routine registers itself with the Virtual File System
and is represented by a file_system_type data structure
which contains the name
of the file system and a pointer to its VFS superblock read routine.
Figure 9.5 shows that the file_system_type data structures
are put into a list pointed at by the file_systems pointer.
Each file_system_type data structure contains the following information:
- Superblock read routine
- This routine is called by the VFS when an
instance of the file system is mounted,
- File System name
- The name of this file system, for example ext2,
- Device needed
- Does this file system need a device to support? Not all
file system need a device to hold them. The /proc file system,
for example, does not require a block device,
You can see which file systems are registered by looking in at /proc/filesystems.
For example:
ext2
nodev proc
iso9660
9.2.4 Mounting a File System
When the superuser attempts to mount a file system, the Linux kernel must
first validate the arguments passed in the system call.
Although mount does some basic checking, it does not know which file systems
this kernel has been built to support or that the proposed mount point actually
exists.
Consider the following mount command:
$ mount -t iso9660 -o ro /dev/cdrom /mnt/cdrom
This mount command will pass the kernel three pieces of information; the name of
the file system, the physical block device that contains the file system and, thirdly,
where in the existing file system topology the new file system is to be mounted.
The first thing that the Virtual File System must do is to find the file system.
To do this it searches through the list of known file systems by looking at each
file_system_type data structure in the list pointed at by file_systems.
If it finds a matching name it now knows that this file system type is supported
by this kernel and it has the address of the file system specific routine for
reading this file system's superblock.
If it cannot find a matching file system name then all is not lost if the kernel
is built to demand load kernel modules (see Chapter modules-chapter).
In this case the kernel will request that the kernel daemon loads the appropriate
file system module before continuing as before.
Next if the physical device passed by mount is not already mounted,
it must find the VFS inode of the directory that is to be the new file system's
mount point.
This VFS inode may be in the inode cache or it might have to be read from the
block device supporting the file system of the mount point.
Once the inode has been found it is checked to see that it is a directory
and that there is not already some other file system mounted there.
The same directory cannot be used as a mount point for more than one file system.
At this point the VFS mount code must allocate a VFS superblock and
pass it the mount information to the superblock read routine for this
file system.
All of the system's VFS superblocks are kept in the super_blocks vector
of super_block data structures and one must be allocated for this mount.
The superblock read routine must fill out the VFS superblock fields based on
information that it reads from the physical device.
For the EXT2 file system this mapping or translation of information is quite
easy, it simply reads the EXT2 superblock and fills out the VFS superblock from there.
For other file systems, such as the MS DOS file system, it is not quite such
an easy task.
Whatever the file system, filling out the VFS superblock means that the file system
must read whatever describes it from the block device that supports it.
If the block device cannot be read from or if it does not contain this type of
file system then the mount command will fail.
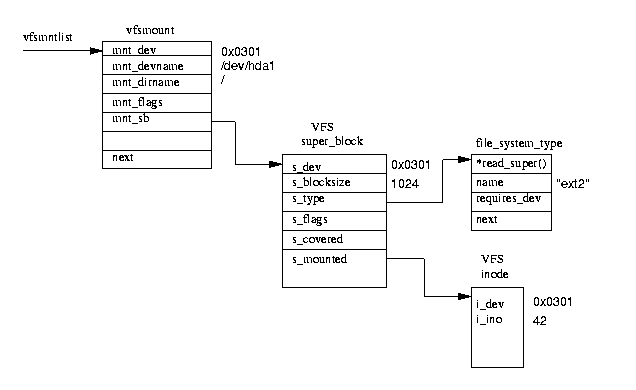
Figure 9.6: A Mounted File System
Each mounted file system is described by a vfsmount data structure;
see figure 9.6.
These are queued on a list pointed at by vfsmntlist.
Another pointer, vfsmnttail points at the last entry in the list and
the mru_vfsmnt pointer points at the most recently used file system.
Each vfsmount structure contains the device number of the block device
holding the file system, the directory where this file system is mounted and a
pointer to the VFS superblock allocated when this file system was mounted.
In turn the VFS superblock points at the file_system_type data structure
for this sort of file system and to the root inode for this file system.
This inode is kept resident in the VFS inode cache all of the time that
this file system is loaded.
9.2.5 Finding a File in the Virtual File System
To find the VFS inode of a file in the Virtual File System, VFS must resolve the
name a directory at a time, looking up the VFS inode representing each of the
intermediate directories in the name.
