Автоматическое выделение памяти
Менеджеры автоматического выделения памяти освобождают программиста
от ответственности за содеянное.
Они делают жизнь программистов легче.
Они позволяют избегать таких проблем,как утечка памяти и подвисшие указатели.
Обратной стороной таких менеджеров является сложность их внутреннего устройства.
| Note |
Под такими менеджерами часто понимают garbage collectors.
Блок памяти,динамически выделенный программой,на которую никто не ссылается,
является мусором-garbage.
garbage collector как раз и занимается очисткой подобного рода мусора.
|
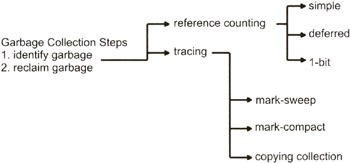
Сборщик мусора
Сборщики различаются по своим механизмам работы.
Например,мусор может быть обнаружен с помощью ссылочной связи либо трэйсинга.
Большинство сборщиков используют эти два метода.
Ссылочный механизм собирает мусор путем коллекционирования указателей на выделяемую память.
Когда число ссылок на выделенный блок памяти становится равным нулю,он маркируется как мусор.
Существуют различные ссылочные механизмы
(simple reference counting, deferred reference counting, 1-bit reference counting).
Второй тип мусорщиков трэйсит такие параметры программ,как регистры,стек,секцию данных
в поисках указателей на выделенную память.
Если найден указатель,который указывает на выделенную область памяти,
то такая память считается "живой".
Такие сборщики разделяются на mark-sweep, mark-compact, copying garbage .
Различные подходы в автоматическом управлении памятью Figure 5.1.
В том разделе будет реализованы сборщики обоих типов.
Они будут построены на основе библиотечных функций malloc() и free().
malloc() Версия 4: Reference Counting
Теория
The reference count approach keeps track of the number of pointers that hold the address of a given block of memory. The reference count of a block of memory is incremented every time that its address is assigned or copied to another pointer. The reference count of a memory block is decremented when a pointer holding its address is overwritten, goes out of scope, or is recycled. When the reference count reaches a value of zero, the corresponding memory is reclaimed.
Consider the following short program:
Each reference increment and decrement has been marked with a comment to give you an idea of what would need to be done behind the scenes.
The one line:
increments the reference count to memory_block_2 because its address is being copied into cptr2. On the other hand, the reference count to memory_block_1 is decremented because its address in cptr2 is being overwritten.
Reference counting is a technique that requires the cooperation of the compiler. Specifically, the compiler will need to recognize when it is necessary to increment or decrement a reference count and emit special code to do the job. For example, normally, the native code generated for:
would resemble something like:
However, because the reference count to memory_block_1 needs to be maintained, the compiler will need to generate something like:
Likewise, when a pointer goes out of scope or is overwritten, the compiler will need to emit something that looks like:
| Note |
The alternative to emitting extra instructions to perform the reference counting is to use an interpreter, or virtual machine, which can keep pointer tallies without help from the compiler.
|
Implementation
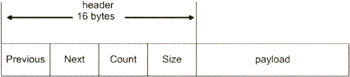
I decided to implement a reference counting garbage collector by modifying the sequential fit implementation in Chapter 4. As with the sequential fit approach, memory is arranged as a series of blocks where each block is prefixed by a 16-byte header (see Figure 5.2).
The STATE field, which was a byte in the sequential fit implementation, has been replaced by a 32-bit field called COUNT. This COUNT field keeps track of the number of references to a block of memory.
My implementation of the reference counting memory manager required four files:
Table 5.1
|
File
|
Use
|
|
driver.cpp
|
contains main(), is the scene of the crime
|
|
mallocV4.cpp
|
newMalloc(), newFree() wrappers (4th version)
|
|
perform.cpp
|
implements the PerformanceTest class
|
|
memmgr.cpp
|
implements the RefCountMemoryManager class
|
driver.cpp
This file contains the main() entry point. You can build my implementation to execute a diagnostic test or a performance test. To build the diagnostic version, you will need to comment out the PerformanceTestDriver() invocation and uncomment the debugTest() invocation. You will also need to activate the DEBUG_XXX macros in the mallocV4.cpp file.
Because the compiler that I used has not been engineered to emit the extra instructions needed to support reference counting, I had to manually insert the code. Throughout debugTest(), I added inc() and dec() function calls. I also added comments indicating that these calls should have been generated by the compiler.
mallocV4.cpp
Because we are now in the domain of automatic memory management, I disabled the newFree() function that has traditionally been defined in this file. The newMalloc() function is still operational, albeit using a different underlying object. If you wish to perform a debug/diagnostic test, you will need to activate the DEBUG_XXX macros.
perform.cpp
The PerformanceTest class defined in this file has not been modified very much. The only thing that changed was the implementation of the runTest() member function. Specifically, I had to remove the calls to newFree(), which are no longer valid, and add in the dec() invocations that the compiler should normally emit.
memmgr.cpp
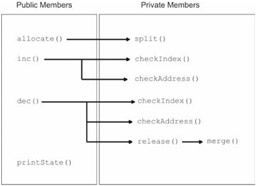
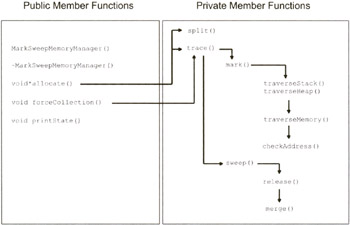
The RefCountMemoryManager class defined in this file is basically an extended version of the SequentialFitMemoryManager. To give you an idea of how this class operates, I have enumerated the possible paths of execution for this class in Figure 5.3 (on the following page).
Most of the action happens as a result of the allocate() or dec() functions being called. Both the inc() and dec() functions perform a series of sanity checks before they modify the heap block list. The inc() function increments the reference count of a memory block, and the dec() function decrements the reference count of a memory block. As you can see from Figure 5.3, the release () function has been made subservient to the dec() function.
#ifdef DEBUG_RC_MEM_MGR
#define MSGO(arg); printf(arg);
#define MSG1(arg1,arg2); printf(arg1,arg2);
#else
#define MSG0(arg);
#define MSG1(arg1,arg2);
#endif
#define U1 unsigned char
#define U4 unsigned long
/*
list element format
|0 3||4 7||8 11||12 15||16 .. n|
[PREV][NEXT][COUNT][ SIZE ][payload]
U4 U4 U4 U4 ?
byte allocated/freed is address of first byte of payload
header = 16 bytes
byte[0] is occupied by header data, so is always used, thus
first link has prev=0 ( 0 indicates not used )
last link has next=0
*/
#define PREV(i) (*((U4*)(&ram[i-16])))
#define NEXT(i) (*((U4*)(&ram[i-12])))
#define COUNT(i) (*((U1*)(&ram[i-8]))) /*# references*/
#define SIZE(i) (*((U4*)(&ram[i-4])))
#define FREE 0 /*free blocks have COUNT=0*/
#define START 16 /*address of first payload*/
#define SZ_HEADER 16
class RefCountMemoryManager
{
private:
HANDLE handle;
U1 *ram; /*memory storage*/
U4 size;
int checkAddress(void *addr);
int checkIndex(U4 free);
void release(U4 free);
void split(U4 addr,U4 nbytes);
void merge(U4 prev,U4 current,U4 next);
public:
RefCountMemoryManager(U4 nbytes);
~RefCountMemoryManager();
void*allocate(U4 nbytes);
void inc(void *addr);
void dec(void *addr);
void printState();
};
RefCountMemoryManager::RefCountMemoryManager(U4 nbytes)
{
handle = GetProcessHeap();
if(handle==NULL)
{
printf("RefCountMemoryManager::");
printf("RefCountMemoryManager():");
printf("invalid handle\n");
exit (1);
}
ram = (U1*)HeapAlloc(handle,HEAP__ZERO_MEMORY,nbytes);
//for portability, you could use:
//ram = (unsigned char*)malloc(nbytes);
size = nbytes;
if(size<=SZ_HEADER)
{
printf("RefCountMemoryManager::");
printf("RefCountMemoryManager():");
printf("not enough memory fed to constructor\n");
exit (1) ;
}
PREV(START)=0;
NEXT(START)=0;
COUNT(START)=0;
SIZE(START)=size-SZ_HEADER;
MSG0("RefCountMemoryManager::");
MSG1("RefCountMemoryManager(%lu)\n",nbytes);
return;
}/*end constructor --------------------------------------------*/
RefCountMemoryManager::~RefCountMemoryManager()
{
if(HeapFree(handle,HEAP_NO_SERIALIZE,ram)==0)
{
printf("RefCountMemoryManager::");
printf("~RefCountMemoryManager():");
printf("could not free heap storage\n");
return;
}
//for portability, you could use:
//free(ram);
MSG0("RefCountMemoryManager::");
MSG0("~RefCountMemoryManager()");
MSG1("free ram[%lu]\n",size);
return;
}/*end destructor---------------------------------------------*/
/*
U4 nbytes - number of bytes required
returns address of first byte of memory region allocated
( or NULL if cannot allocate a large enough block )
*/
void* RefCountMemoryManager::allocate(U4 nbytes)
{
U4 current;
MSG0("RefCountMemoryManager::");
MSG1 ("allocate(%lu)\n",nbytes);
if(nbytes==0)
{
MSG0("RefCountMemoryManager::");
MSG0("allocate(): zero bytes requested\n");
return(NULL);
}
//traverse the linked list, starting with first element
current = START;
while(NEXT(current)!=0)
{
if((SIZE(current)>=nbytes)&&(COUNT(current)==FREE))
{
split(current,nbytes);
return((void*)&ram[current]);
}
current = NEXT(current);
}
//handle the last block ( which has NEXT(current)=0 )
if ( (SIZE (current)>=nbytes)&&(COUNT(current)==FREE))
{
split(current,nbytes);
return((void*)&ram[current]);
}
return(NULL);
}/*end allocation----—--—--—--—--—--—--—--—--—--—--------------*/
/*
breaks [free] region into [alloc][free] pair, if possible
*/
void RefCountMemoryManager::split(U4 addr, U4 nbytes)
{
/*
want payload to have enough room for
nbytes = size of request
SZ_HEADER = header for new region
SZ_HEADER = payload for new region (arbitrary 16 bytes)
*/
if(SIZE(addr)>= nbytes+SZ_HEADER+SZ_HEADER)
{
U4 oldnext;
U4 oldprev;
U4 oldsize;
U4 newaddr;
MSG0("RefCountMemoryManager::");
MSG0("split(): split=YES\n");
oldnext=NEXT(addr);
oldprev=PREV(addr);
oldsize=SIZE(addr);
newaddr = addr + nbytes + SZ_HEADER;
NEXT(addr)=newaddr;
PREV(addr)=oldprev;
COUNT(addr)=1;
SIZE(addr)=nbytes;
NEXT(newaddr)=oldnext;
PREV(newaddr)=addr;
COUNT(newaddr)=FREE;
SIZE(newaddr)=oldsize-nbytes-SZ_HEADER;
}
else
{
MSG0("RefCountMemoryManager::");
MSG0 "split () : split=NO\n");
COUNT(addr)=1;
}
return;
}/*end split--------------------------------------------------*/
int RefCountMemoryManager::checkAddress(void *addr)
{
if(addr==NULL)
{
MSG0("RefCountMemoryManager::");
MSG0("checkAddress(): cannot release NULL pointer\n");
return(FALSE);
}
MSG0("RefCountMemoryManager::");
MSG1("checkAddress(%lu)\n",addr);
//perform sanity check to make sure address is kosher
if( (addr>= (void*)&ram[size]) || (addr< (void*)&ram[0]) )
{
MSG0("RefCountMemoryManager::");
MSG0("checkAddress(): address out of bounds\n");
return(FALSE);
}
return(TRUE);
}/*end checkAddress-------------------------------------------*/
int RefCountMemoryManager::checkIndex(U4 free)
{
//a header always occupies first SZ_HEADER bytes of storage
if(free<SZ_HEADER)
{
MSG0("RefCountMemoryManager::");
MSG0("checkIndex(): address in first 16 bytes\n");
return(FALSE);
}
//more sanity checks
if((COUNT(free)==FREE) || //region if free
(PREV(free)>=free) || //previous element not previous
(NEXT(free)>=size) || //next is beyond the end
(SIZE(free)>=size) || //size greater than whole
(SIZE(free)==0)) //no size at all
{
MSG0("RefCountMemoryManager::");
MSG0("checkIndex(): referencing invalid region\n");
return (FALSE);
}
return (TRUE);
}/*end checkIndex-----------------------------------------------*/
void RefCountMemoryManager::inc(void *addr)
{
U4 free; //index into ram[]
if(checkAddress(addr)==FALSE){ return; }
//translate void* addr to index in ram[]
free = (U4)( ((U1*)addr) - &ram[0] );
MSG0("RefCountMemoryManager::");
MSG1("inc(): address resolves to index %lu\n",free);
if(checkIndex(free)==FALSE){ return; }
COUNT(free) = COUNT(free)+1;
MSG0("RefCountMemoryManager::");
MSG1("inc(): incrementing ram[%lu] ",free);
MSG1("to %lu\n",COUNT(free));
return;
}/*end inc-----------------------------------------------*/
void RefCountMemoryManager::dec(void *addr)
{
U4 free; //index into ram[]
if(checkAddress(addr)==FALSE){ return; }
//translate void* addr to index in ram[]
free = (U4)( ((U1*)addr) - &ram[0] );
MSG0("RefCountMemoryManager::");
MSG1("dec(): address resolves to index %lu\n",free);
if(checkIndex(free)==FALSE){ return; }
COUNT(free) = COUNT(free)-1;
MSG0("RefCountMemoryManager::");
MSG1("dec(): decrementing ram[%lu] ",free);
MSG1("to %lu\n",COUNT(free));
if(COUNT(free)==FREE)
{
MSG0("RefCountMemoryManager::");
MSG1("dec(): releasing ram[%lu]\n",free);
release(free);
}
return;
}/*end dec---------------------------------------------------*/
void RefCountMemoryManager::release(U4 free)
{
merge(PREV(free),free,NEXT(free));
#ifdef DEBUG_RC_MEM_MGR
printState();
#endif
return;
}/*end release--—---—--—--—--—--—--—--—--—--—--—-------------*/
/*
4 cases ( F=free O=occupied )
FOF -> [F]
OOF -> O[F]
FOO -> [F]0
000 -> OFO
*/
void RefCountMemoryManager::merge(U4 prev,U4 current,U4 next)
{
/*
first handle special cases of region at end(s)
prev=0 low end
next=0 high end
prev=0 and next=0 only 1 list element
*/
if (prev==0)
{
if(next==0)
{
COUNT(current)=FREE;
}
else if(COUNT(next)!=FREE)
{
COUNT(current)=FREE;
}
else if(COUNT(next)==FREE)
{
U4 temp;
MSG0("RefCountMemoryManager::merge():");
MSG0("merging to NEXT\n");
COUNT(current)=FREE;
SIZE(current)=SIZE(current)+SIZE(next)+SZ_HEADER;
NEXT(current)=NEXT(next);
temp = NEXT(next);
if(temp!=0){ PREV(temp)=current; }
}
}
else if(next==0)
{
if(COUNT(prev)!=FREE)
{
COUNT(current)=FREE;
}
else if(COUNT(prev)==FREE)
{
MSG0("RefCountMemoryManager::merge():");
MSG0("merging to PREV\n");
SIZE(prev)=SIZE(prev)+SIZE(current)+SZ_HEADER;
NEXT(prev)=NEXT(current);
}
}
/* now we handle 4 cases */
else if((COUNT(prev) !=FREE)&&(COUNT(next) !=FREE))
{
COUNT(current)=FREE;
}
else if((COUNT(prev)!=FREE)&&(COUNT(next)==FREE))
{
U4 temp;
MSG0("RefCountMemoryManager::merge():");
MSG0("merging to NEXT\n");
COUNT(current)=FREE;
SIZE(current)=SIZE(current)+SIZE(next)+SZ_HEADER;
NEXT(current)=NEXT(next);
temp = NEXT(next);
if(temp!=0){ PREV(temp)=current; }
}
else if((COUNT(prev)==FREE)&&(COUNT(next)!=FREE))
{
MSG0("RefCountMemoryManager::merge():");
MSG0("merging to PREV\n");
SIZE(prev)=SIZE(prev)+SIZE(current)+SZ_HEADER;
NEXT(prev)=NEXT(current);
PREV(next)=prev;
}
else if((COUNT(prev)==FREE)&&(COUNT(next)==FREE))
{
U4 temp;
MSG0("RefCountMemoryManager::merge():");
MSG0("merging with both sides\n");
SIZE(prev)=SIZE(prev)+
SIZE(current)+SZ_HEADER+
SIZE(next)+SZ_HEADER;
NEXT(prev)=NEXT(next);
temp = NEXT(next);
if(temp!=0){ PREV(temp)=prev; }
}
return;
}/*end merge -----------------------------------------------*/
void RefCountMemoryManager::printState()
{
U4 i;
U4 current;
i=0;
current=START;
while(NEXT(current)!=0)
{
printf("%lu) [P=%lu]",i,PREV(current));
printf("[addr=%lu]",current);
if(COUNT(current)==FREE){ printf("[FREE]"); }
else{ printf("[Ct=%lu]",COUNT(current)); }
printf("[Sz=%lu]",SIZE(current));
printf("[N=%lu]\n",NEXT(current));
current = NEXT(current);
i++;
}
//print the last list element
printf("%lu) [P=%lu]",i,PREV(current));
printf("[addr=%lu]",current);
if(COUNT(current)==FREE){ printf("[FREE]"); }
else{ printf("[Ct=%lu]",COUNT(current)); }
printf("[Sz=%lu]",SIZE(current));
printf("[N=%lu]\n",NEXT(current));
return;
}/*end printState---------------------------------------------*/
Tests
I performed two different tests against this memory manager. A debug test was performed to make sure that the manager was doing what it was supposed to do. If you modify my source code, I would suggest running the debug test again to validate your changes. Once I was sure that the memory manager was operational, I turned off debugging features and ran a performance test.