Each directory lookup involves calling the file system specific lookup whose address
is held in the VFS inode representing the parent directory.
This works because we always have the VFS inode of the root of each file system
available and pointed at by the VFS superblock for that system.
Each time an inode is looked up by the real file system it checks the directory
cache for the directory.
If there is no entry in the directory cache, the real file system gets the VFS
inode either from the underlying file system or from the inode cache.
9.2.6 Creating a File in the Virtual File System
9.2.7 Unmounting a File System
The workshop manual for my MG usually describes assembly as the reverse of
disassembly and the reverse is more or less true for unmounting a file system.
A file system cannot be unmounted if something in the system is using one of its
files.
So, for example, you cannot umount /mnt/cdrom if a process is using that
directory or any of its children.
If anything is using the file system to be unmounted there may be VFS inodes
from it in the VFS inode cache, and the code checks for this by looking through
the list of inodes looking for inodes owned by the device that this file system
occupies.
If the VFS superblock for the mounted file system is dirty, that is it has
been modified, then it must be written back to the file system on disk.
Once it has been written to disk, the memory occupied by the VFS superblock
is returned to the kernel's free pool of memory.
Finally the vfsmount data structure for this mount is unlinked from
vfsmntlist and freed.
9.2.8 The VFS Inode Cache
As the mounted file systems are navigated, their VFS inodes are being continually
read and, in some cases, written.
The Virtual File System maintains an inode cache to speed up accesses to all of
the mounted file systems.
Every time a VFS inode is read from the inode cache the system saves an access to
a physical device.
The VFS inode cache is implmented as a hash table whose entries are pointers to
lists of VFS inodes that have the same hash value.
The hash value of an inode is calculated from its inode number and from the device
identifier for the underlying physical device containing the file system.
Whenever the Virtual File System needs to access an inode, it first looks in the
VFS inode cache.
To find an inode in the cache, the system first calculates its hash value and then uses
it as an index into the inode hash table.
This gives it a pointer to a list of inodes with the same hash value.
It then reads each inode in turn until it finds one with both the same inode
number and the same device identifier as the one that it is searching for.
If it can find the inode in the cache, its count is incremented to show that it
has another user and the file system access continues.
Otherwise a free VFS inode must be found so that the file system can read the
inode from memory.
VFS has a number of choices about how to get a free inode.
If the system may allocate more VFS inodes then this is what it does; it
allocates kernel pages and breaks them up into new, free, inodes and puts them
into the inode list.
All of the system's VFS inodes are in a list pointed at by first_inode as well
as in the inode hash table.
If the system already has all of the inodes that it is allowed to have, it must
find an inode that is a good candidate to be reused.
Good candidates are inodes with a usage count of zero; this indicates that the
system is not currently using them.
Really important VFS inodes, for example the root inodes of file systems always have
a usage count greater than zero and so are never candidates for reuse.
Once a candidate for reuse has been located it is cleaned up.
The VFS inode might be dirty and in this case it needs to be written back to the file system
or it might be locked and in this case the system must wait for it to be unlocked before
continuing.
The candidate VFS inode must be cleaned up before it can be reused.
However the new VFS inode is found, a file system specific routine must be called
to fill it out from information read from the underlying real file system.
Whilst it is being filled out, the new VFS inode has a usage count of one and is
locked so that nothing else accesses it until it contains valid information.
To get the VFS inode that is actually needed, the file system may need to access
several other inodes.
This happens when you read a directory; only the inode for the final directory is
needed but the inodes for the intermediate directories must also be read.
As the VFS inode cache is used and filled up, the less used inodes will be discarded
and the more used inodes will remain in the cache.
9.2.9 The Directory Cache
To speed up accesses to commonly used directories, the VFS maintains a cache of
directory entries.
As directories are looked up by the real file systems their details are added into
the directory cache.
The next time the same directory is looked up, for example to list it or open a
file within it, then it will be found in the directory cache.
Only short directory entries (up to 15 characters long) are cached but this is
reasonable as the shorter directory names are the most commonly used ones.
For example, /usr/X11R6/bin is very commonly accessed when the X server is
running.
The directory cache consists of a hash table, each entry of which points at
a list of directory cache entries that have the same hash value.
The hash function uses the device number of the device holding the file system and
the directory's name to calculate the offset, or index, into the hash table.
It allows cached directory entries to be quickly found.
It is no use having a cache when lookups within the cache take too long to find entries,
or even not to find them.