The debug test was performed by executing the code in the debugTest() function defined in the driver.cpp source file. I keep things fairly simple, but at the same time, I take a good, hard look at what is going on. If you decide to run a debug test, you will want to make sure that the DEBUG_xxx macros in mallocV4.cpp are turned on. You will also want to comment out the PerformanceTestDriver() function call in main().
The following output was generated by the debug build of the memory manager:
The performance test was conducted by commenting out debugTest() and the debug macros in mallocV4.cpp, and then enabling the PerformanceTestDriver() function. The results of the performance run were, well, surprising:
Not bad.
Trade-Offs
The reference counting approach to garbage collection is convenient because it offers a type of collection that is incremental, which is to say that the bookkeeping needed to reclaim garbage is done in short, bite-sized bursts. This allows the memory manager to do its jobs without introducing a significant time delay into the program's critical path. Some garbage collectors wait to do everything at once so that users may experience a noticeable pause while a program runs.
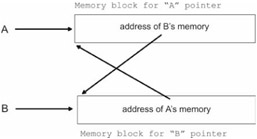
While the reference counting approach is fast, it also suffers from some serious problems. For example, reference counting garbage collectors cannot reclaim objects that reference each other. This is known as a cycle (see Figure 5.4).
Let us assume that we have two heap-allocated variables, A and B, which reference one another. For example:
If the variable A goes out of scope, its heap storage will still not be reclaimed. This is because B still references it so that its reference count is 1. The same holds true for B. Because of the pointer tomfoolery performed, and because of the nature of reference counting, neither of these blocks of memory will ever have their storage reclaimed because their reference counts will never be able to reach zero.
| Note |
The ugly truth is that the inability to handle cyclic references is what allows reference counting schemes to develop memory leaks. This is one reason why most run-time systems, like the Java virtual machine, avoid reference counting garbage collection.
|
Another problem with reference counting schemes is that functions with a lot of local variables can cause the memory manager to perform an excessive amount of reference count incrementing and decrementing.
One solution is to use deferred reference counting, where the memory manager does not include local variables when it maintains reference counts. The problem with this is that you cannot be sure if a memory block can be reclaimed when its reference count is zero. This is because there might still be one or more local variables referencing the memory block. If you reclaim too early, you will end up with a bunch of dangling pointers! This is why most memory managers that implement deferred reference counting will use it in conjunction with a tracing algorithm that can survey the stack for local variable pointers.
Another reference counting technique is to use a COUNT field that is a single bit in size. This is known as 1-bit reference counting. The gist of this technique is that the number of references to a block of memory is always zero, one, or many. So the 1-bit COUNT field will be zero or one. When it is one, there may be one or more references. In many cases, there is only a single reference and garbage collection is very quick. However, there also may be many references, which is why the 1-bit reference counting technique is usually used with another tracing garbage collector.
malloc() Version 5: Mark-Sweep
Theory
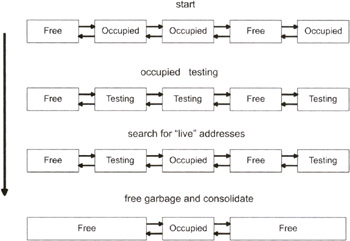
The operation of automatic memory managers consists of two phases: locating memory garbage and reclaiming that garbage. The mark-sweep approach to garbage collection is named after how it implements these two phases. The mark-sweep technique belongs to the tracing school of garbage collection. This means that a mark-sweep collector takes an active role in ferreting out memory references instead of relying on the compiler to do all the work.
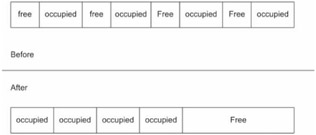
The mark phase involves taking all the currently occupied memory blocks and marking them as "testing" because, for the moment, we do not know which memory blocks are genuinely occupied and which memory blocks are garbage. Next, the mark-sweep collector looks through the application's memory space searching for pointers to the heap. Any memory blocks that still have pointers referencing them are allowed to return to "occupied" status.
The remaining "testing" blocks are assumed to be garbage and collected. The sweep phase involves moving through the heap and releasing these "testing" blocks. In other words, the memory manager sweeps all of the garbage back into the "free" bucket.
The basic mark-sweep dance steps are displayed in Figure 5.5.
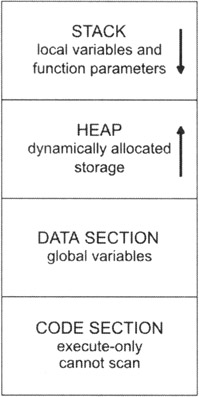
As mentioned in Chapter 3, most applications have four types of sections: code sections, data sections, stack sections, and one or more heaps. Because code sections tend to be designated as execute-only memory areas, only the stack, heap, and data section of an application can be scanned for pointers (see Figure 5.6). In my implementation, I scan only the heap and the stack.
|
1.
|
OK, so if the manager looks for pointers, what does a pointer look like?
|

|
Answers
|
1.
|
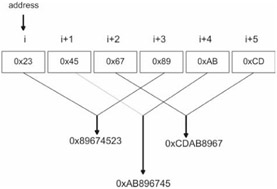
Some compilers add a special tag to pointers. The problem with this approach is that the tag consumes part of a pointer's storage space and prevents a pointer from being capable of referencing the full address space. I decided that in my implementation, I would use a conservative garbage collection approach and consider any 32-bit value to be a potential pointer. This basically means that I have to scan memory byte-by-byte to enumerate every possible 32-bit value (see Figure 5.7).
|
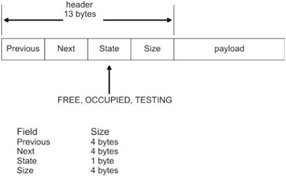
In my implementation, each memory block header has a STATE field. This field is 8 bits in size and may be in one of three states: Free, Occupied, Testing. The remaining fields are similar to those used by the sequential fit manual memory manager (see Figure 5.8).
There are a couple of policy decisions that a mark-sweep collector has to make. Specifically, a mark-sweep memory manager has to decide which parts of memory it is going to monitor and when it is going sweep them to reclaim garbage.
I decided in my implementation that I would search for pointers in the heap and the stack. This would allow me to search through an application's local variables and dynamically allocated storage. As far as deciding when to garbage collect, I decided to use a counter variable called tick that would invoke the garbage collection algorithm after reaching a certain value (stored in a variable called period). The programmer can configure the value of period so that they may control how often garbage collection occurs.
I also provide a forceCollection() function that can be used to force the memory manager to perform a sweep of memory.
| Note |
This function does not suggest that garbage collection occur; it demands that garbage collection occur.
|
Implementation
I decided to implement a mark-sweep garbage collector by modifying the sequential fit implementation in Chapter 4. My implementation of the reference counting memory manager required four files:
Table 5.2
|
File
|
Use
|
|
driver.cpp
|
contains main(), is the scene of the crime
|
|
mallocV5.cpp
|
newMalloc(), newFree() wrappers (5th version)
|
|
perform.cpp
|
implements the PerformanceTest class
|
|
memmgr.cpp
|
implements the MarkSweepMemoryManager class
|
driver.cpp
This file contains the main() entry point. You can build my implementation to execute a diagnostic test or a performance test. To build the diagnostic version, you will need to comment out the PerformanceTestDriver() invocation and uncomment the debugTest() invocation. You will also need to activate the DEBUG_XXX macros in the mallocV4.cpp file.
You might notice a weird-looking function called getTOS(), which is invoked in main(). This is the first statement in main(), and it resolves to a macro defined in memmgr.cpp. This macro, which stands for get Top Of the Stack, obtains the value of EBP register so that my code knows where to stop its scan of the stack while looking for pointers. The main() function, like other C functions, has a prologue that sets up the EBP register as a stack frame pointer.
By saving the value of EBP as soon as main() begins, I ensure that I can scan as much of the stack as legally possible.
mallocV5.cpp
Because we are now in the domain of automatic memory management, I disabled the newFree() function that has traditionally been defined in this file. The newMalloc() function is still operational, albeit using a different underlying object. If you wish to perform a debug/diagnostic test, you will need to activate the DEBUG_XXX macros.
You also might want to keep in mind that I have included a forceCollection() wrapper function that allows you to invoke the garbage collector.
perform.cpp
The PerformanceTest class defined in this file has not been modified very much. The only thing that changed was the implementation of the runTest() member function. Specifically, I had to remove the calls to newFree(), which are no longer valid. I also replaced the array of void*addr [] pointers with a single addr pointer so that I could overwrite its contents and produce garbage.
memmgr.cpp
The MarkSweepMemoryManager class defined in this file is basically an extended version of the SequentialFitMemoryManager. To give you an idea of how this class operates, I have enumerated the possible paths of execution for this class in Figure 5.9.
Most of what happens is performed as a result of invoking the allocate() function. Normally, allocate() will reserve storage and split free blocks. However, if the ticks variable has hit its period value, the garbage collector will kick into action via the trace() function.
#ifdef DEBUG_MS_MEM_MGR
#define MSG0(arg); printf(arg);
#define MSG1(arg1,arg2); printf(arg1,arg2);
#else
#define MSG0(arg);
#define MSG1(arg1,arg2);
#endif
#define U1 unsigned char
#define U4 unsigned long
/*
list element format
|0 3||4 7|| 8 ||9 12||13 .. n|
[PREV][NEXT][STATE][SIZE][payload]
U4 U4 U1 U4 ?
byte allocated/freed is address of first byte of payload
header = 13 bytes
byte[0] is occupied by header data, so is always used, thus
first link has prev=0 ( 0 indicates not used )
last link has next=0
*/
#define PREV(i) (*((U4*)(&ram[i-13])))
#define NEXT(i) (*((U4*)(&ram[i-9])))
#define STATE(i) (*((U1*)(&ram[i-5])))
/*FREE,OCCUPIED,TESTING*/
#define SIZE(i) (*((U4*)(&ram[i-4])))
#define FREE 0
#define OCCUPIED 1
#define TESTING 2
char *stateStr[3]={"FREE","OCCUPIED","TESTING"};
#define START 13 /*address of first payload*/
#define SZ_HEADER 13
U4 stackFrameBase;
#define getTOS() _asm{ MOV stackFrameBase, EBP}
class MarkSweepMemoryManager
{
private:
HANDLE handle;
U1 *ram; //pointer to memory storage
U4 size; //nbytes in storage
U1 ticks; //used to trigger collection
U1 period; //# ticks before collect
void split(U4 addr,U4 nbytes);
void trace();
void mark();
void traverseStack();
void traverseHeap();
void traverseMemory(U1 *addr,U4 nbytes);
int checkAddress(void *addr);
void sweep();
void release(U4 index);
void merge(U4 prev,U4 current,U4 next);
public:
MarkSweepMemoryManager(U4 nbytes,U1 maxticks);
~MarkSweepMemoryManager();
void*allocate(U4 nbytes);
void forceCollection();
void printState();
};
MarkSweepMemoryManager::MarkSweepMemoryManager(U4 nbytes,U1
maxticks)
{
handle = GetProcessHeap();
if(handle==NULL)
{
printf("MarkSweepMemoryManager::");
printf("MarkSweepMemoryManager():");
printf ("invalid handle\n");
exit (1);
}
ram = (U1*)HeapAlloc(handle,HEAP_ZERO_MEMORY,nbytes);
//for portability, you could use:
//ram = (unsigned char*)malloc(nbytes);
size = nbytes;
if(size<=SZ_HEADER)
{
printf("MarkSweepMemoryManager::");
printf("MarkSweepMemoryManager():");
printf("not enough memory fed to constructor\n");
exit (1);
}
PREV(START)=0;
NEXT(START)=0;
STATE(START)=FREE;
SIZE(START)=size-SZ_HEADER;
MSG0("MarkSweepMemoryManager::");
MSG1("MarkSweepMemoryManager(): ram[%lu], ",nbytes);
ticks = 0;
period = maxticks;
MSG1("ticks=%u, ",ticks);
MSG1("period=%u\n",period);
return;
}/*end constructor --------------------------------------------*/
MarkSweepMemoryManager::~MarkSweepMemoryManager()
{
if(HeapFree(handle,HEAP_NO_SERIALIZE,ram)==0)
{
printf("MarkSweepMemoryManager::");
printf("~MarkSweepMemoryManager():");
printf("could not free heap storage\n");
return;
}
//for portability, you could use:
//free(ram);
MSG0("MarkSweepMemoryManager::");
MSG0("~MarkSweepMemoryManager()");
MSG1("free ram[%lu]\n",size);
return;
}/*end destructor----------------------------------------------*/
/*
U4 nbytes - number of bytes required
returns address of first byte of memory region allocated
( or NULL if cannot allocate a large enough block )
*/
void* MarkSweepMemoryManager::allocate(U4 nbytes)
{
U4 current;
MSG0("MarkSweepMemoryManager::");
MSG1("allocate(%lu)\n", nbytes);
if(nbytes==0)
{
MSG0("MarkSweepMemoryManager::");
MSG0("allocate(): zero bytes requested\n");
return(NULL);
}
//before we start, garbage collect if the time has arrived
ticks++;
MSG0("MarkSweepMemoryManager::");
MSG1("allocate(): gc check -> [ticks,period]=[%u,",ticks);
MSG1("%u]\n",period);
if(ticks==period)
{
trace();
ticks=0;
}
//traverse the linked list, starting with first element
current = START;
while(NEXT(current)!=0)
{
if((SIZE(current)>=nbytes)&&(STATE(current)==FREE))
{
split(current,nbytes);
return((void*)&ram[current]);
}
current = NEXT(current);
}
//handle the last block ( which has NEXT(current)=0 )
if((SIZE(current)>=nbytes)&&(STATE(current)==FREE))
{
split(current,nbytes);
return((void*)&ram[current]);
}
return(NULL);
}/*end allocation ----------------------------------------------*/
/*
breaks [free] region into [alloc] [free] pair, if possible
*/
void MarkSweepMemoryManager::split(U4 addr, U4 nbytes)
{
/*
want payload to have enough room for
nbytes = size of request
SZ_HEADER = header for new region
SZ_HEADER = payload for new region (arbitrary 13 bytes)
*/
if(SIZE(addr)>= nbytes+SZ_HEADER+SZ_HEADER)
{
U4 oldnext;
U4 oldprev;
U4 oldsize;
U4 newaddr;
MSG0("MarkSweepMemoryManager::");
MSG0("split(): split=YES\n");
oldnext=NEXT(addr);
oldprev=PREV(addr);
oldsize=SIZE(addr);
newaddr = addr + nbytes + SZ_HEADER;
NEXT(addr)=newaddr;
PREV(addr)=oldprev;
STATE(addr)=OCCUPIED;
SIZE(addr)=nbytes;
NEXT(newaddr)=oldnext;
PREV(newaddr)=addr;
STATE(newaddr)=FREE;
SIZE(newaddr)=oldsize-nbytes-SZ_HEADER;
}
else
{
MSG0("MarkSweepMemoryManager::");
MSG0("split(): split=NO\n");
STATE(addr)=OCCUPIED;
}
return;
}/*end split -------------------------------------------------*/
void MarkSweepMemoryManager::forceCollection()
{
MSG0("MarkSweepMemoryManager::");
MSG0("forceCollection(): forcing collection\n");
trace();
return;
}/*end forceCollection----------------------------------------*/
void MarkSweepMemoryManager::trace()
{
MSG0("MarkSweepMemoryManager::");
MSG0 ("trace(): initiating mark-sweep\n");
mark();
sweep();
return;
}/*end trace --------------------------------------------------*/
void MarkSweepMemoryManager::mark()
{
U4 i;
U4 current;
//set all OCCUPIED blocks to TESTING
i=0;
current=START;
while(NEXT(current)!=0)
{
if(STATE(current)==OCCUPIED)
{
STATE(current)=TESTING;
}
current = NEXT(current);
i++;
}
if(STATE(current)==OCCUPIED)
{
STATE(current)=TESTING;
}
#ifdef DEBUG_MS_MEM_MGR
MSG0("MarkSweepMemoryManager::");
MSG0("mark(): toggle OCCUPIED to TESTING\n");
printState();
#endif
//traverse the stack and heap
//if find address to TESTING block, set to OCCUPIED
MSG0("MarkSweepMemoryManager::");
MSG0("mark(): initiating stack and heap traversals\n");
traverseStack();
traverseHeap();
return;
}/*end mark --------------------------------------------------*/
void MarkSweepMemoryManager::traverseStack()
{
U4 currentAddr;
_asm{ MOV currentAddr,ESP };
MSG0("MarkSweepMemoryManager::traverseStack():");
MSG1("EBP=%p\t",stackFrameBase);
MSG1("ESP=%p\n",currentAddr);
//basically traverse stack from current pointer to base
(Lo->Hi)
traverseMemory((U1*)currentAddr,(stackFrameBase-currentAddr));
return;
}/*end traverseStack------------------------------------------*/
void MarkSweepMemoryManager::traverseHeap()
{
MSG0("MarkSweepMemoryManager::traverseHeap(): looking at
heap\n");
traverseMemory(ram,size);
return;
}/*end traverseHeap-------------------------------------------*/
void MarkSweepMemoryManager::traverseMemory(U1 *addr,U4 nbytes)
{
U4 i;
U4 start,end;
U4 *iptr;
start = (U4)addr;
end = start + nbytes -1;
MSG0("MarkSweepMemoryManager::traverseMemory(): ");
MSG1("[start=%lx,",start);
MSG1(" end=%lx]\n",end);
//address = 4 bytes, so stop 4 bytes from end
for(i=start;i<=end-3;i++)
{
//point to integer value at memory address i
iptr = (U4*)i;
//check integer value to see if it is a heap address
if( checkAddress((void *)(*iptr))==TRUE)
{
MSG0("MarkSweepMemoryManager::traverseMemory(): ");
MSG1("value source address=%p\n",iptr);
}
}
return;
}/*end traverseMemory-----------------------------------------*/
int MarkSweepMemoryManager::checkAddress(void *addr)
{
U4 index;
if(addr==NULL){ return(FALSE); }
//check to see if address is out of heap bounds