In an effort to keep the caches valid and up to date the VFS keeps lists of
Least Recently Used (LRU) directory cache entries.
When a directory entry is first put into the cache, which is when it is first
looked up, it is added onto the end of the first level LRU list.
In a full cache this will displace an existing entry from the front of the
LRU list.
As the directory entry is accessed again it is promoted to the back of the
second LRU cache list.
Again, this may displace a cached level two directory entry at the front of
the level two LRU cache list.
This displacing of entries at the front of the level one and level two LRU lists
is fine.
The only reason that entries are at the front of the lists is that they have not
been recently accessed.
If they had, they would be nearer the back of the lists.
The entries in the second level LRU cache list are safer than entries in the level one
LRU cache list.
This is the intention as these entries have not only been looked up but also
they have been repeatedly referenced.
REVIEW NOTE: Do we need a diagram for this?
9.3 The Buffer Cache
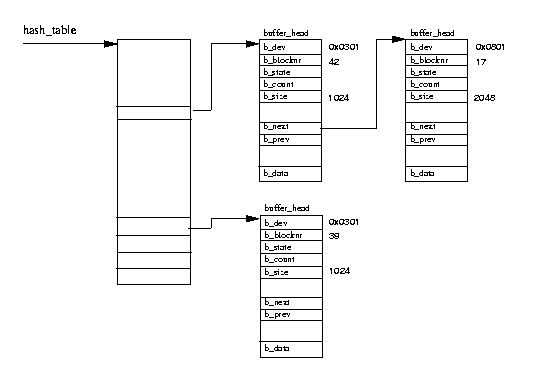
Figure 9.7: The Buffer Cache
As the mounted file systems are used they generate a lot of requests to the block
devices to read and write data blocks.
All block data read and write requests are given to the device drivers in the form
of buffer_head data structures via standard kernel routine calls.
These give all of the information that the block device drivers need; the device
identifier uniquely identifies the device and the block number tells the driver
which block to read.
All block devices are viewed as linear collections of blocks of the same size.
To speed up access to the physical block devices, Linux maintains a cache of block
buffers.
All of the block buffers in the system are kept somewhere in this buffer cache, even
the new, unused buffers.
This cache is shared between all of the physical block devices; at any one time
there are many block buffers in the cache, belonging to any one of the system's
block devices and often in many different states.
If valid data is available from the buffer cache this saves the system
an access to a physical device.
Any block buffer that has been used to read data from a block device or to write data
to it goes into the buffer cache.
Over time it may be removed from the cache to make way for a more deserving
buffer or it may remain in the cache as it is frequently accessed.
Block buffers within the cache are uniquely identfied by the owning device
identifier and the block number of the buffer.
The buffer cache is composed of two functional parts.
The first part is the lists of free block buffers.
There is one list per supported buffer size and the system's free block buffers
are queued onto these lists when they are first created or when they have been
discarded.
The currently supported buffer sizes are 512, 1024, 2048, 4096 and 8192 bytes.
The second functional part is the cache itself.
This is a hash table which is a vector of pointers to chains of buffers that have
the same hash index.
The hash index is generated from the owning device identifier and the block number
of the data block.
Figure 9.7 shows the hash table together with a few entries.
Block buffers are either in one of the free lists or they are in the buffer cache.
When they are in the buffer cache they are also queued onto Least Recently Used
(LRU) lists.
There is an LRU list for each buffer type and
these are used by the system to perform work on buffers of a type, for example, writing
buffers with new data in them out to disk.
The buffer's type reflects its state and Linux currently supports the following types:
- clean
- Unused, new buffers,
- locked
- Buffers that are locked, waiting to be written,
- dirty
- Dirty buffers. These contain new, valid data, and will be written
but so far have not been scheduled to write,
- shared
- Shared buffers,
- unshared
- Buffers that were once shared but which are now not shared,
Whenever a file system needs to read a buffer from its underlying physical
device, it trys to get a block from the buffer cache.
If it cannot get a buffer from the buffer cache, then it will get a clean one from
the appropriate sized free list and this new buffer will go into the buffer cache.
If the buffer that it needed is in the buffer cache, then it may or may not be up to
date.
If it is not up to date or if it is a new block buffer, the file system must request
that the device driver read the appropriate block of data from the disk.
Like all caches, the buffer cache must be maintained so that it runs efficiently
and fairly allocates cache entries between the block devices using the buffer
cache.