if( (addr>= (void*)&ram[size]) || (addr< (void*)&ram[0]) )
{
return (FALSE);
}
//translate addr into index
index = (U4)( ((U1*)addr) - &ram[0] );
//now check index to see if reference an actual block
//a header always occupies first SZ_HEADER bytes of storage
if(index<SZ_HEADER){ return(FALSE); }
//more sanity checks
if((STATE(index)!=TESTING) || //region if free
(PREV(index)>=index) || //previous element not previous
(NEXT(index)>=size) || //next is beyond the end
(SIZE(index)>=size) || //size of region greater
//than whole
(SIZE(index)==0)) //no size at all
{
MSG0("MarkSweepMemoryManager::checkAddress():");
MSG1("failed sanity chk (already found) addr=%p ",addr);
return(FALSE);
}
MSG0("MarkSweepMemoryManager::checkAddress():");
MSG1("live memory block at addr=%p ",addr);
MSG1("index=%lu\n",index);
STATE(index)=OCCUPIED;
return(TRUE) ;
}/*end checkAddress-------------------------------------------*/
void MarkSweepMemoryManager::sweep()
{
U4 i;
U4 current;
MSG0("MarkSweepMemoryManager::");
MSG0("sweep(): link sweep intiated\n");
//recycle all the TESTING blocks
i=0;
current=START;
while(NEXT(current)!=0)
{
if(STATE(current)==TESTING)
{
MSG0("MarkSweepMemoryManager::");
MSG1("sweep(): garbage found at index=%lu\n",
current);
release(current);
}
current = NEXT(current);
i++;
}
if(STATE(current)==TESTING)
{
MSG0("MarkSweepMemoryManager::");
MSG1("sweep(): garbage found at index=%lu\n",current);
release(current);
}
return;
}/*end sweep -------------------------------------------------*/
void MarkSweepMemoryManager::release(U4 index)
{
//a header always occupies first 13 bytes of storage
if(index<SZ_HEADER)
{
MSG0("MarkSweepMemoryManager::");
MSG0("release(): address in first 13 bytes\n");
return;
}
//yet more sanity checks
if((STATE(index)==FREE) || //region if free
(PREV(index)>=index) || //previous element not previous
(NEXT(index)>=size) || //next is beyond the end
(SIZE(index)>=size) || //size region greater than whole
(SIZE(index)==0)) //no size at all
{
MSG0("MarkSweepMemoryManager::");
MSG0("release(): referencing invalid region\n");
return;
}
merge(PREV(index),index,NEXT(index));
#ifdef DEBUG_MS_MEM_MGR
MSG0("MarkSweepMemoryManager::");
MSG0("release(): post merge layout\n");
printState();
#endif
return;
}/*end release ------------------------------------------------*/
void MarkSweepMemoryManager::merge(U4 prev,U4 current,U4 next)
{
/*
first handle special cases of region at end(s)
prev=0 low end
next=0 high end
prev=0 and next=0 only 1 list element
*/
if(prev==0)
{
if(next==0)
{
STATE(current)=FREE;
}
else if((STATE(next)==OCCUPIED)||(STATE(next)==TESTING))
{
STATE(current)=FREE;
}
else if(STATE(next)==FREE)
{
U4 temp;
MSG0("MarkSweepMemoryManager::merge():");
MSG0("merging to NEXT\n");
STATE(current)=FREE;
SIZE(current)=SIZE(current)+SIZE(next)+SZ_HEADER;
NEXT(current)=NEXT(next);
temp = NEXT(next);
if(temp!=0){ PREV(temp)=current; }
}
}
else if(next==0)
{
if((STATE(prev)==OCCUPIED)||(STATE(prev)==TESTING))
{
STATE(current)=FREE;
}
else if(STATE(prev)==FREE)
{
MSG0("MarkSweepMemoryManager::merge():");
MSG0("merging to PREV\n");
SIZE(prev)=SIZE(prev)+SIZE(current)+SZ_HEADER;
NEXT(prev)=NEXT(current);
}
}
/*
cases:
OTO -> OFO
TTT TFT
TTO TFO
OTT OFT
OTF O[F]
TTF T[F]
FTO [F]O
FTT [F]T
FTF [F]
*/
else if((STATE(prev)==OCCUPIED)&&(STATE(next)==OCCUPIED))
{
STATE(current)=FREE;
}
else if((STATE(prev)==TESTING)&&(STATE(next)==TESTING))
{
STATE(current)=FREE;
}
else if((STATE(prev)==TESTING)&&(STATE(next)==OCCUPIED))
{
STATE(current)=FREE;
}
else if((STATE(prev)==OCCUPIED)&&(STATE(next)==TESTING))
{
STATE(current)=FREE;
}
else if((STATE(prev)==OCCUPIED)&&(STATE(next)==FREE))
{
U4 temp;
MSG0("MarkSweepMemoryManager::merge():");
MSG0("merging to NEXT\n");
STATE(current)=FREE;
SIZE(current)=SIZE(current)+SIZE(next)+SZ_HEADER;
NEXT(current)=NEXT(next);
temp = NEXT(next);
if(temp!=0){ PREV(temp)=current; }
}
else if((STATE(prev)==TESTING)&&(STATE(next)==FREE))
{
U4 temp;
MSG0("MarkSweepMemoryManager::merge():");
MSG0("merging to NEXT\n");
STATE(current)=FREE;
SIZE(current)=SIZE(current)+SIZE(next)+SZ_HEADER;
NEXT(current)=NEXT(next);
temp = NEXT(next);
if(temp!=0){ PREV(temp)=current; }
}
else if((STATE(prev)==FREE)&&(STATE(next)==OCCUPIED))
{
MSG0("MarkSweepMemoryManager::merge():");
MSG0("merging to PREV\n");
SIZE(prev)=SIZE(prev)+SIZE(current)+SZ_HEADER;
NEXT(prev)=NEXT(current);
PREV(next)=prev;
}
else if((STATE(prev)==FREE)&&(STATE(next)==TESTING))
{
MSG0("MarkSweepMemoryManager::merge():");
MSG0("merging to PREV\n");
SIZE(prev)=SIZE(prev)+SIZE(current)+SZ_HEADER;
NEXT(prev)=NEXT(current);
PREV(next)=prev;
}
else if((STATE(prev)==FREE)&&(STATE(next)==FREE))
{
U4 temp;
MSG0("MarkSweepMemoryManager::merge():");
MSG0("merging with both sides\n");
SIZE(prev)=SIZE(prev) +
SIZE(current)+SZ_HEADER+
SIZE(next)+SZ_HEADER;
NEXT(prev)=NEXT(next);
temp = NEXT(next);
if(temp!=0){ PREV(temp)=prev; }
}
return;
}/*end merge -------------------------------------------------*/
void MarkSweepMemoryManager::printState()
{
U4 i;
U4 current;
i=0;
current=START;
while(NEXT(current)!=0)
{
printf("%lu) [P=%lu]",i,PREV(current));
printf("[addr=%lu]",current);
printf("[St=%s]",stateStr[STATE(current)]);
printf("[Sz=%lu]",SIZE(current));
printf("[N=%lu]\n",NEXT(current));
current = NEXT(current);
i++;
}
//print the last list element
printf("%lu) [P=%lu]",i,PREV(current));
printf("[addr=%lu]",current);
printf("[St=%s]",stateStr[STATE(current)]);
printf("[Sz=%lu]",SIZE(current));
printf("[N=%lu]\n",NEXT(current));
return;
}/*end printState---------------------------------------------*/
Tests
I performed two different tests against this memory manager. A debug test was performed to make sure that the manager was doing what it was supposed to do. If you modify my source code, I would suggest running the debug test again to validate your changes. Once I was sure that the memory manager was operational, I turned off debugging features and ran a performance test.
The debug test was performed by executing the code in the debugTest() function defined in the driver.cpp source file. I keep things fairly simple, but at the same time, I take a good, hard look at what is going on. If you decide to run a debug test, you will want to make sure that the DEBUG_XXX macros in mallocV4.cpp are turned on. You will also want to comment out the PerformanceTestDriver() function call in main().
The following output was generated by the debug build of the memory manager:
The debug test code is a little involved, so I am going to provide a blow-by-blow account of what happens. Let's start by looking at a snippet of code from debugTest():
By the time the newMalloc (allocs [3]) call has been made, the local variables of debugTest() have the following values:
Table 5.3
|
Variable
|
ram[]index
|
Size of Block Referenced
|
|
ptr
|
59
|
33
|
|
ptr1
|
-
|
-
|
|
ptr2
|
34
|
12
|
|
lptr
|
NULL
|
-
|
|
heap variable
|
59
|
33
|
The ptr variable has overwritten itself several times and will point to the most recent heap allocation. In addition, a variable in the heap, initially pointed to by lptr, stores an address belonging to the heap.
When the newMalloc(allocs[3]) code has been reached, the ticks variable will be equal to 4, and garbage collection will occur. This will cause the 8-byte block that was allocated first to be reclaimed. All the other allocated heap blocks still have "live" pointers.
Once garbage collection has occurred, the following code will execute:
This will cause the local variables of debugTest() to assume the following values:
Table 5.4
|
Variable
|
ram[ ] index
|
Size of Block Referenced
|
|
ptr
|
NULL
|
-
|
|
ptr1
|
105
|
122
|
|
ptr2
|
13
|
8
|
|
lptr
|
NULL
|
-
|
|
heap variable
|
59
|
33
|
The last allocation call cannot be serviced, so NULL is returned into ptr. This leaves us with three "live" pointers. If you look at the debug output, you will see that there are three OCCUPIED regions of memory in the heap after garbage collection occurs.
The performance test was conducted by commenting out debugTest() and the debug macros in mallocV5.cpp, and then enabling the PerformanceTestDriver() function. The results of the performance run were initially disappointing:
Whoa. After changing the value of period from 4 to 200, the performance was more acceptable:
This is a far cry from the 35 milliseconds that was necessary for the sequential fit implementation to do its job. As I mentioned earlier, extra bookkeeping is the cost of automatic memory management, and this translates into additional execution time.
Trade-Offs
While my mark-sweep collector does not exactly compete with the reference counting version, it does successfully handle the cyclic-reference problem that caused a memory leak in the previous implementation. With a little refinement, I could probably whittle down the performance time to less than 100 milliseconds. I will present some suggestions for improvement at the end of this chapter.
Besides performance, two additional problems are created through use of the mark-sweep collector: latency and external fragmentation. Not only does my implementation lead to scattered groups of free and reserved blocks, but it would be possible for two related blocks of memory to be located at opposite ends of the heap.
The copying garbage collector is a variation of the mark-sweep collector that attempts to deal with these two problems. The copying garbage collector copies "live" memory blocks to the low end of memory so that all the allocated storage ends up concentrated in one region of the heap, leaving the rest of the heap to service allocation requests. Not only does this solve the latency problem, but it also allows memory requests for larger blocks to be serviced. This is illustrated in Figure 5.10.
Because all the "live" pointers on the stack, in the heap, and in the data segment need to be updated with new values when the memory blocks that they point to are relocated, copying collection can be difficult. Not only does this add complexity, but these extra steps also hurt execution time. In addition, extra storage space is needed in order to copy allocated blocks of memory on the heap from one location to another. Depending on the size of the memory block being moved, this can be a significant amount of storage (perhaps even the amount of heap space initially allocated to the garbage collector).
Performance Comparison
At this point, it might be enlightening to gather all of the statistics from the past two chapters together:
Table 5.5
|
Algorithm
|
Time to Service 1,024 Requests
|
|
bit map
|
856 milliseconds
|
|
sequential fit
|
35 milliseconds
|
|
segregated lists
|
5 milliseconds
|
|
reference counting
|
30 milliseconds
|
|
mark-sweep
|
430 milliseconds
|
Hands down, the segregated list approach is the quickest. It also wastes memory like nobody's business. It would be very easy (with the segregated list approach) to end up reserving 1,024 bytes for an 8-byte allocation request. This leaves the sequential fit algorithm as the most attractive implementation with regard to the manual memory managers presented in Chapter 2.
While the reference counting approach is actually faster than two of the manual memory managers, it also has the nasty habit of developing memory leaks when confronted with cyclic pointer references. The whole point of using a garbage collector is to avoid memory leaks, so this problem kicks reference counting out of the race. This leaves us with the mark-sweep garbage collector, which has obvious performance issues.
I will spend the remainder of this book suggesting various ways to augment the mark-sweep collector's execution time and functionality. I will leave it as an exercise to the reader to augment the mark-sweep collector with these additional features.
Potential Additions
The mark-sweep garbage collector that I provided in this chapter was a bare-bones implementation (and that is an understatement). I deliberately kept things as simple as I could so that you could grasp the big picture without being bogged down with details. Seeing as how my mark-sweep collector had only the minimum set of features, I thought it might be wise to point out a few of the features that could be added to round out the functionality of the mark-sweep collector.
Object Format Assumptions
So far, I have referred to regions in the heap as "memory blocks." I have done this intentionally so that I could keep the discussion as general as possible. In the end, everything on the heap is merely a block of memory. Depending on what that block of memory represents, however, it may require additional steps when the block of memory is allocated and reclaimed.
For example, objects have both constructors and destructors. When an object is created, its constructor must be called. When an object's storage is reclaimed, its destructor needs to be invoked.
When an object is created off the heap, the compiler will typically pass the object to its constructor. Consider this code:
In addition to requesting storage from the heap via the new operator, most compilers will also emit the code necessary to pass the new object to its constructor:
If manual memory management is being used, the programmer will include source code that will take care of reclaiming the object's storage in the heap.
As before, not only will the compiler emit the instructions necessary to reclaim the object, but it will also emit the instructions necessary to call the object's destructor before reclamation occurs:
If a garbage collector is being used to manage reclamation, the programmer will never issue a call to delete (). This means that the garbage collector will have to do this behind the scenes. In order to obey this protocol, a memory manager will need to know which blocks are objects. If a given memory block represents an object, the memory manager will also need to know what type of object it is dealing with.
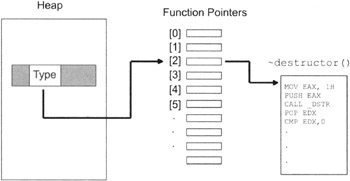
To institute this type of functionality with my mark-sweep collector, you might want to consider adding another field to the memory block header (see Figure 5.11).
This new field, which we'll call TYPE, indicates if the memory block is an object, and if it is, then it indexes an element in an array of function pointers. These function pointers store the addresses of destructor functions. This setup is displayed in Figure 5.12.
When a memory block is about to be reclaimed, the garbage collector will check to see if the memory block represents an object. If the memory block is an object, the collector will invoke the object's destructor before it reclaims the memory block's storage.
Naturally, there are many more details to consider than I've mentioned, such as setting up the table of function pointers and handling nested objects that call different destructors. You will have to experiment with a number of different approaches. Nevertheless, I hope to have guided you in the right direction.
Variable Heap Size
In all of my implementations, the amount of storage space that the memory manager has to work with is fixed in size. This means that if the manager runs out of memory, it will not be able to service additional requests. To provide greater flexibility, you could allow a memory manager to request more memory from the underlying operating system. This way, when a manager runs out of storage, it simply expands its space by calling the operating system for help.
There are problems related to doing this. For example, if you use an ANSI function, like realloc(), to increase the memory manager's storage space, you cannot be sure if the resized memory region will be relocated. Relocation basically invalidates all of an application's existing pointers because the memory regions that they referenced have been moved.
Microsoft's HeapReAlloc() Win32 call allows you to specify a special flag value:
This requires that the reallocated memory not be moved.
Indirect Addressing
During the discussion of copying collection and memory reallocation, you have seen how moving memory can make life difficult for an application. The only solution that seems halfway tractable is to traverse the application's stack, heap, and data segment and update the pointer values to reference new locations.
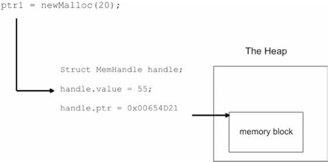
There is, however, a different approach. Rather than have pointers reference actual memory, you can have them store handles. A handle could be implemented simply by a structure that maps an integer handle value to a physical address:
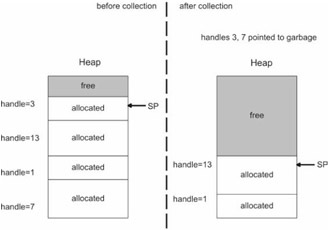
This would allow you to change the address of a memory block (i.e., void *ptr) without having to change the value stored by pointers in the application (i.e., unsigned long value). When an address change does occur, all you need to update is a single MemHandle structure instead of potentially dozens of application variables. This type of relationship is displayed in Figure 5.13.
For example, consider the following code:
When I initially call newmalloc(), the value stored in ptr1 is a handle value instead of an actual address. When I call forceCollection() to initiate garbage collection, memory blocks in the heap may end up being rearranged. However, the handle value will not change, even if its associated address does.
Some garbage collectors use handles in conjunction with a stack allocation scheme. Memory is allocated in a fashion similar to a stack. There is a pointer (SP) that keeps track of the top of the stack. Allocation requests cause the stack pointer to increment. This is a very fast scheme in practice (even faster than the segregated list approach).
When the stack hits its limit, the garbage collector kicks in and reclaims garbage. To minimize fragmentation, the occupied blocks are all shifted down to the bottom of the heap. Because handles are being used instead of actual pointers, all the collector has to do when it makes this shift is update all the handles. The application variables can remain untouched.
This process is illustrated in Figure 5.14.
Real-Time Behavior
With my mark-sweep collector, there was a noticeable decrease in execution time when the frequency of garbage collection was decreased. This might lead you to think that the best way to speed up a garbage collector is to delay collection until the last possible moment. As it turns out, this approach isn't a good idea because it can force a garbage collector to perform reclamation when the application urgently needs allocation the most. A memory-starved application can be forced to wait for storage space, which it desperately needs, while the garbage collector chugs away.
At the other end of the spectrum, there is the idea that you could speed a garbage collector up by allowing it to do a small amount of work during each allocation. This tactic is known as incremental garbage collection, and you got a taste of it when you observed the reference counting collector.
Incremental garbage collection works very nicely in practice because the constant heap maintenance that an incremental manager performs provides enough breathing room for requests to be satisfied in real time.