Linux uses the bdflush
kernel daemon to perform a lot of housekeeping duties
on the cache but some happen automatically as a result of the cache being used.
9.3.1 The bdflush Kernel Daemon
The bdflush kernel daemon is a simple kernel daemon that provides a dynamic
response to the system having too many dirty buffers; buffers that contain data
that must be written out to disk at some time.
It is started as a kernel thread at system startup time and, rather confusingly,
it calls itself ``kflushd'' and that is the name that you will see if you use
the ps command to show the processes in the system.
Mostly this daemon sleeps waiting for the number of dirty buffers in the
system to grow too large.
As buffers are allocated and discarded the number of dirty buffers in the system
is checked.
If there are too many as a percentage of the total number of buffers in the system then
bdflush is woken up.
The default threshold is 60% but, if the system is desperate for buffers, bdflush
will be woken up anyway.
This value can be seen and changed using the update command:
# update -d
bdflush version 1.4
0: 60 Max fraction of LRU list to examine for dirty blocks
1: 500 Max number of dirty blocks to write each time bdflush activated
2: 64 Num of clean buffers to be loaded onto free list by refill_freelist
3: 256 Dirty block threshold for activating bdflush in refill_freelist
4: 15 Percentage of cache to scan for free clusters
5: 3000 Time for data buffers to age before flushing
6: 500 Time for non-data (dir, bitmap, etc) buffers to age before flushing
7: 1884 Time buffer cache load average constant
8: 2 LAV ratio (used to determine threshold for buffer fratricide).
All of the dirty buffers are linked into the BUF_DIRTY LRU list whenever they
are made dirty by having data written to them and bdflush tries to write a
reasonable number of them out to their owning disks.
Again this number can be seen and controlled by the update command and the
default is 500 (see above).
9.3.2 The update Process
The update command is more than just a command; it is also a daemon.
When run as superuser (during system initialisation) it will periodically flush
all of the older dirty buffers out to disk.
It does this by calling a system service routine
that does more or less the same thing
as bdflush.
Whenever a dirty buffer is finished with, it is tagged with the system time that
it should be written out to its owning disk.
Every time that update runs it looks at all of the dirty buffers in the system
looking for ones with an expired flush time.
Every expired buffer is written out to disk.
9.4 The /proc File System
The /proc file system really shows the power of the Linux Virtual File System.
It does not really exist (yet another of Linux's conjuring tricks), neither
the /proc directory nor its subdirectories and its files actually exist.
So how can you cat /proc/devices?
The /proc file system, like a real file system, registers itself with the
Virtual File System.
However, when the VFS makes calls to it requesting inodes as its files and
directories are opened, the /proc file system creates those files and
directories from information within the kernel.
For example, the kernel's /proc/devices file is generated from the kernel's
data structures describing its devices.
The /proc file system presents a user readable window into the kernel's
inner workings.
Several Linux subsystems, such as Linux kernel modules described in
chapter modules-chapter, create entries in the the /proc file system.
9.5 Device Special Files
Linux, like all versions of Unix TM presents its hardware devices as special files.
So, for example, /dev/null is the null device.
A device file does not use any data space in the file system, it is only an access
point to the device driver.
The EXT2 file system and the Linux VFS both implement device files as special types of
inode.
There are two types of device file; character and block special files.
Within the kernel itself, the device drivers implement file semantices: you can open them,
close them and so on.
Character devices allow I/O operations in character mode and block devices require
that all I/O is via the buffer cache.
When an I/O request is made to a device file, it is forwarded to the appropriate
device driver within the system.
Often this is not a real device driver but a pseudo-device driver for some subsystem such
as the SCSI device driver layer.
Device files are referenced by a major number, which identifies the device type, and a
minor type, which identifies the unit, or instance of that major type.
For example, the IDE disks on the first IDE controller in the system
have a major number of 3 and the first partition of an
IDE disk would have a minor number of 1. So, ls -l of /dev/hda1 gives:
$ brw-rw---- 1 root disk 3, 1 Nov 24 15:09 /dev/hda1
Within the kernel, every device is uniquely described by a kdev_t data type, this
is two bytes long, the first byte containing the minor device number and the second
byte holding the major device number.
The IDE device above is held within the kernel as 0x0301.
An EXT2 inode that represents a block or character device keeps the device's major
and minor numbers in its first direct block pointer.
When it is read by the VFS, the VFS inode data structure representing it has its i_rdev
field set to the correct device identifier.
|

 LINUX
LINUX 
 Kernels
Kernels