I like to think of garbage collection as the inspection of a Marine Corps barracks at Parris Island. If you wait until the last minute to clean things up, break out some jelly because you are toast. The drill instructor is going to come storming in and read you the riot act for all of the details that you couldn't possibly have attended to in the 30 minutes you had to get your bunk in order. On the other hand, if you constantly keep your area neat and clean, it will be much easier to deal with the drill instructor when he arrives.
Garbage collection is the same way. Demanding allocations tend to occur when the memory manager can least afford to service them. It is Murphy's Law, plain and simple. By keeping the heap relatively organized at all times, those expensive allocation requests will not hurt as much. It will also allow the memory manager to guarantee service pauses within a certain time range.
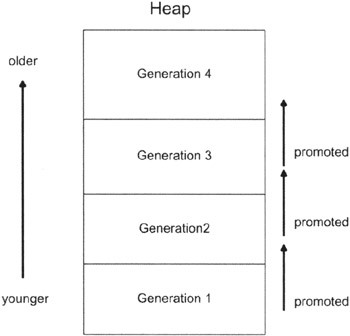
Life Span Characteristics
Most applications have a set of objects that exist for the life span of an application and another set of temporal objects that blink in and out of existence. It makes sense, then, to have different storage areas and algorithms to deal with memory blocks that have different life spans. This tactic is known as generational garbage collection.
A generational memory manager breaks the heap into regions based on life span, known as generations (see Figure 5.15). The memory manager begins by allocating memory from the youngest generation.
When the youngest generation is exhausted, the memory manager will initiate garbage collection. Those memory blocks that survive collection over the course of several iterations will be moved to the next older generation. As this process continues, the memory blocks that survive will be filtered up to the older generations. Each time a generation's storage space is exhausted, the memory manager will garbage collect that generation and all the younger generations.
Most of the garbage collection and allocation activity ends up occurring in the younger storage areas of the heap. This leaves the older memory blocks in relative tranquility. It's like a college physics department: The young guys do all the work, and the old guys hang out and polish their awards.
This means that because activity in the older generations is limited, slower algorithms that waste less memory can be used to track memory blocks in the older generations. On the other hand, speed should be the determining factor when choosing an algorithm to allocate and track memory in the younger generations.
Multithreaded Support
All the implementations presented in this book have been single-threaded; this was a conscious decision on my part in order to keep things simple so that you could focus on the main ideas. The handicap of using a single-threaded garbage collection scheme is that reclamation is done on the critical path of execution.
I think that most garbage collection implementations assume a multithreaded environment where there will be plenty of CPU cycles off the critical path. This allows the garbage collector to supposedly do its thing as a background thread while the rest of the program chugs merrily along. If you are interested in building a commercial-quality garbage collector, I would recommend that you consider a multithreaded approach.
There are two sides to every coin; such is the case with using threads. The first sacrifice you will typically make is portability. Every vendor seems to supply their own specially tweaked version, and you can expect to dedicate a significant portion of your development time porting your code to work on different operating systems.
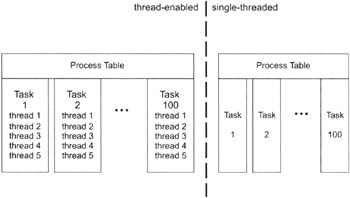
Another pitfall of using threads is that it does not necessarily guarantee high performance. For example, let us assume you have a thread-enabled operating system that can perform thread switches at the kernel level so that each process table entry has fields to support one or more threads. Let us also assume that there are 100 processes running, and each process has five active threads (see Figure 5.16).
This places us in a situation where there are 500 distinct executing threads. Now imagine an operating system, which is not thread-enabled, that just has 100 running processes. On the thread-enabled operating system, a thread will have to potentially wait in line behind 499 other threads before it gets its chance to execute. On the thread-disabled machine, a process only has to share the processor with 99 other tasks, and each execution path will get a larger share of the processor's attention.
Is the thread-enabled system necessarily faster, or does it just give a programmer the ability to load down the operating system so that each thread actually gets less processor time?
| Note |
I will admit that this is a somewhat stilted scenario. A fair comparison would be to compare an operating system scheduling 500 threads against an operating system scheduling 500 single-threaded tasks. In this scenario, the thread-enabled operating system would offer better performance.
|
My point is not that multithreading hurts performance. In fact, using threads can usually boost performance due to the lower relative overhead of the associated context switch. My point is that multithreading does not guarantee high performance (ha ha — always read the fine print). In a production environment, actual performance often has more to do with the hardware that an application is deployed on and the current load of tasks that the kernel is servicing than the architecture of a particular application. Performance has many independent variables, and an application's thread model is just one of those variables.
Chapter 6: Miscellaneous Topics
Suballocators
Normally, memory managers have to suffer through the slings and arrows of not knowing when or how much memory will be requested by an application. There are, however, some circumstances where you will know in advance how large an application's memory requests will be or how many there will be. If this is the case, you can construct a dedicated memory manager known as a suballocator to handle memory requests and reap tremendous performance gains.
A suballocator is an allocator that is built on top of another allocator. An example of where suballocators could be utilized is in a compiler. Specifically, one of the primary duties of a compiler is to build a symbol table. Symbol tables are memory-resident databases that serve as a repository for application data. They are typically built using a set of fixed-size structures. The fact that a symbol table's components are all fixed in size makes a compiler fertile ground for the inclusion of a suballocator. Instead of calling malloc() to allocate symbol table objects, you can allocate a large pool of memory and use a suballocator to allocate symbol table objects from that pool.
| Note |
In a sense, all of the memory management implementations in this book are suballocators because they are built on top of the Window's HeapAlloc() function. Traditionally, however, when someone is talking about a suballocator, they are talking about a special-purpose application component that is implemented by the programmer and based on existing services provided by application libraries (like malloc() and free()).
|
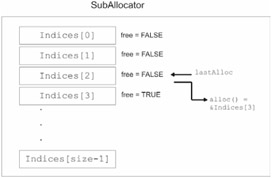
To give you an example of how well suballocators function, I am going to offer a brief example. The following SubAllocator class manages a number of fixed-sized Indices structures in a list format. Each structure has a field called FREE to indicate if it has been allocated. When a request for a structure is made via the allocate() member function, the SubAllocator class will look for the first free structure in its list and return the address of that structure. To avoid having to traverse the entire list each time a request is made, a place marker named lastAlloc is used to keep track of where the last allocation was performed.
The basic mechanism involved in allocating an Indices structure is displayed in Figure 6.1.
The following source code implements the SubAllocator class and a small test driver:
When this application is executed, the following output is produced:
The allocation and release of 1,024 Indices structures took less than a millisecond. This is obviously much faster than anything we have looked at so far.
The moral of this story: If you have predictable application behavior, you can tailor a memory manager to exploit that predictability and derive significant performance gains.
Monolithic Versus Microkernel Architectures
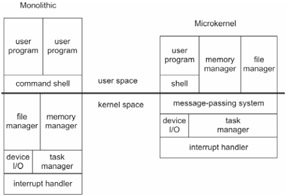
All of the operating systems that we looked at in Chapter 2 were monolithic, which is to say that all the components of the operating system (the task scheduler, the memory manager, the file system manager, and the device drivers) exist in a common address space and everything executes in kernel mode (at privilege level 0). In other words, a monolithic operating system behaves like one big program. UNIX, Linux, MMURTL, DOS, and Windows are all monolithic operating systems.
Another approach to constructing an operating system is to use a microkernel design. With a microkernel operating system, only a small portion of the operating system functions in kernel mode. Typically, this includes task scheduling, interrupt handling, low-level device drivers, and a message-passing subsystem to provide interprocess communication primitives. The rest of the operating system components, like the memory manager and the file system manager, run as separate tasks in user space and communicate with each other using the kernel's message passing facilities. MINIX, Mach, and Chorus are examples of microkernel operating systems.
The difference between monolithic and microkernel architectures is displayed in Figure 6.2.
The researchers supporting the microkernel school of thought claim that the enforcement of modular operating system components provides a cleaner set of interfaces. This characteristic, in turn, makes it easier to maintain and modify an operating system. Operating systems are often judged with regard to how well they accommodate change. The operating systems that tend to survive are the ones that are easy to extend and enhance. By allowing core components to be separate tasks running at user level, different implementations can be switched in and out very easily.
Furthermore, microkernel proponents also claim that their approach provides better system stability. For example, if the memory manager is faced with a terminal error, instead of bringing down the entire operating system the memory management user task exists. This gives the microkernel the opportunity to recover gracefully from what might ordinarily be a disaster.
In the early 1990s, Torvalds and Tanenbaum became involved in a flame war. This well-known debate was initiated by Tanenbaum when he posted a message to comp.os.minix entitled "Linux is obsolete." In his original message, Tanenbaum mentioned:
"Don't get me wrong, I am not unhappy with LINUX. It will get all the people who want to turn MINIX in BSD UNIX off my back. But in all honesty, I would suggest that people who want a **MODERN** "free" OS look around for a microkernel-based, portable OS, like maybe GNU or something like that."
"Modern" OS — my goodness, that sounds a tad arrogant to me.
The resulting flame-fest progressed over several messages, each side attacking the other's logic and world view. Although Tanenbaum did raise some interesting points in his debate with Torvalds, history sides with Torvalds. MINIX has been relegated to a footnote in history and Linux has a user base of millions.
As I stated in Chapter 1, speed rules the commercial arena. Darwin's laws definitely apply to the software arena. Those operating systems that possess attributes that make them useful in production environments will be the ones that survive. The successful operating systems that are currently the big money makers for software vendors, like Microsoft, HP, Sun, and IBM, are monolithic (i.e., Windows, HP-UX, Solaris, and zOS).
One problem that plagues microkernel implementations is relatively poor performance. The message-passing layer that connects different operating system components introduces an extra layer of machine instructions. The machine instruction overhead introduced by the message-passing subsystem manifests itself as additional execution time. In a monolithic system, if a kernel component needs to talk to another component, it can make direct function calls instead of going through a third party.
| Note |
A classic example of the performance hit associated with pushing functionality to user space is X Windows. Linux does not have a significant amount of user-interface code in the kernel. This affords Linux a modicum of flexibility because the kernel has not committed itself to any particular GUI implementation. Linux can run GNOME, KDE, and a number of other GUIs. The problem, however, is that everything happens in user space, and this entails a nasty performance hit. Windows, on the other hand, has pushed a hefty amount of the GUI management code down to the kernel, where interaction with hardware is more expedient. Specifically, most of Windows GUI code is contained in the Win32k.sys kernel mode device driver.
|
Security problems are another issue with microkernel designs. Because core operating system components exist in user space, they have less protection than the kernel. I imagine that it would be possible to subvert a given system manager by creating a duplicate task that hijacks the message stream between the kernel and the existing component. Microkernel advocates may also claim that their designs are more stable, but I doubt that an operating system could survive if its memory management unit called it quits.
Finally, most production operating system implementations are huge. According to a July 29, 1996, Wall Street Journal article, Windows NT 4.0 consists of over 16.5 million lines of code. I would speculate that Windows XP may very well have doubled that number. With a code base in the millions, I am not sure if the organizational benefits provided by a microkernel design would really make that much of a difference. On this scale, internal conventions and disciplined engineering would probably have a greater impact on maintainability.
In other words, it is not exactly what you are building but how you build it that makes the difference between success and failure.
Table 6.1 presents a comparison of monolithic and microkernel design approaches.
Table 6.1
| |
Monolithic
|
Microkernel
|
|
Maintainability
|
complicated interaction
|
marginally better
|
|
Stability
|
kernel errors lead to crash
|
questionable isolation of errors
|
|
Performance
|
faster
|
slower, messaging overhead
|
|
Security
|
everything in kernel mode
|
core components in user mode
|
Closing Thoughts
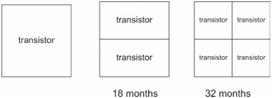
In 1965, an Intel Corporation co-founder named Gordon Moore suggested that the number of transistors in a processor would double every 18 months. This rule of thumb became known as Moore's Law. Moore's Law implies that the linear dimensions of a transistor are cut in half every three years (see Figure 6.3).
A micrometer is one-millionth of a meter:
1 μm = 10-6m
The anthrax bacterium is 1 to 6 micrometers in length. A human hair is 100 micrometers in diameter. Most chips today have transistors that possess sub-micron dimensions.
A nanometer is one-thousandth of a micrometer:
1 nm = 10-9m
= 1/1000 μm
The diameter of a hydrogen atom, in its ground state, is roughly one-tenth of a nanometer.
Solid-state physicists will tell you that an electron needs a path of about three atoms wide to move from one point to another. If the path width gets any smaller, quantum mechanics takes hold and the electron stops behaving in a predictable manner.
In 1989, Intel released the 80486 processor. The 80486 had transistors whose linear dimensions were 1 micrometer. Using 1989 as a starting point, let's see how long Moore's Law will last before it hits the three-atom barrier.
Table 6.2
|
Year
|
Size
|
Processor
|
|
1989
|
1 micrometer
|
Intel 80486 (1 micrometer)
|
|
1992
|
0.5
| |
|
1995
|
0.25
|
Pentium Pro (.35 micrometers)
|
|
1998
|
0.125
| |
|
2001
|
0.0625
|
Pentium 4 (.18 micrometers)
|
|
2004
|
0.03125
| |
|
2007
|
0.015625
| |
|
2010
|
0.0078125
| |
|
2013
|
0.00390625
| |
|
2016
|
0.001953125
| |
|
2019
|
0.000976563
| |
|
2022
|
0.000488281
| |
According to Moore's Law, the length of a transistor will be about 4.88x10-10 meters by the year 2022. This corresponds to a path width that is roughly four hydrogen atoms across. As you can see from the third column, Intel has made valiant attempts at trying to keep up. However, nobody has really been able to sustain the pace set by Moore's Law. In 2001, Moore's Law says that we should have had transistors whose design rule was .06 micrometers. In 2001, Intel's top-of-the-line Pentium 4 had a design rule of .18 micrometers. Vendors that say they are staying abreast of Moore's Law are really cheating by making their chips larger. This tactic increases the total number of transistors, but it doesn't increase the transistor density per unit length.
Once the wall is hit, there is really nothing that we will be able to do (short of changing the laws of physics) to shrink transistors. The only way to increase the number of transistors in a processor will be to make the processor larger. The party will be over for the processor manufacturers. Hardware people will no longer be able to have their cake and eat it too. Businesses that want to increase the horsepower of their information systems may have to revert back to room-sized computers.
In the beginning, algorithms and the people who worked with them were valued highly because the hardware of the day was often inadequate for the problems that it faced. Take the Bendix G-15, for example, which had 2,160 words of magnetic drum memory in 1961. In order to squeeze every drop of performance out of a machine, you needed to be able to make efficient use of limited resources. Program size was typically the biggest concern. If instructions existed in more than one spot, they were consolidated into a procedure. This meant that the execution path of a task tended to spend a lot of time jumping around memory. I remember two Control Data engineers telling me about how they simulated an entire power grid in southern California using less than 16KB of memory.
| Note |
In 2002, with the advent of 256MB SDRAM chips and 512KB L2 caches, program size is not such a pressing concern. Program speed is the new focal issue. This has led to an inversion of programming techniques. Instead of placing each snippet of redundant code in its own function, developers have begun to deliberately insert redundant instructions. For example, inline functions can be used to avoid the overhead of setting up an activation record and jumping to another section of code.
|
When Moore's Law meets the laws of physics, the computer industry will once again be forced to look for better solutions that are purely software-based, primarily because all the other alternatives will be more expensive. One positive result of this is that the necessity to improve performance will drive the discovery of superior algorithms. Computer science researchers may see a new heyday.
The demise of Moore's Law may also herald the arrival of less desirable developments. Lest you forget, major technical advances, such as radar and nuclear energy, were first put to use as weapons of war. Potential abuse of technology has already surfaced, even in this decade. At Super Bowl XXXV, hundreds of people involuntarily took part in a virtual lineup performed by Face Recognition Software. Is there a reason why people who wish to watch a football game need to be treated like suspects in a criminal case? Why was the public only informed about the use of this software after the game had occurred?
This is just the beginning. Artificial intelligence programs will eventually be just as sophisticated and creative as humans. To a certain extent, they already are. In 1997, an IBM RS/6000 box named Deep Blue conquered the world chess champion, Garry Kasparov, in a six-game tournament. I was there when it happened (well, sort of). I was huddled with an Intel 80486 the afternoon of the final game, reading a "live" transcript of the match via an IBM Java applet. For a more graphic example of AI progress, try playing against the bots of Id Software's Quake 3. You would be impressed with how wily and human those bots seem.
As the capabilities of hardware and software ramp upward, the surveillance that we saw at the Super Bowl will give way to something more insidious: behavior prediction and modification. The credit bureaus and various other quasi-governmental agencies already collect volumes of data on you. Imagine all of this data being fed into a computer that could consolidate and condense the information into some kind of elaborate behavioral matrix. If you can simulate someone's behavior, you can make statistical inferences about their future behavior. Furthermore, if you can predict what someone is going to do, you can also pre-empt their behavior in an effort to control them. There could be software built that less-than-scrupulous leaders could use to implement social engineering on a national scale. Indoctrination does not have to assume the overt façade that Huxley or Bradbury depicted. It can be streamed in sub-liminally through a number of seemingly innocuous channels.
"We are the middle children of history, raised by television to believe that someday we'll be millionaires and movie stars and rock stars, but we won't."
— Tyler Durden
As time passes, these kinds of issues will present themselves. It is our responsibility to identify them and take constructive action. The problem with this is that the capacity to recognize manipulation does not seem, to me, to be a highly valued trait. The ability to think independently is not something that I was taught in high school. If anything, most public schools present a sanitized version of civic education. Not that this matters much, but most people don't start asking questions until the world stops making sense.
Nevertheless, if we sit idle while the thought police install their telescreens, we may end up like Charles Forbin, slaves to a massive and well-hidden machine.
"In time, you will come to regard me with not only awe and respect, but love."
— Colossus, speaking to Charles Forbin in Colossus: The Forbin Project (1969)
|
|

 LINUX
LINUX